SKAN 4: 14 things we know so far (or think we do)
We don’t have a SKAN 4 spec yet.
We don’t have code to play with and test.
We do have a few short videos from Apple’s Worldwide Developer Conference and a few answers and hints from Apple in a few developer-focused Slack channels. Based on that, here’s what we know — or think we know — about SKAdNetwork version 4.
1. Crowd anonymity
In the past (errr, right now) we had privacy thresholds. Now Apple’s talking about crowd anonymity. The basic idea, of course, is simple: hiding individuals in crowds.
Crowd anonymity is the first thing Apple defined in the SKAN 4 WWDC session. It seems to be based on number of installs, based on what Apple shared, and that makes sense from what we know of SKAdNetwork today. In iOS 14.5 and later, the App Store asks Apple whether or not to censor at the time of install, not at the time of determining a conversion value, and we’re assuming that will continue.
It also makes sense because deciding crowd anonymity measurement impact at time of conversion value would be much more complicated.
2. Campaign ID expansion to 4 digits (and re-naming to Source ID)
SKAN 3 had a 100-campaign limit: 0 to 99, as mobile marketers know all too well. Now that Campaign ID field is changing to a Source ID field, and the range is going from 2 digits to 4. So you might think you’re getting 10,000 campaigns … but not really.
What you’re actually getting is 3 levels of hierarchy that represent increasing richness of data. But how much you get in postback #1 (yes, it’s only possible to get up to 4 digits for the first postback, not for the second or third) depends completely on whether or not Apple determines that the requirements of crowd anonymity are satisfied.

In that first postback, you could get
- 2 digits
- 3 digits
- or 4 digits
If there were enough installs from a particular source, you’ll get all the values. If you do, you can choose to use them for different sets of data
- campaigns + geo
- campaigns + network
- ad type
- ad location on screen
- and so on …
So, you get the potential for 4 digits of campaign data, but you’re not getting more campaigns, necessarily. BUT … you can decide how you use the extra digits, and you can decide to pack more dollars into specific partners to (hopefully) ensure you get four digits, and therefore you could theoretically measure just about anything you want in your additional digits, including:
- Creative
- Additional campaign IDs
- Data you can use to reconstruct cohorts
- And more …
Testing will reveal all when SKAN 4 launches, presumably around November of this year, and (it wouldn’t surprise me) in some form of public beta.
3. Coarse conversion value type in SKAN 4
There’s a new conversion type in town and it’s a little rough around the edges (sorry). Coarse conversion types are new and designated primarily for the second and third postbacks that SKAN 4 will now provide.
Coarse conversion values are always going to be just 1 of 3 possible values:
- 0, 1, 2
- Bad, OK, Good
- Buyer, Subscriber, Window-shopper
- Basically … any values you might want to assign
In the past, you either got a conversion value or not: 2 options. Now, with 2 types of conversion values (the first postback can have a fine value with more data, as explained above), you can get 3 possibilities:
- Nothing
- A course conversion value
- A fine conversion value (on the first postback only)
A coarse conversion type obviously won’t provide a ton of data. However, it can still be extremely valuable. Think subscription apps, where you might get a conversion to a trial, but only 30-40% of trials convert to paid customers. As Thomas Petit told me in a Mobile Heroes Uncensored podcast, now you can design conversion values that report what happens after the trial — something that was impossible in SKAN 3.
4. How crowd anonymity and conversion values will interface
Clearly we don’t have the full specification yet but the early indication is that crowd anonymity is about number of installs, not number or variety of conversion values. That’s good news because if all the various permutations of conversion values were censored or not depending on how many of them exist, that could get very complicated indeed. And, of course, vastly reduce the number of conversion values marketers get.
Ultimately, however, this is a TBD until we have a chance to evaluate the specifications and also, likely test SKAN 4 in the real world.
5. Postback timers for all 3 postbacks
One of the many challenging aspects of SKAN 3 is the random timer which ensures you get postbacks at indeterminate times. In SKAN 4, of course, you’ll get three postbacks which can each be set (and updated) in a very specific period of time, and sent at the end of that time.
- Postback 1: set in the first 0-2 days
- Sent after 2 days
- Postback 2: set on day 3-7
- Sent after 7 days
- Postback 3: set from 8-35 days
- Sent after 35 days

This alone will have a significant impact on the industry. Facebook, along with other adtech partners, have essentially required the industry to get SKAdNetwork 3 postbacks as soon as possible … within 24 hours (plus the random timer in SKAN 3).
Now the earliest you can get a postback is 2 days, although we think Apple will add some degree of randomness to this and not just trigger every postback exactly 48 hours after its install. If that’s true, postback 1 might come in 50 hours, or 55, or 60. Postback 2 might come in a week and 3 hours, and so on.
6. No fine conversion values for postbacks 2 and 3, and no guarantee of postbacks 2 and 3
This is an interesting design decision. Obviously, most marketers would like as much data as possible, and if fine conversion values are available for postback 1, they’d like them for postback 2 and postback 3 as well.
However, instead of the limited amount of data you can pack into 2 digits (if you have low volume) and the additional, richer data you can add if you get 4 digital (with increased volume), you’ll only get the three values postbacks 2 and 3.
In addition, just because you get a postback in the first slot for a particular install, that does not mean you’ll automatically get a second and third.
This all has some implications:
- This is going to be challenging for app publishers who have major retention challenges
- Scaling spend with specific publishers is going to a popular way to maximize data
- Spending more for quality users/players/customers is going to give you better marketing measurement data than spraying and praying with poor quality ad partners
In addition …
Getting a second and third postback, if you can get them, will still be usable to help calculate D7 ROAS (or should we now say D8 ROAS). It’s just a lot more complex than it used to be, with a lot more data science required, and correlation with IDFV data and in-app data.
7. No, 3 postbacks from (potentially) the same user don’t mean you have a user/customer journey
One thing I thought briefly when I saw Apple’s presentation is that the postbacks would be correlated: one person installs your app, and you get:
- Postback 1 for that person
- Postback 2 for that person
- Postback 3 for that person
However, I was dreaming, and quickly woke up. Getting 3 correlated postbacks for a particular person would clearly be exploitable to create a privacy breach.
You’ll know which postback you’re getting, and you’ll know what the Source ID is so you can get campaign information, but they are not connected via any kind of user ID. What that means, clearly, is that each set of postbacks should be seen as aggregate measures of a campaign within a range of time.
It’s still good information, but it’s not a user or customer journey.
8. Conversion values can go down, not just up in SKAN 4
In SKAN 4, conversion values can go down, not just up. That’s potentially extremely useful: you could have players/customers/users who look great at or shortly after install, but soon show sure-fire signs of not being monetizable soon after. Now you can account for these.
For instance, someone might create an account in a finance app, which is a high-intent signal, but perhaps they don’t fund it or connect a bank account or credit card. Or a player in a battle game might eat up levels 1-6 but get stopped in their tracks at the boss level 7. They might look at an in-app purchase option, but don’t buy, don’t join a clan, don’t watch a tutorial, and don’t watch a rewarded ad to get a power-up.
Now you can find that out.
A few implications:
- This is a significant logic change
- It changes how we think of D1/D3/D7/D30 cohorts and models
- It allows you to have more types of conversion models
- And, of course, it brings additional complexity
9. SKAN 4 has more data for modeled cohorts
For SKAN 3, out now, Singular released SKAN Advanced Analytics with modeled cohorts. Modeled cohorts combine data from multiple sources to reconstruct cohorts using IDFV (good user data, no attribution) and SKAN (attribution, but no user data).
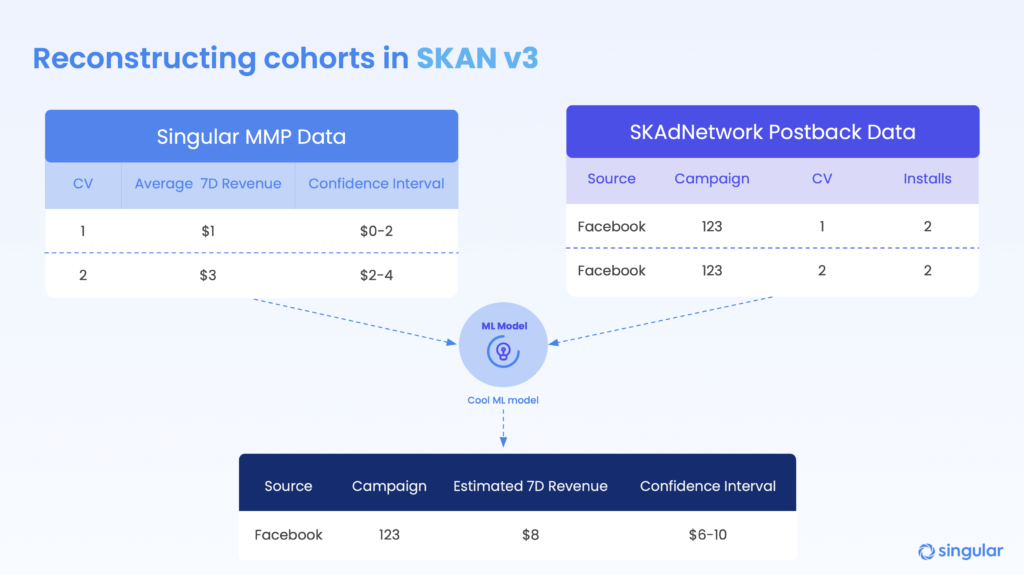
In SKAN 4 there’s simply going to be more data, more signals for the model … and more complexity. But the end result should be more accurate. The key will be how you use the second and third conversion values effectively, and whether you get them.
10. In SKAN 4, you have to think about more measurement windows
SKAN 3 just has one postback that you typically wanted in a day, although technically you could extend it much farther out in time.
In SKAN 4, you can set a conversion value for postback 1 at any time up until the end of day 2. You can also update it both up and down at any point during that time. And the same is true for postbacks 2 and 3, even though they obviously don’t offer the same amount of potential data richness as postback 1.
This could get confusing.
First, your app or your measurement SDK needs to measure time. It needs to know which window you’re in and act accordingly. Then it needs to set a useful conversion value … which can change. There are going to be some complexities here: marketers are already struggling with SKAN 3 and its single conversion value.
11. Your SKAN 4 postback strategy might differ based on your vertical and your goals
Apple’s told us you’ll get coarse conversion values much easier than fine.
Some marketers in verticals like hypercasual games might think they can get away with coarse conversion values only — especially in a testing phase — and spread budget thinner among more partners and more campaigns. Then, when you hit pockets of success identified by the coarse conversion values that you really want returning in postback 1, you might double down, concentrate spend, and attempt to get more detailed measurement and optimization data.
But in retail or subscription apps, you might need more data right at the beginning, and might therefore not choose to cast as wide a net in testing.
12. You’ll still need data modeling for missing data
SKAN 4 offers more data than SKAN 3 … we think.
But we actually don’t really know for sure if the fine conversion values in SKAN 4 activate at similar levels to the only conversion option in SKAN 3, which would mean more data … or if Apple will provide only coarse conversions in SKAN 4 at the current privacy threshold/crowd anonymity level of the single postback in SKAN 3 … and fine conversion values will take additional app install scale.
Either way, you’re going to be missing data.
And either way, you’re going to need modeled data to replace it. You’re still going to have a lot of missing data, whether it’s from postback 1, or 2, or 3. The good news is that now we have more data points to use in modeling, which should improve accuracy.
13. Fraud is still a question mark in SKAN 4
Something we haven’t talked a lot about with regard to SKAN is fraud. SKAN 4 will bring some additional challenges.
There are 2 ways to report touchpoints: clicks and impressions. Clicks lead to the app store, so that’s secure, but impressions do not. Which means that any app can report impressions all the time and potentially take credit for organic installs.
Apple is aware of this and knows it’s a gap, but it’s not clear what they can or will do about it.
14. There will be multiple SKAN versions live in the wild
The ecosystem will be at different levels of support initially, but so will phones. Some people don’t update their mobile operating systems quickly; some can’t because they’re using older handsets.
That means that publishers and adtech providers will either have to support everything, or pick and choose what they support, or support the newest version and try to maintain compatibility with older versions of SKAdNetwork.
Possibly Apple will have more to say here about the device side, but Apple can’t typically force people to update their phones.
So … brace yourself.
More questions? 27 questions answered
We received more questions in our SKAN 4 webinar than any other in my recollection, and while we couldn’t answer them live, we did answer them in a blog post afterwards. So check that out for additional information:
SKAN v4: 27 questions answered

Stay up to date on the latest happenings in digital marketing

