John Koetsier is a journalist and analyst. He's a senior contributor at Forbes and hosts our Growth Masterminds podcast as well as the TechFirst podcast. At Singular, he serves as VP, Insights.
I’m fascinated by how the discussion around mobile ad fraud has somehow left the building, like a digital Elvis, as our conversations turn to SKAN and privacy and all the challenges of modern marketing measurement. Did mobile ad fraud disappear when Apple introduced App Track Transparency? Did the bad guys decide they had enough illicit cash and go lie on a beach in the Caribbean?
Probably not.
(OK, let me be more direct: certainly not.)
So let’s take a few moments to understand what you need to protect yourself against fraud on Android (just as bad as ever) and iOS (still filled with minefields you need to navigate). And to understand why, if you’re relying on probabilistic attribution via fingerprinting, you’re taking a major, major risk with regard to mobile ad fraud.
Meet the new boss, same as the old boss
Billion-dollar bonanzas from taking credit for clicks, conversions, and installs you didn’t facilitate didn’t just automatically disappear. Fraudsters are still out there, and they’re still gunning for your ad dollars.
And while your best defense might be a keen eye on ROI and ROAS and channels that perform, if someone’s taking credit for another’s success, it might not be immediately obvious on the surface.
That’s why Singular offers over 50 different fraud detection methods, including:
Android install validation
iOS install receipt validation
Android click injection/hijacking protection
Android organic poaching protection
Time-to-install outlier detection
Geo-bleed detection
Hyper-engagement
Blacklisted IPs
Deterministic detection for Android-based device ID reset fraud
Plus, of course, a huge amount of pre-attribution fraud prevention, such as rejection of fraudulent impressions and clicks so marketers and ad partners don’t have to have uncomfortable conversations about billings, and custom rules so marketers can block what they don’t want before it even starts.
That’s all table stakes for competing today, especially on Android. But it’s essential for ensuring your ad dollars do the work you’re intending them to do.
Start with the basics: fraud rules you need to have active
For starters, Singular customer service manager Daniel Camacho says he would definitely recommend starting off with some of the easier fraud rules:
Android Organic Poaching Detected
iOS Receipt Validation Not Valid
Android Click Injection Detected
Android Install Validation Not Valid
The validations are basically receipts from Apple and Google indicating an install was validated through their system. They’re not 100% foolproof, but they’re good evidence that an install is real.
For organic poaching and click injection, it’s relatively simple for Singular to detect something is clearly suspicious. Real people don’t click on multiple ads on multiple publishers, websites, or apps within a minute … why would you click on an ad for the same app you’re already downloading? So these are simple ways to start.
Important note:
If you’re looking at specific partners, however, start these rules by marking installs as suspicious, not as immediately rejected. That way you can run a week’s worth of data and check the results. Does it look and feel right? If so, go ahead and mark them as rejected. Is the overall quantity more than you anticipated, and more than seems right based on your in-app data? Then it’s time for a little more investigation.
The last thing you want to do, Camacho says, is set up your fraud rules to block all suspicious installs and then the next day your install numbers are down 60%. This can happen and literally has. You first want to get more data on activity, so marking installs that don’t pass your rules as suspicious allows you to work from there. This is especially important for apps, where click-to-install times, can take a while.
Also: check OS and app versions
It’s also basic but you’d be surprised how many high-volume pro mobile marketers aren’t doing it: check the OS and app version for installs.
Example:
Set up your fraud rules to mark installs from excessively old OS versions as suspicious. You don’t have to reject these, but you want to be aware of what’s going on. If you see a spike in installs from an unusually old mobile operating system, that’s a signal to pay attention to. Especially, of course, if it’s largely coming from one single ad partner.
If you see a really fast click-to-install time for these installs, consider flipping that suspicious flag to a rejected one.
Also, check for app versions.
Most people on both iOS and Android get their apps updated frequently and regularly without having to lift a finger, especially if they’re on the latest version of their particular mobile operating system. Too many installs from older versions of your app is a signal that something might be off: hackers may have grabbed an older version of your app and could be using that in a virtual bot farm.
And, of course, kosher user acquisition campaigns are targeting the latest version of your app, not some version you released last year.
Note: fingerprinting on iOS opens up a significant ad fraud vulnerability
Apple’s ATT and SKAdNetwork contain mechanisms for validating app installs. That doesn’t make them fraud-free, but it does add significant safeguards. However, SKAN does not validate conversions, so that is something to be aware of.
But for those who are bypassing Apple’s guidelines and running probabilistic attribution based on fingerprinting, watch out.
One form of fraud you can expect to encounter is “probabilistic fraud,” says Singular product manager Omri Barak. Fingerprinting is essentially based on IP and OS versions, which especially on iOS makes it not very unique. It’s actually fairly low-lift for bad buys to create relevant clicks that look right and try to steal the app install attribution.
In fact, it’s much easier than it used to be: you don’t have to create a click with a specific IDFA to get the attribution.
One case we saw with a new client in doing a review of their previous attribution data fit this category. Every install for a campaign was attributed to a certain partner … which was suspicious to say the least. Fortunately, it was easily traceable as they all used a specific deferred deep link.
This is, essentially, yet another reason not to use fingerprinting on iOS. As if you needed another one, since apps that do these risk penalties from Apple.
The good news: full transparency
The good news is that in Singular’s reporting, you get full transparency of all ad fraud results in three categories:
Rejected (ad fraud was detected and prevented)
Suspicious (ad fraud potentially found and highlighted)
Protected (attempted ad fraud, with sources and details)
All of which makes ensuring your ad dollars don’t get sent to fraudsters significantly easier. Get more details here.
Behavioral targeting is mostly gone on iOS. It’ll soon be significantly challenged on Android as GAID dies a savage death and Privacy Sandbox for Android rises from its ashes. What we’re left with is contextual targeting … is the mobile app advertising sky falling?
We recently had Remerge CEO Pan Katsukis on the Growth Masterminds podcast to chat about contextual targeting in mobile advertising. The question: how good can this get? The unspoken fear: how bad is it really?
Hit play on the video above to kick off the convo, and keep scrolling to get just a few of the highlights.
And, before we get started, a quick definition of terms as they’re typically used in the mobile marketing ecosystem:
Behavioral targeting:targeting ads to people based on what they’ve previously done in other apps:
Usually requires some kind of tracking mechanism
Generally has significant privacy concerns
Essentially impossible now on iOS with App Tracking Transparency
Can potentially be done in a privacy-safe way (Privacy Sandbox for Android is one attempt)
Typically can be used to target narrower groups of people with very specific interests
Contextual targeting: targeting ads to people based on their current context:
Generally requires knowing what app a person is in right now, or at least what kind of app
Generally regarded as much more privacy-safe than behavioral targeting
Typically better for broader targeting of larger groups of people with general interests
First: contextual targeting isn’t just simple context
The first thing to keep in mind is that context isn’t just simple.
Modern contextual targeting in mobile apps often isn’t like contextual targeting on the web. On the web, Google or some other ad network has spidered a web page or video, knows what content lives on it or in it, semantically understands what that content is about, and targets a relevant ad to an audience that’s generally interested in that content. The hope, of course, is that a person who finds Sportfishing in Alaska interesting will also be interested in ads for fishing flies, or rods, or guided trips, cabins near good fishing streams, or fishy wall clocks with Amazon Alexa inside.
(Don’t ask.)
There’s some of that on mobile as well, but much of that kind of context comes from the app itself or the app category. (Note: some adtech platforms like Inmobi can potentially “read” app content and use that as insight for contextual targeting, assuming the right SDKs with the right privileges are in place.)
But many key aspects of in-app contextual targeting come from less visible and obvious data points.
“In the end it can be any signal or attribute that we know about the current situation of the user … the simplest one is what time is the device right now,” says Katsukis. “What time of the week is it right now? What type of app are they using … how long have they been using it? So anything else which comes from the publisher and the app itself, like the app rating, you can find out: the category the app is … that gives you some information and understanding like what the user is up to right now, what they’re interested in, where they’re engaging.”
In fact contextual advertising can take advantage of up to 100 signals, Katsukis says, including details like:
WiFi or cellular connection
Bids/pricing information from the ad network
Rough/coarse location
Device information (brand, OS version, device version)
And this can be used in order to design relevant offers and drive good creative to the user, providing insights to whether they’re at home or office or on the go, where they are in the world generally — example: in Germany during Oktoberfest — and potentially demographically-relevant information such as socioeconomic status, based on device type and extrapolated cost.
Add them all up, and you’ve got data that can be incredibly useful, particularly in certain verticals. My stomach, for instance, doesn’t care what app I’m in when 6PM hits and it feels empty. Match it with other privacy-safe data like weather, calendar, and events, and you add relevancy step by step by step, and maybe get a new Uber Eats customer at the same time.
This really works for some verticals, Katsukis says.
But the bad news is that it’s significantly challenging to find niche, tightly-targeted audiences at an affordable price via contextual advertising. Hence the challenges that D2C (direct to consumer) is having right now in targeting potential customers, and the challenges that some — not all — mobile games are also experiencing.
Second, you need some technology
This probably goes without saying, but you’re not going to be great at contextual targeting by just looking at one or two factors.
The good news is there’s a lot of data available from multiple privacy-safe sources:
Device data
App/publisher data
Adtech platform data
Environmental data (weather/calendar/events)
The bad news is that you’re not going to be able to analyze dozens or scores of device-derived, app-derived, adtech platform-derived, and environment data like weather and events manually or in real-time without some serious tech.
“You can’t really get far with contextual if you do it all manually,” Katsukis says. “The case [of, for examples] let’s target everyone at 7:00 PM on a Friday after work … so they order food. That’s an easy example, but if you want to scale that [and] be really good nowadays you can leverage machine learning to look at all the history, everything that has been done, and even for that, use the ID inventory to try to understand … what’s working and try to make connections with the different other signals you see there.”
In other words, get sophisticated. Build some models; do some training. Use IDFAs when you have them (and GAIDs) when you do. Leverage them to measure your contextual advertising effectiveness and get better and better at it. (Or: get your adtech vendors to do all this work.)
One thing is for sure. You won’t be the only one testing:
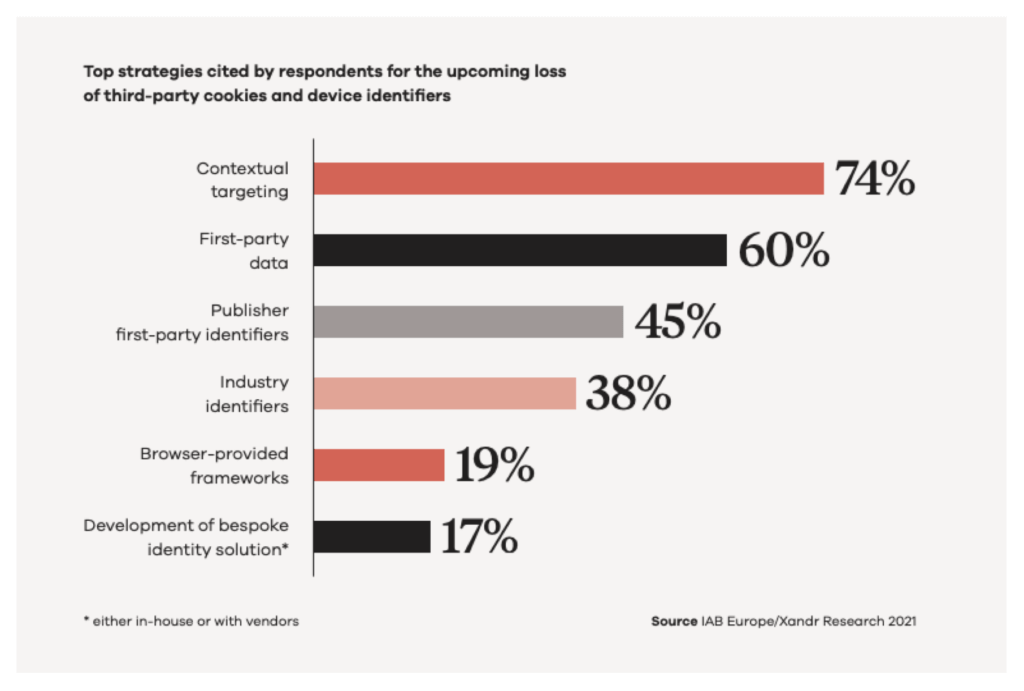
According to the IAB, 74% of marketers are using contextual data to improve their advertising post-device ID and post third-party cookies on the web (of course, the third-party cookie just got a new lease on life from Google). That’s more than those leveraging first-party data (60%) and more than those who are leaning on (and paying for) publishers to do their targeting for them in the black box of their platforms (45%).
Exploit the 50%-off contextual advertising discount
One benefit: you’re getting a contextual advertising discount. A significant discount.
“Right now the inventory when there is no ID is still — and I looked it up just today — 53% cheaper,” Katsukis says. “That’s obviously an opportunity for an advertiser to tap into and just figure out, okay: can I get as far with contextual only without an ID, while still having the opportunity to bid 53% lower … as there’s not much competition?”
The clear opportunity is that if you can get even half as good results with contextual advertising as you did with behavioral targeting, it’s a break-even proposition. And if you can improve just a little bit on that … it’s all gravy.
That’s a big if, of course.
Niche apps with specific requirements for players — and a strong desire to hunt whales — will find it toughest. Larger apps and brands with more generic or universally appealing offers and value propositions will have an easier time using somewhat mass media marketing tactics in a digital, contextually targeted environment.
If today’s AI is so smart, why doesn’t it do more of your work? Especially with SKAN conversion models, which are notoriously challenging to get right.
Welcome to optimized conversion models for SKAdNetwork from Singular.
Why do you need optimized conversion models for SKAN?
35% of apps are not using the most optimized model
20% of apps are using a significantly inefficient model
Using a poorly optimized model costs you missing data … for 7-day revenue, sure but even for 1-day revenue (!!!)
Singular’s optimized SKAN conversion models technology has found up to 60% better conversion models for some clients
And … it’s all automated
Artificial intelligence (or, as I like to call it, the machine doing your work for you) should actually be useful. After all, the Industrial Revolution was 200 years ago. The Intelligence Revolution, Forbes says, is here. Shouldn’t your technology do more to help, especially with something as challenging, finicky, and hard-to-figure-out as iOS attribution via Apple’s SKAN framework?
SKAN conversion models that work: it all starts with accurate data
You already know: data is hard to get under SKAdNetwork.
First off, full, accurate, and complete data is literally impossible to get, thanks to privacy thresholds and the single postback that SKAN 3 offers, or the 3 that SKAN 4 will offer. So you need SKAN Advanced Analytics to model missing data, enrich insights with data from privacy-safe sources, make revenue predictions, and — bottom line — wring every last ounce of value out of the data you actually do receive.
But you also need to ensure that the baseline data SKAN does provide is the best, richest, and most accurate it can possibly be.
And that’s where optimized SKAN conversion models come in.
“The key component to getting accurate data, whether it’s revenue or whether it’s modeled revenue, is having the correct model,” says Singular product manager Evyatar Ram in a recent Growth Masterminds podcast. “Everyone understands that for modeled revenue, if you’re trying to get 7 day predictive, you need a super optimized model. But I think the interesting thing here is that even if you’re just trying to get accurate 1 day revenue that’s fully encoded in SKAdNetwork, even for that use case selecting the right conversion model impacts the accuracy of the number that you will get at the end of the day.”
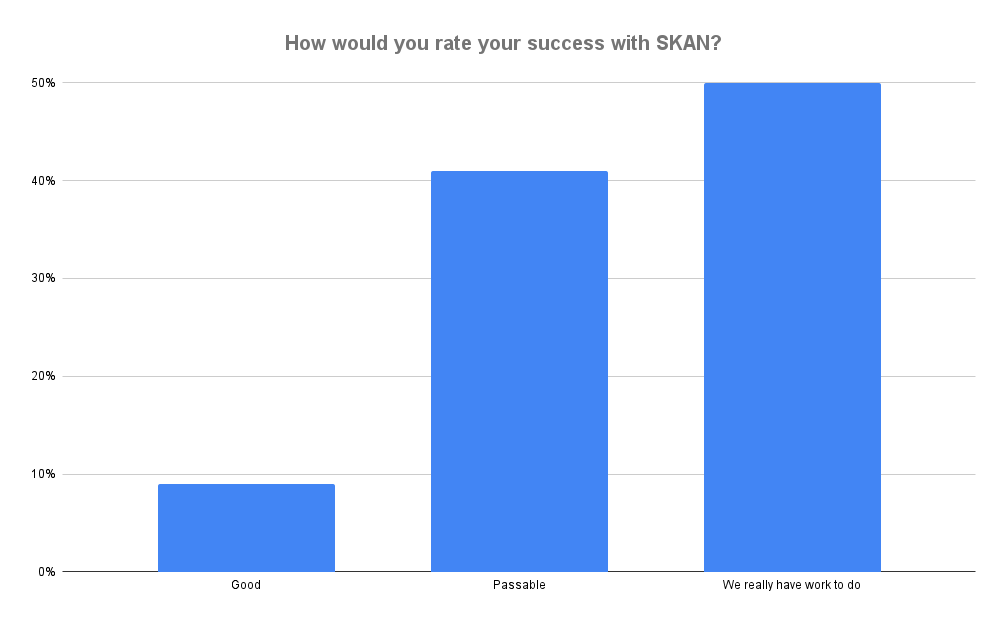
We’ve already seen that only 9% of mobile marketers think they have SKAN figured out.
What if you have the wrong model?
What if there’s a more optimized model that captures more data?
What if you could get greater accuracy?
And, if you have the right model, the most optimized model with the highest level of accuracy possible … how might that improve campaign optimization, spend allocation, partner selection, creative optimization, and all the other things that allow mobile marketers to deliver outsized growth?
But perhaps the more important question is: how would you know? Or even: could you find out if you’re actually using the most optimal model without a long, difficult, and expensive (opportunity cost!) round of testing?
Cue the machine.
Automatic always-on background SKAN conversion model optimization
Singular has developed technology to rank SKAN conversion models for effectiveness: their ability to deliver accurate data, Ram says. With always-on SKAN conversion model optimization checking in the background, you’ll now get a notification if there’s potentially a more accurate model to try.
“For every app out there, we actually check the data once a week,” Ram says. “So every week we’re going to see if you have a better model or not. We will look at our most optimal model, and we’ll look at what model the customer already has … if we think that our model is significantly better than the one that you might be using, we’ll recommend it.”
In other words, if it’s 2% better, the technology won’t waste your time.
But if there’s a 20% or 40% or 60% better option, you’ll get a notification.
The benefit here is that …
as the world changes (economy, politics, pandemic)
as your app changes (UX, UI, monetization, capability, onboarding)
as your marketing changes (partners, creative, cohorts, offers, spend, bids)
… you don’t have to worry that your conversion model for getting attribution and conversion data back from SKAdNetwork is out of date, wrong, or unoptimized.
You’ll be getting automated checks on it weekly. The machine has your back.
SKAN 4: automated optimization will be even more important
Automated optimization technology will be even more important there, because you’ll potentially have up to 4 separate conversion models for SKAN operational at any given time:
Full granularity model if you surpass crowd anonymity thresholds for postback 1
Coarse conversion model for postback 1 if you don’t surpass crowd anonymity thresholds
Coarse conversion model for postback 2
Coarse conversion model for postback 3
“SKAN 4 does a lot of really great things, but in some respects, managing your SKAN set-up in SKAN 4 might become more complex,” Ram says.
Ram is being diplomatic. SKAN 4 simply will be more complex to implement: there’s more to instrument, and there’s more to analyze. Technology like this, however, will help marketers let MMPs like Singular do all the heavy lifting.
Revenue models first, mixed models next
There is a caveat here. Optimized conversion models for SKAN is initially only available for revenue models.
There are super-useful mixed conversion models that combine multiple factors like revenue, events, engagement, or funnel progression. The optimized conversion model technology isn’t available for that yet, but it is coming.
“That’s definitely something that’s on our roadmap and hopefully we’ll have some things to share soon,” Ram says.
Optimized SKAN models matter
It can’t come soon enough.
As I mentioned off the top, 35% of apps Singular has checked are NOT using the most optimized SKAN conversion models, and 20% are using highly inefficient models. That means 1 in 3 apps could get better, and 1 in 5 apps are really missing out on data accuracy, severely impairing their ability to advertise, market, and grow effectively.
Plus, for some apps, Singular’s new optimized conversion models technology for SKAN has found a 60% better model. That’s not small. That’s not insignificant.
That’s simply game-changing.
“At the end of the day, it’ll help you make better decisions,” Ram says.
Subscribe to Growth Masterminds
We talk to industry leaders about key changes happening in the mobile adtech industry.
It’s a downer if you owned crypto. A disaster if you invested in NFTs. A cautionary tale for those who always had some reservations. And yet another chapter in the history of economics for those who are students of business history from the Dutch tulip bulb craze in the 1600s to the dot-com bomb in early 2000s. But whichever segment you fall into, the crypto crash might have been the very best thing to happen to web3 games and apps.
On November 6th, 2021, Ethereum hit $4,811.90 US
On November 10, Bitcoin hit $68,789.63
In December, NFT sales hit over 100,000 per day, with a total value nearing $200 million
Today Bitcoin is in the low $20,000 range. Ethereum is just over $1500. And NFT sales have dropped by over half.
That sounds like it would be bad for web3 apps and games. And let’s be honest, it isn’t amazing. Installs of web3 apps — at least wallets and NFT collectible apps — dropped significantly.
But some of the top experts in web3, blockchain, play-to-own, and collectible space say that actually, the crash wasn’t all bad. In fact, it might just have been a much-needed slap in the face that will ignite real innovation.
Web3 games and apps: next hot thing, or hot air?
We recently hosted a webinar on web3 apps and games with guests from Mythical Games, The Sandbox, Upptic, and Appvertiser. The goal: pull back the curtain on web3, identify what it means to be a web3 game or app, and share best practices for marketing web3 experiences on mobile devices.
Panelists included:
Anya Shapina, Head of Performance at Sandbox, a decentralized and open metaverse where people own, create, and monetize their assets and experiences on the Ethereum blockchain.
Daniel Lopez, VP, Growth Marketing at Mythical Games, which offers free-to-play and play-to-own games on the Mythical platform, and believes that ownership of digital assets is the future of games.
Warren Woodward, Co-Founder & CGO at Upptic, which is a gaming growth tech and services company whose partners include Axie Infinity and Kabam and whose team brings over 50M new players annually into the games they support.
Hagop Hagopian, Founder & CEO at Appvertiser, which manages a portfolio of over $500MM in ad spend.
No one disputes that web3, blockchain, and crypto has/had its share of grifters. The crypto crash wipes the slate a little cleaner for all the remaining web3 games and apps.
“It clears out the space. It gives us clarity. A lot of the projects that had no substance and had truly bad products are just going away and making room for better projects, for more sustainable, good games,” says Anya Shapina. “Communities are getting healthier and less hype driven. And what I also like is that the price points for entry [and] NFT prices are coming down, making it more affordable and easier for regular people to join the space.”
Less hype in web3 sounds like a prima facie good thing.
Now, perhaps, it’s time to get to work.
“The bubble has certainly popped,” says Daniel Lopez. “But, you know, markets ebb and flow. Things come and go. And we lived the hype for a little while. It was great. Now it’s time to get to work.”
Markets do ebb and flow. And the types of people that are just out to make a quick buck — whether or not it requires a good product or a good user experience — are precisely those that are attracted to super-hyped ecosystems. You know the type on LinkedIn: they were social media experts, then mobile experts, then crypto experts, and now they’re looking for the next new thing to be an insta-expert in.
The crash cleared those out, says Warren Woodward.
“Now that we’re past this really mania-speculation phase, it really does lead to a correction … if you’re still here if you’re building something, you’re probably building something because you value what the technology can bring to the table, not because you’re trying to make a quick few million bucks,” says Woodward. “So I’m quite bullish on just kind of like the reduction of noise afforded for us in this current dip.”
While few of us would say no to a quick few million bucks (!!!) the point is valid: for a healthy and viable ecosystem, we need to see web3 apps and games that do interesting things, provide real value, entertain people, and have a great user experience. We don’t need yet another randomly generated NFT collection, we need real spaces for creation, recreation, utility, and purpose.
So … how do you grow web3 games and apps?
It’s not easy and it’s not guaranteed, but there’s a recognized playbook for growing … shall I say traditional … apps and games. It involves targeting, ads, campaign optimization, ASO, SEO, creative optimization, and a lot of cash. (A great game or app experience is pretty much a prerequisite as well, and a bit of virality and influencer marketing doesn’t hurt either.)
But for web3?
Things are somewhat different.
First off, you have to understand who you’re targeting.
“Our marketing technique and our approach has to be completely differentiated,” says Shapina. “We don’t want to target a web3 crypto native the same way as a completely mainstream user, or a brand fan, or a person who has millions of dollars in their wallet account versus somebody who has just created the wallet account for the first time. They require a different marketing approach, different user journeys, and yeah, different onboarding experiences as well.”
Once you’ve identified that and built a campaign around your designated demographic, then it gets interesting. Part of how you market web3 games and apps is very different than typical games and apps, and part is very aligned.
“Early in the lifecycle, a lot of web3 projects just grow through community, through AMAs on Discord, says Shapiro. “Discord and Twitter is everything, [plus] sometimes Telegram … later in the lifecycle traditional marketing techniques and performance marketing become relevant as well.”
The first part of that answer has always been challenging to me personally, because you continually hear “it’s the community, it’s the community,” when we talk about growth in crypto, blockchain, NFT, and other web3 projects. Offloading the responsibility for growth onto a community is a challenging thing, especially if you’re brand new in the space and don’t … actually … have … a community.
What do you do then?
Growing from a million to 2 million fans is one thing. Growing from zero to a few thousand … that’s a substantially different challenge, and in many ways much harder because there’s no momentum. The ball isn’t rolling downhill.
How you beat the zero to one problem
So how do you start when you have nothing?
Borrow someone else’s community.
“As a founder, you are there doing endless AMAs,” Shapina says. “And partnerships too, right? Like you are actually doing AMAs with other communities. You get members from other adjacent communities into yours.”
And, you just do the work. Get on Twitter. Get on Discord. Get on Telegram. Connect with groups that might have an interest in the game or app you’re developing. Connect with influencers who might be able to galvanize a group around what you’re bringing to the table.
For early users who are native web3 people, this is essential. For those who aren’t web3 natives and devotees, there’s another strategy.
“There’s two distinct audiences,” says Woodward. “There’s that core, already in web3 audience. This group is highly educated, highly skeptical. They respond really poorly to ads. And then you have your mainstream player base, and there you can run more of a traditional growth marketing playbook that’s been established for years.”
Woodward, who started personally building web3 projects and partnering with people to educate himself on the space, realized early on he couldn’t use his usual playbook here.
Mobile marketers are probably more familiar with the second set of skills and actions: acquiring players and users much as they always have. For the first set, which might be different than they’ve ever done before, Woodward offers a tip: start by building a list of target communities that appear to have high overlap with your product. Build a list of similar offerings for higher tier, medium, and lower tiers, and then come to those communities offering added value.
The good news: your existing skills are still immensely valuable.
A lot of the marketing for web3 apps and games still follows very much of the traditional mobile growth model.
And in fact they mix well with preferred web3 strategies, with organic marketing and paid advertising complementing and accelerating each other.
“Hype-marketing approaches, exclusivity … fear of missing out … focusing on the brand collaboration … all of these are good ways to promote,” says Hagop Hagopian. “[But] don’t be afraid of using the web2 traditional book marketing approach … spend some money on marketing, get some user base, establish your core audience, and then let the ripple effect come into play. Create the network. When you acquire this base, the base will do the work, and they’re going to spread the word for you. They’re going to do the work while you get more investments and then reinvest and follow the same traditional model.”
The huge opportunity: bringing web2-style performance marketing tactics and measurement to web3-style marketing to take something that has been relatively bespoke and haphazard and make it measurable, scalable, and optimizable. (Hint: start with a combination of Singular Links, which work wherever any links work, attribution technologies, in-app events, and perhaps even some good old offer codes.)
Challenges remain, of course, and not just the crypto crash
Metrics in web3 are vastly different than traditional apps. You probably want to track connected wallets, number of transactions, currency volumes, NFT ownership levels and numbers, and marketplace metrics to monitor the health of trading and re-selling, all of which can lead to additional sources of revenue for your app or game.
Those can look very different than core metrics you would track in a traditional game or app. So there’s still a lot to figure out.
But as web3 marketers move from early adopters to the mainstream, they’re essentially forced to adopt mainstream methods of marketing, says Mythical Games growth marketing VP Daniel Lopez.
“I think that [existing] UA strategies and everything, it all plays extremely well to Web3,” Lopez says.. “With achieving efficiencies at scale, you have to be targeting more broader, more general audiences. Otherwise, you’re paying out the nose for hyper-targeted, small-user whitelisted type of individual segmentation and whatnot, and it just gets so expensive.”
All the old-school marketing strategies still matter, he adds: optimizing your funnel, lifecycle marketing, app store optimization, SEO … all the fundamentals.
And even older-school modes like co-branding are important.
“The partnerships really matter,” Lopez says. “We went and got a deal with the NFL for a reason. It’s a widely recognizable brand, breaks down those barriers to entry and gets people to click those ads and get us more effectiveness on our Google ad campaigns, right? Like, it’s just it’s all about playing the game.”
But all are important: new-school, old-school, and web3 techniques.
“[In the past] you could just be a mobile-first growth marketer and be okay with it,” Lopez adds. “Nowadays, that’s not good. You have to be a community marketer. You have to be a momentum-based marketer. You have to be a web page specialist. You have to be able to know everything.”
Mass adoption of web3: still on the horizon?
Mass adoption is still on the horizon, the panelists said. It’s not immediate, but it’s coming.
Wny?
Web3 is for creators.
“I’m looking at my 8-year-old son, who is playing the Sandbox,” says Shapina. “And his first inclination is he wants to make these things … in web3, users are creators … and you know, the new generation of kids is growing up as creators.”
Also, web3 games and web3 apps are getting better.
“The games themselves will be a huge driver of adoption, once they are fun enough and once they’re good enough as experiences,” Woodward adds.
Perhaps most importantly, web3 itself will disappear as a category as the technology just gets seamlessly integrated into app design and game construction. For example, if you scour world-creation/block party/game invention Blankos’ website or watch its video trailer, you won’t find the word “web3” or “crypto.”
It’s just about the game.
And yet you can own assets there. And buy NFTs.
“How many people know that they own NFTs when they’re playing Blankos?” says Lopez. “Because it’s very easy to get lost in the idea that this is just a great game. It’s a fun game. And these are just cool things that you can buy. Who knows if they’re even aware that it’s an NFT, and that they can buy on the secondary marketplace?”
Still, for many web 3 games and apps, mass adoption is not going to be immediate. It’s too hard, connecting a wallet is too scary, onboarding sucks, making a purchase requires 25 steps.
But that will all change. And we’ll know that’s happening when we essentially shut about it.
“We’re not going to talk about Web3 games,” Woodward says. “We’ll just stop talking about all this. And all of what Web3 games bring to the table for builders will essentially just kind of be in the background as other cool ways that you can build unique hooks or do cool things with your economy, or just be games.”
“And you know, no one is like, ‘Oh, I only play cloud computing games, or, you know, like AWS games.’ Once we stop talking about the technology … and we’re just enriching the gaming experience, that’s when, I think, we’re on the road to mainstream adoption.”
We do have a few short videos from Apple’s Worldwide Developer Conference and a few answers and hints from Apple in a few developer-focused Slack channels. Based on that, here’s what we know — or think we know — about SKAdNetwork version 4.
1. Crowd anonymity
In the past (errr, right now) we had privacy thresholds. Now Apple’s talking about crowd anonymity. The basic idea, of course, is simple: hiding individuals in crowds.
Crowd anonymity is the first thing Apple defined in the SKAN 4 WWDC session. It seems to be based on number of installs, based on what Apple shared, and that makes sense from what we know of SKAdNetwork today. In iOS 14.5 and later, the App Store asks Apple whether or not to censor at the time of install, not at the time of determining a conversion value, and we’re assuming that will continue.
It also makes sense because deciding crowd anonymity measurement impact at time of conversion value would be much more complicated.
2. Campaign ID expansion to 4 digits (and re-naming to Source ID)
SKAN 3 had a 100-campaign limit: 0 to 99, as mobile marketers know all too well. Now that Campaign ID field is changing to a Source ID field, and the range is going from 2 digits to 4. So you might think you’re getting 10,000 campaigns … but not really.
What you’re actually getting is 3 levels of hierarchy that represent increasing richness of data. But how much you get in postback #1 (yes, it’s only possible to get up to 4 digits for the first postback, not for the second or third) depends completely on whether or not Apple determines that the requirements of crowd anonymity are satisfied.
In that first postback, you could get
2 digits
3 digits
or 4 digits
If there were enough installs from a particular source, you’ll get all the values. If you do, you can choose to use them for different sets of data
campaigns + geo
campaigns + network
ad type
ad location on screen
and so on …
So, you get the potential for 4 digits of campaign data, but you’re not getting more campaigns, necessarily. BUT … you can decide how you use the extra digits, and you can decide to pack more dollars into specific partners to (hopefully) ensure you get four digits, and therefore you could theoretically measure just about anything you want in your additional digits, including:
Creative
Additional campaign IDs
Data you can use to reconstruct cohorts
And more …
Testing will reveal all when SKAN 4 launches, presumably around November of this year, and (it wouldn’t surprise me) in some form of public beta.
3. Coarse conversion value type in SKAN 4
There’s a new conversion type in town and it’s a little rough around the edges (sorry). Coarse conversion types are new and designated primarily for the second and third postbacks that SKAN 4 will now provide.
In the past, you either got a conversion value or not: 2 options. Now, with 2 types of conversion values (the first postback can have a fine value with more data, as explained above), you can get 3 possibilities:
A coarse conversion type obviously won’t provide a ton of data. However, it can still be extremely valuable. Think subscription apps, where you might get a conversion to a trial, but only 30-40% of trials convert to paid customers. As Thomas Petit told me in a Mobile Heroes Uncensored podcast, now you can design conversion values that report what happens after the trial — something that was impossible in SKAN 3.
4. How crowd anonymity and conversion values will interface
Clearly we don’t have the full specification yet but the early indication is that crowd anonymity is about number of installs, not number or variety of conversion values. That’s good news because if all the various permutations of conversion values were censored or not depending on how many of them exist, that could get very complicated indeed. And, of course, vastly reduce the number of conversion values marketers get.
Ultimately, however, this is a TBD until we have a chance to evaluate the specifications and also, likely test SKAN 4 in the real world.
5. Postback timers for all 3 postbacks
One of the many challenging aspects of SKAN 3 is the random timer which ensures you get postbacks at indeterminate times. In SKAN 4, of course, you’ll get three postbacks which can each be set (and updated) in a very specific period of time, and sent at the end of that time.
Postback 1: set in the first 0-2 days
Sent after 2 days
Postback 2: set on day 3-7
Sent after 7 days
Postback 3: set from 8-35 days
Sent after 35 days
This alone will have a significant impact on the industry. Facebook, along with other adtech partners, have essentially required the industry to get SKAdNetwork 3 postbacks as soon as possible … within 24 hours (plus the random timer in SKAN 3).
Now the earliest you can get a postback is 2 days, although we think Apple will add some degree of randomness to this and not just trigger every postback exactly 48 hours after its install. If that’s true, postback 1 might come in 50 hours, or 55, or 60. Postback 2 might come in a week and 3 hours, and so on.
6. No fine conversion values for postbacks 2 and 3, and no guarantee of postbacks 2 and 3
This is an interesting design decision. Obviously, most marketers would like as much data as possible, and if fine conversion values are available for postback 1, they’d like them for postback 2 and postback 3 as well.
However, instead of the limited amount of data you can pack into 2 digits (if you have low volume) and the additional, richer data you can add if you get 4 digital (with increased volume), you’ll only get the three values postbacks 2 and 3.
In addition, just because you get a postback in the first slot for a particular install, that does not mean you’ll automatically get a second and third.
This all has some implications:
This is going to be challenging for app publishers who have major retention challenges
Scaling spend with specific publishers is going to a popular way to maximize data
Spending more for quality users/players/customers is going to give you better marketing measurement data than spraying and praying with poor quality ad partners
In addition …
Getting a second and third postback, if you can get them, will still be usable to help calculate D7 ROAS (or should we now say D8 ROAS). It’s just a lot more complex than it used to be, with a lot more data science required, and correlation with IDFV data and in-app data.
7. No, 3 postbacks from (potentially) the same user don’t mean you have a user/customer journey
One thing I thought briefly when I saw Apple’s presentation is that the postbacks would be correlated: one person installs your app, and you get:
Postback 1 for that person
Postback 2 for that person
Postback 3 for that person
However, I was dreaming, and quickly woke up. Getting 3 correlated postbacks for a particular person would clearly be exploitable to create a privacy breach.
You’ll know which postback you’re getting, and you’ll know what the Source ID is so you can get campaign information, but they are not connected via any kind of user ID. What that means, clearly, is that each set of postbacks should be seen as aggregate measures of a campaign within a range of time.
It’s still good information, but it’s not a user or customer journey.
8. Conversion values can go down, not just up in SKAN 4
In SKAN 4, conversion values can go down, not just up. That’s potentially extremely useful: you could have players/customers/users who look great at or shortly after install, but soon show sure-fire signs of not being monetizable soon after. Now you can account for these.
For instance, someone might create an account in a finance app, which is a high-intent signal, but perhaps they don’t fund it or connect a bank account or credit card. Or a player in a battle game might eat up levels 1-6 but get stopped in their tracks at the boss level 7. They might look at an in-app purchase option, but don’t buy, don’t join a clan, don’t watch a tutorial, and don’t watch a rewarded ad to get a power-up.
Now you can find that out.
A few implications:
This is a significant logic change
It changes how we think of D1/D3/D7/D30 cohorts and models
It allows you to have more types of conversion models
And, of course, it brings additional complexity
9. SKAN 4 has more data for modeled cohorts
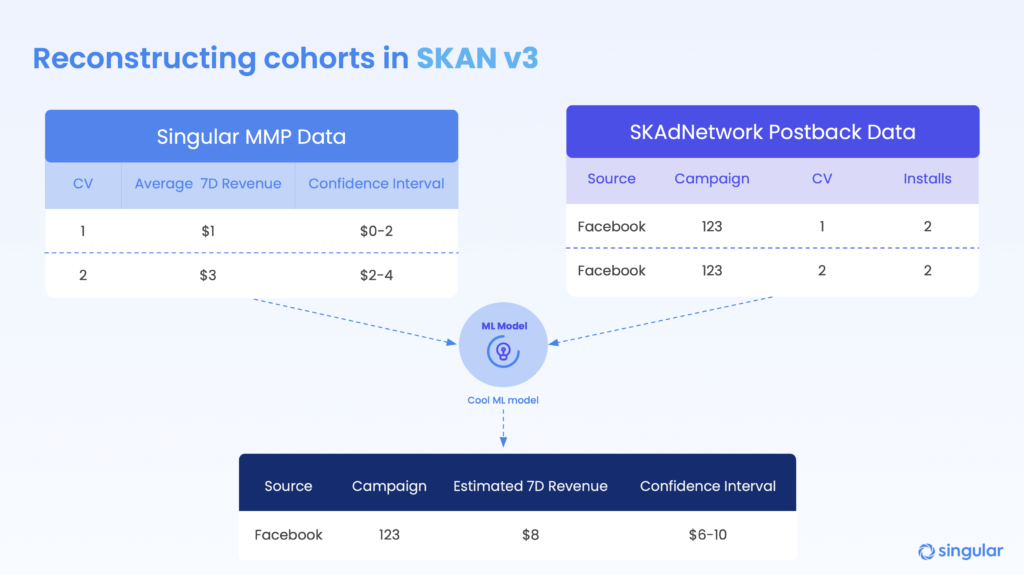
For SKAN 3, out now, Singular released SKAN Advanced Analytics with modeled cohorts. Modeled cohorts combine data from multiple sources to reconstruct cohorts using IDFV (good user data, no attribution) and SKAN (attribution, but no user data).
In SKAN 4 there’s simply going to be more data, more signals for the model … and more complexity. But the end result should be more accurate. The key will be how you use the second and third conversion values effectively, and whether you get them.
10. In SKAN 4, you have to think about more measurement windows
SKAN 3 just has one postback that you typically wanted in a day, although technically you could extend it much farther out in time.
In SKAN 4, you can set a conversion value for postback 1 at any time up until the end of day 2. You can also update it both up and down at any point during that time. And the same is true for postbacks 2 and 3, even though they obviously don’t offer the same amount of potential data richness as postback 1.
This could get confusing.
First, your app or your measurement SDK needs to measure time. It needs to know which window you’re in and act accordingly. Then it needs to set a useful conversion value … which can change. There are going to be some complexities here: marketers are already struggling with SKAN 3 and its single conversion value.
11. Your SKAN 4 postback strategy might differ based on your vertical and your goals
Apple’s told us you’ll get coarse conversion values much easier than fine.
Some marketers in verticals like hypercasual games might think they can get away with coarse conversion values only — especially in a testing phase — and spread budget thinner among more partners and more campaigns. Then, when you hit pockets of success identified by the coarse conversion values that you really want returning in postback 1, you might double down, concentrate spend, and attempt to get more detailed measurement and optimization data.
But in retail or subscription apps, you might need more data right at the beginning, and might therefore not choose to cast as wide a net in testing.
12. You’ll still need data modeling for missing data
SKAN 4 offers more data than SKAN 3 … we think.
But we actually don’t really know for sure if the fine conversion values in SKAN 4 activate at similar levels to the only conversion option in SKAN 3, which would mean more data … or if Apple will provide only coarse conversions in SKAN 4 at the current privacy threshold/crowd anonymity level of the single postback in SKAN 3 … and fine conversion values will take additional app install scale.
Either way, you’re going to be missing data.
And either way, you’re going to need modeled data to replace it. You’re still going to have a lot of missing data, whether it’s from postback 1, or 2, or 3. The good news is that now we have more data points to use in modeling, which should improve accuracy.
13. Fraud is still a question mark in SKAN 4
Something we haven’t talked a lot about with regard to SKAN is fraud. SKAN 4 will bring some additional challenges.
There are 2 ways to report touchpoints: clicks and impressions. Clicks lead to the app store, so that’s secure, but impressions do not. Which means that any app can report impressions all the time and potentially take credit for organic installs.
Apple is aware of this and knows it’s a gap, but it’s not clear what they can or will do about it.
14. There will be multiple SKAN versions live in the wild
The ecosystem will be at different levels of support initially, but so will phones. Some people don’t update their mobile operating systems quickly; some can’t because they’re using older handsets.
That means that publishers and adtech providers will either have to support everything, or pick and choose what they support, or support the newest version and try to maintain compatibility with older versions of SKAdNetwork.
Possibly Apple will have more to say here about the device side, but Apple can’t typically force people to update their phones.
So … brace yourself.
More questions? 27 questions answered
We received more questions in our SKAN 4 webinar than any other in my recollection, and while we couldn’t answer them live, we did answer them in a blog post afterwards. So check that out for additional information:
There’s been a $4.4 billion disturbance in the adtech force as Unity bought ironSource (officially: merged with) in an all-stock deal accompanied by a fresh infusion of cash into Unity from investors and a $2.5 billion stock buyback aimed at pumping up the newly merged company’s share price.
There’s a lot of speculation about why Unity pulled the trigger on the deal.
More data is always better for ad targeting, and Unity Ads needs it at least as badly as any other ad network. Tech stocks are depressed right now and, hammered by ATT and a worsening economy, ad networks are being hit harder than most. So any boost from a merger is helpful. Plus, of course, ironSource has extremely valuable technologies, scale, and customers that will help Unity build a more complete monetization solution.
I chatted with Unity CEO John Riccitiello about why Unity bought ironSource.
Watch our conversation here:
Here’s a lightly edited excerpt of some of Riccitiello’s answers:
Why the Unity – ironSource merger?
Unity CEO John Riccitiello:
“Most of the world’s game content is built on Unity. We’ve also got a really strong monetization network and what we’re trying to get to over the course of many years is a platform where a creator can make the best content and monetize their best content.
And sometimes monetization is harder than it is to build a great game. And if you don’t have a great business to go with a great game, you don’t have a great game because you don’t have the resources to make it. And so what this is about is: they have some tools that are pretty amazing that if you add to our stack, we can get to a place where a creator can get user feedback on pieces of the game along the way … they get feedback on user engagement and what’s working and not working, and also simultaneously get feedback on what it takes to acquire a user.
So the outgrowth of a unified creation and growth platform that we can put together is really better content and a better business in a way that we think is really magical for creators.”
The stock market has not been kind to tech in general and to Unity and iS in particular over the past months. How will this change the narrative and the results?
Unity CEO John Riccitiello:
“Changing the narrative is always important, but what’s really important is changing the outcome.
Now, on its own, I believe that Unity was on its way to being one of the great companies in Silicon Valley or around the world in tech. Our Create solutions and our monetization solutions — in light of the reality that most of the world’s content is becoming real-time 3D — that’s a huge wind in our sails. So we think we’ve got a lot of opportunity as a standalone. And I think ironSource thought similarly about themselves.
Here’s the long-term vision: we’re gonna deliver a run rate of $800 million in EBITA by the end of 2024. And we’re gonna do it by driving synergies around three really big ideas.
Those synergies are around more data is better.
And a diversity of data means we’re not dependent on any one data source. They’ve got a lot of different data sources, and so do we; it’s a large number, I could list them if you want. The second is they’ve got a leading mediation tool, which is an important part of a full stack monetization platform. We will bring more data, more demand to that platform and that’s helpful to both companies.
Again, when customers win, we win.
And third, they’ve got a set of publishing tools that they call Supersonic. And it’s a great solution for the long tail. Virtually everybody in the long tail makes their games on Unity. This is one of those peanut butter and chocolate mixes where we’ve got the customer that they need. They’ve got the solution we need and we see strong synergy in that.
So three strong synergies driving a really strong trajectory on what makes the company valuable to Wall Street, which is profits.
Lastly, the resulting company will be very balanced. We outlined for investors today that we expect about half of our revenues to come from activities associated with creation and about half of our revenues to come from revenues that one might associate with growth [monetization].
So we think there’s a good narrative.
But it’s not a sound bite. It’s not a fortune cookie. And you know of course the markets are pretty tough right now. But my job is not to worry so much about popularity, but about building a great business. We’ve got our eye on it. And as we do that I’m sure we’ll attract more and more fans as we always have.”
What specifically about ironSource is most attractive to Unity?
Unity CEO John Riccitiello:
“Their LevelPlay mediation platform is very attractive. I also believe their Supersonic publishing tools are attractive. I would also highlight the tools that they use to support mobile carriers around the world … [they] are really, really positive.
But if I had to pick something that I think might go without notice and is not usually mentioned, they have an awesome team.
I’m so proud of the Unity team, but when I meet these folks they’re aggressive, they’re ambitious, they’re competitive. They don’t have any of the arrogance, that sometimes can seep into some Silicon Valley companies and organizations. I mean, they’re just humble and ambitious and they mix so well with my organization.”
How much did ATT on iOS impact this merger?
Unity CEO John Riccitiello:
“I’d say virtually not at all.
Just to remember: when you’re thinking about ATT or iOS privacy changes around the rules that Apple’s put out …. one thing to think about is that’s a very specific slice of data. It doesn’t really affect Unity Analytics in the same kind of way as the SDK for ads where people are seeking permission. It doesn’t affect, for example, a publishing business and publishing tools that [ironSource] have, or some of their tools on carrier installs and such. And so there’s a lot of ways data comes in.
Look, I’ll tell you a story.
As you can see, I have gray hair. One of the things I find really frustrating is that I get a lot of advertising targeted for people over 60. AndI look at that stuff and I’m a skier, I’m a tennis player, I’m a mountain biker … and then I get a Depends ad and it just doesn’t really work for me. And that’s bad targeting, not good targeting.
And the other issue is when people think about data … all we’re looking for is we’re helping a gamer find other games that are appropriate for their interest profile. And we’re really good at that. And we get even better at that in combination with ironSource, and consequently can help publishers be more successful, developers be more successful, and frankly, gamers be happier.
We’re not trying to figure out the name of your brother, whether your mother’s birthday is the week after next, or what you’re looking for on the internet. That’s just not interesting to us at all. We’re trying to find people for whom we can find a profile for the game industry, but also for some brand advertising. But we’re not reliant on personal identifiable information either. Ours is mostly contextual. We have the context of what you’re playing and how you’re playing it.
The only media I’m aware of that the audience, the player, the user actually thinks ads are positive, is gaming. And we can prove it by showing you that engagement is greater when there’s ads. And that’s because of the way they’re integrated in the game, and because performance means you’re getting ads that are relevant to you.
If there’s a recession, performance advertising that the user or the viewer or the player likes, enjoys, and leads to increased engagement, and ROI for the advertiser — our advertisers don’t necessarily want to spend more, but they definitely want more ROI —- and so that’s what we deliver.
And I don’t think we’re going to come under the same pressure in this sector as others that don’t have those same features and characteristics.”
How long do you anticipate merging tech stacks will take?
Unity CEO John Riccitiello:
“I’m not sure if there’s all that much to merge.
One thing that merges almost instantly is the most valuable asset here, and that is data. So they’ve got an algorithm for their network, we’ve got one for our network. Whenever we add new data, our network performs better for customers. Now we can do that at a larger scale. That’s a positive, it doesn’t involve a technology, stack integration.
Another piece in this is they’ve got a large mediation tool: we’re not planning to merge our tool into their tool. They’ve got the Supersonic publishing tool set. We don’t make that tool set at all. They’ve got the tool set that I talked to you about that supports carriers; we don’t have that technology.
When we presented to investors, we gave them the requisite sort of Lego pieces: they do this, we do this, they do this, we do this. And what was really interesting is how much of the tech stack that they do that we don’t do. And of course they don’t do any of the Create side really … so what we do that they don’t do. So I don’t think there’s this vexing tech sack challenge.”
You seem to be driving further synergies between Create and Operate … how close do you intend to bring these capabilities?
Unity CEO John Riccitiello:
“Very.
Now, that doesn’t mean that I’m gonna surface return on ad spend tools for, uh, a C# coder. If it’s working in the development side of a game, it means when that developer, together with the artist and the level designer to put that together, and they’re trying to get information over how engaging this is for the user … but they don’t know necessarily fully what to do with that and how to map that to the LTV is greater than cost to acquire equation … but there’s a business person that probably works on that full time: they have the same set of data.
They’ve got the same understanding. They’re learning the same things in real-time. So it’s surfacing data like that. That will enable them to be very close, but not cumbersome.
The key here really is bringing these things together to yield the benefits of both. So through a very iterative process, the game gets better. The digital twin application gets better. The user acquisition gets better and better in terms of targeting and success rate and pulling them with ads that can be tuned and changed based on pulling data out of the game to automatically create ads.
And it creates a virtuous circle.
These days virtually all these applications, whether they’re car configurators or digital try-ons in your home for a luxury brand, or a video game, they’re all live experiences. They’re up there. And these products themselves are changing in time.
And so this process never needs to end. It just needs to be smarter. And that’s what we bring to it. And we have a profound view and I think it’s correct, that we are able to add value to the full team that’s making and trying to make a living out of this stuff and in doing so, we’ll make them more successful and they’ll choose us more often.
It’s a pretty simple equation. If you’re really focused on making your customer successful, I think you have every opportunity in the world to be successful yourself.”
In the adtech space there are giants like Facebook/Meta and Google, a set of large competitors that both Unity Ads and ironSource fit into, and then thousands of others. Where does the combination of Unity/ironSource position you now vis-a-vis adtech competitors?
Unity CEO John Riccitiello:
“I don’t necessarily think of Meta and Google as competitors really, or Amazon or others that have big adtech businesses. Why? Because they’re all business partners. We do an enormous amount of work with all of these companies … both them working through our network on the monetization side, or they’re using our tools to create content, or them facilitating us on the cloud with some of their backend tool sets and their hosting capabilities.
Think of thinking of all these guys as sort of lethal competitors would not be the way I see it. Of course, everyone’s skirmishing to grow their business world’s has gotten a lot more complicated than Coke versus Pepsi. You’re not gonna drink both at the same time, but when you’re using Unity hosting, you’re often using GCP or Amazon at the same time.
So it’s not quite the same.
But if you think about a single dimension, say if you’re looking at the modernization or the business growth side, what I think people have come to believe, and I believe is true is data is what separates the strong from the weak.
And I would argue maybe one of the lesser appreciated points is diversity of data is another vector along which to think of what’s defensible and important.
And think about all the data sets I’d mentioned earlier, and … realize that they’re reaching north of 2 billion people in a month; we’re reaching north of 3.”
How does this make Unity stronger/better going forward?
Unity CEO John Riccitiello:
“It all starts with getting a better outcome for our customers: either making better content, helping them make a better business, or both.
And we think we are in the business of helping our customers make better content and get a better business outcome through better targeting. And if they’re on the supply side, higher CPMs, and if they’re on the demand side, a better return on ad spend.
We think those are measurable. We think this combination improves all of that on behalf of our customers.
And sometimes we don’t always know exactly how we’re gonna win when our customer wins, but time and again, we’ve won when our customer wins.”
Subscribe to Growth Masterminds
We talk to industry leaders about key changes happening in the mobile adtech industry.
How will SKAN v4 impact the mobile advertising industry?
App Tracking Transparency and SKAdNetwork have been the biggest changes in mobile marketing since the introduction of the IDFA. They have completely disrupted an ecosystem built on relatively stable, easily available, and very shareable device identifiers for the vast majority of smartphone owners.
As every mobile marketer knows, SKAdNetwork has been tough. It’s hard to set up, it offers limited capability, it broke attribution methods and BI systems, and it forced growth teams to change long-standing practices.
But there is light on the horizon. At WWDC 2022, Apple teased SKAN v4, and there’s some hope. SKAN v4 offers more data, more postbacks, and more opportunity to both measure and optimize marketing results.
So Singular CEO Gadi Eliashiv and a team of Singular experts dug deep into what Apple has announced so far about the fourth major iteration of SKAdNetwork, and we shared the results in a webinar with over 1,000 registrants: SKAN v4 Deep Dive: How iOS UA Will Evolve.
We had more questions in this webinar than ever before, and I’d like to take this opportunity to answer them.
27 questions on SKAN v4 answered
1. If UA campaigns become spread across thousands more campaigns, won’t we also just not end up reaching thresholds? And thus never getting beyond coarse?
A: Exactly. You’ll still have to concentrate significant numbers of installs inside each campaign (we’ll only know exactly how many when SKAN v4 is released and we do some testing).
Upshot: advertisers with vast scale will benefit the most.
2. Can we ever expect Apple to allow MMPs to distinguish installs attributed via Apple Search Ads from all other channels? This fundamental flaw has most UA managers paying for installs coming and going.
A: That would be nice. We’ll ask Apple 🙂
3. Do you know if the coarse values will be customisable? Same question for the conversion window for multiple postbacks? My understanding is yes but is it?
A: Since the coarse values can refer to anything you want them to, they are (in a sense) customizable.
The conversion windows, however, are not. You can set values whenever you want, but they’ll only be sent after the conversion window expires:
0-2 days
3-7 days
8-35 days
4. Has there been any speculation on whether the threshold for fine values could be increased vs. remaining as is? Or is it a given that coarse values will come in at a lower threshold? Same question for campaign IDs.
A: It is a given that there will be lower thresholds for course conversion values than fine, but Apple has not spoken on where the levels will be set, or on how the levels will compare to existing privacy thresholds.
We’ll simply have to wait for the spec, and probably also for some real-world testing.
5. Regarding the 3 postback windows, does the conversion value schema definition need to be the same for all 3 windows?
A: Not really. The fine conversion values offer much more data; the coarse values just 3 options. Those 3 could be identical to some of the values you’ve defined for your fine conversion values, but you’re likely to have many more options there.
6. Are you suggesting that the 3rd postback would only be sent on Day 35 then?
A: Yes, or shortly thereafter, if there’s a random timer for privacy enhancement purposes.
7. Concerning conversion postback randomization … do you foresee this having implications on fingerprinting?
A: I think they’re different issues. (So essentially: no.)
8. How do you think it will be possible to connect all three postbacks in order to understand that this is a single install?
A: No. Think of them as aggregatable data for cohorts, but not for connected data points in a customer journey.
(I did initially when viewing the Apple presentation, but had my hopes dashed upon further investigation.)
9. Will the 2nd and 3rd postbacks at least allow us to see much more aggregate post-install data?
A: Yes, given that there was basically none available before SKAN v4 🙂
10. How does probabilistic attribution factor into the whole ecosystem? Why do ad networks need to run on SKAN postbacks? Why can’t MMPs make probabilistic attributions and post those to ad networks for decision making?
A: Apple has explicitly stated that fingerprinting is not allowed, whether ATT consent is granted or not.
All the major self-attributing networks support SKAN and make fingerprinting impossible, so that’s 75% of ecosystem volume. Only a quarter therefore even makes fingerprinting possible, but with more data available in SKAN v4, that’s the way to go.
(Plus, it’s less risky. If Apple doesn’t allow fingerprinting, apps or SDKs that enable or provide it will run serious risks in doing so.)
11. I hadn’t seen anything on the randomized timer in conjunction with the set windows for postbacks. Is there just an assumption that there is a randomized timer to protect user anonymity?
A: Yes. We’ll have to see the final specification for confirmation.
12. Even if we don’t know that the postbacks are from the same person, we will know they are from the same cohort, right?
A: Exactly. Yes.
13. How is the coarse part of the second and third postback windows connected to the first postback? Let’s say we had enough installs per campaign , will the second and third postback be dependent on the activity of those installs then?
A: As far as we can tell, each postback opportunity gets sent or not based on its own merits in terms of achieving crowd anonymity.
See also Q5 above for some related details.
14. I got a little lost on the “fine/coarse” conversion value and the 3 postbacks. Can you give an example of how an advertiser (say, in rideshare) might set up a conversion model with SKAN 4.0?
A: Absolutely. Here’s one potential option:
Installed, took some action
Took rides, value totalled either $0, $0-50, or over $50
Shared the app with a friend, posted to social, or didn’t
That is literally just one potential sequence of an infinity of possible ones. Insert your core KPIs for one that makes more sense for your specific business.
15. Will SKAN v4 increase the likelihood of a fingerprinting ban enforcement?
A: I want to say yes, but Apple has already banned fingerprinting … so no, not really.
I think SKAN v4 makes it more likely that Apple will more aggressively enforce its already-stated rejection of fingerprinting, because now there is a more viable privacy-safe measurement solution than previous versions of SKAdNetwork, regardless of what people select in the App Tracking Transparency prompt.
16. Do you know if the range for low/medium/high coarse conversions will be customisable or if we have to assume that it will just divide the fine conversion in 3 equal tiers?
A: There will be 3 tiers. You will get to decide what you assign to each tier.
17. Have there been any updates on the timeline for SKAN v4 release (beyond “later this year”)?
A: No 🙂
If Apple makes its self-imposed “this year” deadline, my guess is October/November is the most likely time frame. That’s enough time from now for significant amounts of development, and it ensures that Apple doesn’t drop a new version of SKAN — even if it’s beta — right before the Christmas break.
18. Did I understand correctly that now the CV sending windows will not be dynamic, but static and will definitely be 0-2, 3-7, 8-35?
A: Yes, but we assume some randomness to the sending to preserve anonymity.
19. Is there any work around on retargeting with v4?
A: Not yet. That would require something like FLEDGE in Google’s Privacy Sandbox for Android, and we haven’t seen that from Apple yet.
We’ll have to file that in the would-be-nice-in-SKAN-5 file.
20. Can the coarse value be set differently based on the original fine value? Or perhaps in context of previous coarse values?
A: Yes, and yes.
It’s safest not to think of them as connected sequences but disconnected signals at different stages in the progression or aging of a cohort.
21. How are coarse values being defined? Is this something we can map on our end similar to how we map values and events to the 64-bit conversion values?
A: They are simply 3 values which you map in your systems to whatever events or activity you wish. (So that’s a yes.)
22. Does CV 0 still need to be the app first open? Or can you trigger CV 0 as another in-app event? (For example, start postback windows and attribution on a registration type event)?
A: It does not need to be the first app open, but you will need to trigger it (or lose your first postback opportunity) within D0 to D2.
So if you get a registration type of event within D0 to D2 (and your app or attribution SDK better be keeping track of timing), you could totally do what you’re suggesting.
23. What is the future of tracking owned media? (i.e. traffic from first-party mobile web, email, SMS?
A: Apple adding web-to-app is a very positive sign here. We don’t have the full implementation yet, but privacy thresholds still apply (which hurts a bit for owned traffic). Using campaigns effectively and even applying old-school methods like offer codes will be important for many.
24. Which platforms do you think will cope with SKAN 4.0 changes and which ones will not?
A: Time will tell 🙂
Best guess: the big ones will get on the train. Some of the smaller and fringe players will delay and make errors. It will be messy. You’ll have to support users on lower versions of iOS with perhaps earlier implementations of the SKAdNetwork framework, and ecosystem partners who are at various stages of development as well.
25. How do you think Private Relay will be utilized?
A: We see it expanding over time, perhaps to all web traffic in addition to app traffic.
Of course, “soon” might be 2023 or 2024. There’s a lot for Apple to build (or partner with) in terms of capacity to support that kind of upgrade.
26. For an agency: what changes do we need to make in the postback which is updated by the MMP?
A: We don’t have the specification yet, so we’ll have to wait and see. We do know that Campaign ID is changing to Source ID.
27. With crowd anonymity thresholds applied to postback 1, would you agree that advertisers will likely be getting less information on user value in many cases than we’re currently receiving? Do you think it’s more likely that postback 1 might only get a coarse CV?
A: Some have speculated this, yes, but the truth is we just won’t know until we see the spec, start testing, and study early results.
You really, really, really need to watch the whole webinar
There’s much, much more detail in the full webinar, including discussions of:
The legislation is the Digital Markets Act and the Digital Services Act, both ratified by the European Parliament on July 5th, and both massively impacting how tech giants must act in the unified European market of 450 million consumers.
The laws are significant and wide-ranging, with what Thierry Breton, the European commission for internal markets says are implications for:
Controlling illegal content
Protecting privacy rights
Protecting children online
Limiting monopolies and/or large tech companies acting as “gatekeepers”
Regulating digital advertising
Shining light into black box algorithms
With these laws the EU, which has already fined (mostly American) tech companies literally billions of dollars, has given itself extraordinary powers:
DSA violations can cost companies up to 6% of their global income
DMA violations can cost companies up to 10% of global income
Companies can be forced to divest themselves of divisions or products
Companies can be banned from operating in the EU
What does this mean for Apple and Google?
What does the Digital Markets Act mean for companies like Apple and Google, which make the world’s most popular operating systems that run the most personal computers that have ever existed? Google and Apple are most definitely on the target list for exactly this kind of legislation, and will most certainly be defined under the DMA as “gatekeepers” that govern access, to greater or lesser degrees, to their massive mobile platforms.
Gatekeepers will be forced to:
Allow third-party interoperability with their services
Allow business users to access data generated in their use of a platform
Provide tools for independent verification of ads hosted on their platforms
Allow businesses to promote their services and make sales outside the gatekeeper’s platform
And gatekeepers won’t be allowed to:
Privilege their own products or services over third-party apps
Prevent consumers from connecting with businesses outside their platforms
Prevent people from uninstalling any pre-installed apps or software
Track people outside of their core platforms services for targeted ads without consent
Specifically in the context of mobile apps, that probably means something like this:
People can delete pre-installed apps
People will able to side-load apps, or install them just like you might install an app from the internet on a desktop computer
Businesses can create independent app stores
Apps can use third-party payment processing
Apps can interoperate with core services around messaging
Apps can use hardware features that platforms might have reserved for themselves
People can switch AI assistants
The Digital Markets Act will break the App Store model
First off, don’t get too excited too fast.
Just because something is possible does not mean it will happen. And both Google and Apple will do all they can to retain as much power and capability as the EU will legally allow them to.
Plus honestly, if I have the choice between installing an app from Google Play or the iOS App Store versus ABC Apps4Less App Store … it’s not a hard decision. I’m going to go with the brand I know because I have a level of confidence that the apps I install from that source go through a degree of vetting and verification, and will be relatively safe for me, my data, and my money.
But make no mistake.
If third-party app stores are possible, they will exist. And while it may take years to establish trust and brand awareness, eventually they will constitute a viable alternative to the platform defaults.
Or, as Eric Seufert suggests, platforms like Meta and Amazon and Twitter and TikTok might add apps to their services and speed up the process, thanks to their existing relationships with billions of people and existing brands with existing trust. (And existing antipathy to Apple and Google for owning the portal via which they distribute their core access points to consumers.)
Once they exist, some will start to gain traction. Once that happens, there will likely be a tipping point after which publishing your app on alternative app stores will be completely viable … perhaps even with or without publishing in the actual approved platform owner’s store.
And that calls into question App Tracking Transparency, Privacy Sandbox for Android, and the privacy strategies Apple and Google have been deploying
Partly in response to global legislation, partly out of branding, partly out of altruism, partly out of competition, and partly out of business strategy vis-a-vis other big tech giants, Apple and Google have been pursuing what would once have been considered a radical privacy transformation.
From wild wild west landscapes for mobile marketing with free-for-all device identifiers, Apple first and Google second have been architecting privacy regulations and restrictions on how advertisers and adtech platforms operate, what data they have access to, and where data can be shared. While many in the industry would probably not be happy with those restrictions — just 9% of mobile marketers in a recent Singular webinar said their progress with Apple’s SKAdNetwork framework for mobile attribution was “good” — most would also acknowledge the need for change from the previous free-for-all data-sharing-gone-wild ecosystem.
But now with the Digital Markets Act, Apple’s privacy controls and Google’s privacy plans are both at risk.
While there’s much a platform can do to drive compliance by software running on it, both Apple’s and Google’s primary carrot and stick over app publishers lie in their control over the App Store and Google Play, respectively.
The implied and actual contract is: abide by the rules, or your access to billions of people will get cut off.
Toe the line, or face digital execution.
With third-party app stores on both Android and iOS in the European Union that becomes much more challenging to enforce. The stick is a lot smaller and weaker. And it gets worse: when consumers and legislators in North America, South America, the middle east, Africa, and everywhere else see what the EU has done … maybe they’ll start advocating for it as well.
Or just legislating and demanding it.
As that occurs — and it’s very much the secular trend, as economists would say, across the whole planet — delivering your app to the world becomes a very different proposition. Just as importantly, marketing and advertising that app becomes a very different proposition.
Now you can theoretically buy ads anywhere to direct people to your app anywhere to get them to install it on their Android or Apple smartphone, and Google/Apple will have much less control over how you do that and what you do to make that work. And they’ll have less control over data used, data collected, and data shared in the process.
Take a deep breath: this will all take time to clarify and play out
None of this will happen overnight, and all of this kind of change will likely happen as demanded by legislators and investigators and courts.
It’s probable European legislators will look favorably on Apple’s and Google’s efforts to increase privacy and decrease data collection and sharing. But it’s also probable that they won’t look favorably on the tech giants’ assumption that they alone can create and enforce the standards necessary to achieve that.
When the dust settles on the Digital Markets Act, however, we might just find that Epic’s Fortnite battle against platform rules for app distribution and payments might have presaged the future of mobile. And that it might look a little bit more like the old world of desktop software than the walled garden it has become.
550 days ago, Apple changed mobile marketing measurement forever with the launch of iOS 14.5 and App Tracking Transparency. Four months ago, Google laid its proposal for the future of marketing measurement in front of the global app growth community: Privacy Sandbox for Android. So we’ve had a little time — particularly on the iOS and SKAdNetwork side — to prepare. The question is: how ready are marketers? How can we rate mobile marketers’ privacy progress?
We recently ask hundreds of marketers in a webinar questions on exactly that.
The results are not exactly pretty.
It’s not for lack of awareness: everyone knows that the future of marketing measurement looks very different than it did two years ago. IDFA is now scarce and GAID is literally going to be nonexistent. Third-party cookies are also going the way of the dodo, and non-device-identifier means of tracking like fingerprinting are increasingly either legally dubious — read GDPR, baby — or counter to platform guidelines, or rendered technologically impossible.
That means marketers of the future (like, literally tomorrow) need to become experts in privacy-safe attribution, or acquire that expertise, or partner with companies that manage it for them.
In a recent webinar on the future of user acquisition, we asked participants to answer a series of polls of privacy-safe attribution technologies. Typically we get over a thousand registrants, about a quarter of whom participate live. In this case registration was higher, while around 250 mobile marketers watched live. (Caveat: this is not a random selection of growth pros: this is people who decided to participate in a webinar on these topics.)
So let’s see how people responded … and how we can currently rate mobile marketers’ privacy progress.
Success with Apple’s SKAdNetwork framework
We asked participants a simple question: How would you rate your success with SKAN?
Less than one in 10 said they could call it good, while 41% said it was passable. Which means, I guess, getting a C. Half of the participants said “we really have work to do.”
Success with SKAN
Yes, this is from a webinar that is specifically on SKAN and improving user acquisition measurement, so on the one hand it’s not too surprising. On the other hand, we’ve had App Tracking Transparency in place for well over a year now, and many are just realizing that they can’t skate by on fingerprinting or legacy optimization data.
Have you started to prepare for Google’s Privacy Sandbox for Android?
The results for the second poll were intriguing.
13% of mobile marketers in the webinar have already started to prepare for Privacy Sandbox on Android, suggesting that maybe the tough experience we’ve all gone through on the Apple side of the mobile ecosystem is having some benefit in terms of Android preparation.
Privacy Sandbox on Android
On the other hand, 34% of mobile marketers are waiting and seeing. Most, however, are in the third bucket: reading about Privacy Sandbox and perhaps attending a webinar or two to gain some initial familiarity with the topic, the technologies, and any changes they’ll have to make.
Are you leveraging incrementality?
SKAN is a currently-available privacy-safe mode of mobile attribution and Privacy Sandbox is a future one, but a technology/technique that’s been available for a long time is incrementality. While incrementality requires some chops to work with and get right, it does offer a completely tracking-free and privacy-compliant mode of measurement.
Leveraging incrementality?
Just over one in 10 is actually actively using incrementality right now, which suggests this is actually a fairly sophisticated sample of mobile marketers, while 32% are occasionally testing it, and 55% are in the nope category.
It may not be for the faint of heart and it does require some volume, some work, and sometimes a little bit of serendipity, but the number in the yes column is definitely going to go up in the coming years. Chat with Singular if you’re interested in knowing more about how to use all the marketing data we collect for you in incrementality analysis.
Want to learn more about how SKAN Advanced Analytics can help to optimize your iOS measurement?
Finally, we tooted our own horn just a little bit, asking people if they’d like to know more about SKAN Advanced Analytics. That’s Singular’s latest release of SKAdNetwork measurement technology, and beta testers have achieved a fairly stunning 87% D7 revenue prediction accuracy on average.
SKAN Advanced Analytics
85%, staggeringly, said yes.
Again, caveats abound: they’re in a Singular webinar, which shows they’re open to Singular solutions. But still, an overwhelming majority are interested in ways to enhance the data they’re getting for iOS growth campaigns, and that’s interesting.
Where do you fit?
The most important point right now is this: where do you fit? If you put yourself on the mobile marketers’ privacy progress scale, where do you end up?
Are you getting the results you need from iOS right now? Are your mobile growth campaigns performing to expectations? While we’ll likely never recover the level of targeting and attribution that free-for-all IDFAs enabled, SKAN can work.
It’s not easy, and it does require some change, but it is possible.
Fewer than 10% of mobile marketers in a recent Singular webinar rated their use of Apple’s SKAdNetwork framework for mobile attribution as “good.” Just over 40% said their efforts were “passable.” A full 50% said “we really have work to do.”
My first and best advice: don’t delay, go sign up for that webinar, and enjoy it on demand.
My second: check out the following insights from that very special hour, where we talked about:
Reporting
Conversion models
Predictive life-time value
Campaign strategies
Creative strategy
Brand advertising post iOS 14
Targeting
First-party data
Privacy thresholds
Testing strategies
Rovio supplied an all-star and all-female group of experts, including Ann-Marie Pelkonen, Senior Product Manager, UA, Anastasia Nikitina, Senior Performance Marketing Specialist, and Erlin Gulbenkoglu, Senior Data Scientist. Here’s a selection of the insights they shared …
1. Pay the price and build a team
Everyone wants to achieve success with a minimum of effort, but that’s just simply not realistic in most areas of life and work. And it’s especially not realistic with SKAdNetwork.
“One key to our success has really been that we took SKAN seriously from the start. We really resourced, we researched and we tested really early on, so that has benefited us in the long run.”
Ann-Marie Pelkonen
If you’re looking for success on iOS, you simply have to become an expert on SKAN. There’s just no way around it. Only perhaps 20-30% of the supply is accessible with probabilistic attribution, and that’s going away as well. You need to pick a team, resource it, and take some time to figure SKAN out. (Singular can help.)
2. Start simple and iterate
So many tried to do too much with conversion models and timers in the early days of SKAN. And that’s going to continue to be a problem with SKAN 4, coming out later this year, because SKAN 4 is even more complex. It’ll have much more opportunity and data, sure, but many more challenges as well.
“Regarding the conversion value schemas … we started simple and we have since adapted our approach to something a little bit more complex, but then keeping in mind still, the network requirements and then what’s best for our revenue attribution model that we built for iOS.”
Ann-Marie Pelkonen
It was pretty hard to mess up IDFA-based attribution. It was simple, it was accessible, it was durable, and it was industry-standard. SKAN is much harder. You may dislike it or even hate it, or even think it’s garbage, as one of our recent webinar guests said.
The reality is as simple as it is harsh: it’s what there is.
Unless you’re going to ignore iOS and go Android-only (which is losing the GAID in 18 months or so), you simply have to figure it out.
3. Understand your own app’s signals
Unless you know the signals in your own app that predict user quality and profitability, you’re in for a world of hurt. After building up from simple steps, ensuring they understood SKAN, and building a working revenue attribution pipeline, Rovio worked on predictive lifetime value.
“Then we moved with more advanced things like pLTV, then we built the technology to support the pLTV conversion models. And then we have always been talking with stakeholders … we try to build something that gives us the best revenue attribution accuracy and also supports the networks that are using the signals from conversion values.
Erlin Gulbenkoglu
Notice there are two things that Rovio’s using pLTV for:
Long-term strategy: understanding the value of newly acquired players to continue to iterate marketing effectivness.
Short-term optimization: feeding growth partners the signals that drive near realtime campaign efficiency.
4. Widen your data funnel to get more reporting signal
“Now I need to use many more of different data sources than I used to use before. And I still cannot be 100% confident in the decision that I’m making.”
Anastasia Nikitina
Now Rovio is looking at, among other sources, pre-install data and post-install data, and using both to ladder up to overall ROI performance. That includes CPIs and CPMs derived from SKAN plus post-install data including conversion and retention metrics. And Rovio is comparing all of this to organic performance and matching against expected results.
Important point:
Truth is a little fuzzier post-IDFA. Rovio uses confidence intervals to guide decision-making, and makes decisions based on probabilities rather than certainties. (Let’s be honest: marketers have always done this. But now it’s a little more necessary.)
5. Demand DSP transparency
One of the key components of Apple’s mobile attribution framework is privacy thresholds to achieve crowd anonymity. Because of that, one of the non-Rovio participants in the webinar, David Phillipson — CEO and co-founder of Dataset — shared that transparency with your ad partners is critical.
“It’s absolutely key that … DSPs are absolutely transparent with the advertiser and with the MMP … by actually sharing [sub-publisher IDs] with Singular and Rovio, we’re actually able to establish what spend level per publisher we need to get to, to make sure we get the optimum amount of granular data out … [so] that we can put the best budgeting and pacing in place per sub-publisher within their budget, within their goals, to make sure that we get as much data out.”
David Phillipson
In other words, by sharing which publisher is driving every single impression that leads to an app install, DSPs and ad partners can ensure that advertisers maximize installs per source, which maximizes signal. Without that critical step, there’s the chance that a given budget could be spread among so many apps and websites hosting the ads that Apple’s privacy thresholds simply obliterate a massive amount of the data you need to optimize on.
6. Run experiments on historical data
If I had a dollar for every time a mobile marketer told me “testing is the key” in a webinar or podcast, I’d have a free European vacation. Testing is essential, but tests are expensive too.
There’s one way you can test almost for free, however …
“We have run experiments on the historic data, like, when we could do a revenue attribution with IDFA and pLTV has given us lower revenue attribution errors, and we decided to go with that approach. And one advantage of that approach is basically we can use as many predictors as we want. We don’t need to encode our predictors into the 64 buckets we have [with SKAN].”
Erlin Gulbenkoglu
Running tests on historical data allows you to pinpoint signals of high-value users in scenarios where you have all the data you need, so it’s definitely something to try.
A few obvious caveats, however:
If your product has changed significantly, be aware this could skew insights.
If people have changed significantly (Covid times versus “post” Covid, etc.) this can also result in insights that are not generalizable to today.
7. Consolidate campaigns
Privacy thresholds are essential to obscure individuals and achieve crowd anonymity. However, at the extreme, they block virtually all usable marketing optimization signals.
The solution: consolidation:
“The biggest change is probably that we had to consolidate our campaigns and increase the scale for those, and I would say this is the key for success basically on SKAN.”
Anastasia Nikitina
Spreading too little budget over too many campaigns loses too much data. Consolidate campaigns so that privacy thresholds work as intended in achieving crowd anonymity without also taking marketing signal along with them as collateral damage.
8. Rethink targeting
Clearly, SKAdNetwork can work as a foundation for mobile marketing success. Clients using Singular’s SKAN Advanced Analytics are literally achieving 87% D7 revenue prediction accuracy on average. But that doesn’t mean that everything works. Retargeting largely died with the IDFA, and targeting isn’t that much better.
“We do not have that much of [an] opportunity to do targeting anymore.”
Anastasia Nikitina
This of course could vary for different app publishers and advertisers. Rovio makes casual games, and the audience for casual games is large and diverse, which impacts the degree to which they need precise targeting. But the point remains: behavioral targeting without IDFA is hard if not impossible.
Audiences assembled by third-party providers who own content fortresses (think Facebook, Reddit, Snap, Twitter, and others) could still work for targeting, but you won’t get specific data on them, of course.
Privacy-safe targeting alternatives like Topics API in Google’s Privacy Sandbox for Android are additional potential options (though, obviously, not in this case on iOS).
9. Don’t (necessarily) pull learnings from Android
It’s tempting to test on Android, where you still have full GAID access, and use those learnings on iOS. This is potentially interesting, for example, in terms of creative strategy.
However, don’t assume it applies to iOS:
“We were relying a lot on Android to start with, but then since we’ve noticed that the same hero creatives don’t necessarily work both on iOS and Android. So that used to be something that historically was true to us, but we noticed that it’s no longer necessarily that way, so we’re trying to move creative testing more into iOS as well.”
Ann-Marie Pelkonen
Looks like you’ll need to use some of those campaign identifiers in SKAN for creative, or lean on partners’ use of them. The good news: SKAN 4, with more granularity, is coming.
10. Leverage opt-in data
It may be scarce, but don’t abandon IDFA data just because it’s more challenging to get. You should still be asking for permission to track — and providing good reasons why — simply because this is an important additional source of data to help you check assumptions.
“We try to use opt-in data as well. We try to use it to validate if our revenue attribution is looking reasonable.”
Erlin Gulbenkoglu
Don’t expect too much: note that Erlin says “try to use.”
But any data which is both deterministic and granular can be a big help, and some apps achieve opt-in rates exceeding 60%. That’s probably not your experience, as it is an outlier. Any data you do get, however, is helpful, and even if it’s only 10%, that can be a good survey sample size to test assumptions and check SKAN data.
Watch the whole webinar (and check out our upcoming SKAN 4 deep dive)
The entire webinar is available on-demand, for free, right here. I highly recommend you check it out.
In addition, as you know, Apple teased SKAN v 4 at WWDC just recently. This week I’ll be doing a deep dive into SKAN v4 with Singular CEO Gadi Eliashiv. We’ll be talking about:
Crowd anonymity
The new Source ID
New conversion value types
Multiple postbacks (3 in all)
New timer behavior
Cohorts
Web to app support
Conversion values for the postbacks #2 and #3
Modeling missing data
Fraud
Ecosystem changes
Testing set-ups
And more …
Join us for this webinar. I’m pretty sure it’s going to be both extremely enjoyable and extremely informative!