70% of mobile games are built in Unity, says CEO John Riccitiello. And he thinks that generative AI in gaming is going to double or triple the size of the industry, returning the games to the growth days of when 2D shifted to 3D, or what we saw with the introduction of the internet.
Why?
Even more mind-blowing experiences.
“These worlds, when they’re built, will be so compelling,” Riccitiello says. “this is what we’ve been dreaming about since we watched our first Star Trek episode … imagine the holodeck. We’ve been wanting this for a very long time. We’re gonna get it.”
We’re already seeing the massive impact generative AI is having in text generation. Image generation. Video generation. Code generation. Document summarization. Test-taking … whether it’s passing the bar to become a lawyer or the tests you need to take to become a doctor. There’s a $1.3 trillion generative AI boom in just 3 industries — banking, retail, and high tech — and generative AI will unleash the next wave of productivity, says McKinsey, adding up to $4.4 trillion in economic growth annually: more than the UK’s entire GDP.
Generative AI in gaming
Generative AI in gaming looks like help generating art, help creating code, help creating story and dialog, and much more. Especially when you take generative AI from the development studio and insert it into real-time gameplay.
In most games, you realize you’re in a scripted world with severe limitations pretty quickly, Riccitiello says. Even though it’s “still the most compelling form of entertainment in the world,” it has its limits. Insert generative AI into gaming, and that changes pretty quickly.
Think NPCs
“Imagine … that each one of these characters could be as smart as ChatGPT and talk to you about anything,” Riccitiello says.
In FIFA, you can chat with the fans, face off with a heckler, chat up a hot admirer. In GTA, you could talk to the liquor store clerk and get his insights on driving, violence, and crime. In Call of Duty, the soldier in your foxhole now has a whole history, perspective, and character.
The options are endless.
And so are the worlds, which can become truly endless and unbounded, and actually unique to each player and each player’s experience, history, and actions.
“I think this is 10x the potential transformation because I don’t think anybody looks at their games and thinks of them as real worlds. They’re sort of scripted fantasy worlds,” says Riccitiello. “We’re about to find out what happens when we make these worlds fully alive.”
Project Barracuda
One of the technologies Unity is offering: Barracuda.
Unity has been working on it for over 5 years, and bundles an AI model inside the runtime in anyone’s device, whether on smartphone or console or PC. That runtime is now in over 4 billion devices globally, and what it means is that the computational costs of generative AI — which can be massive — are distributed to each user rather than borne by the game publisher.
Why’d Unity start building this over 5 years ago?
“Sometimes it’s better to be lucky than good,” says Riccitiello.
Subscribe to Growth Masterminds
We chat about much, much more. Subscribe to Growth Masterminds in your favorite podcast app as well as on YouTube, and listen in as we discuss:
- What Unity is doing for generative AI in gaming (and elsewhere)
- How developers will work with generative AI
- The productivity gains we’ll see with generative AI
- Why generative AI won’t just create whole games for us
- What’s faster when NOT using generative AI
- Making games infinite
- Making NPCs smart
- Overall growth of the gaming industry despite a downturn
- And more …
Full transcript: Unity’s vision for generative AI in games
John Koetsier:
How will generative AI change gaming?
Hello and welcome to TechFirst. My name is John Koetsier.
No surprise to anybody, generative AI is the hottest thing in tech right now and that might even be especially the case in gaming. Well guess what? Games are hard. They’re incredibly challenging to create. There’s images, video, sounds, objects, characters, dialogue and code itself. All of which can be built faster, cheaper, if not always better, by AI.
Roblox is doing generative AI, Meta is doing generative AI for the Metaverse if that’s not canceled yet. Microsoft is testing generative AI for Minecraft. What is Unity gonna do?
To find out, we’re chatting with Unity CEO, John Riccitiello. He’s an OG in gaming, former CEO of Electronic Arts, long history in business, led companies like Haagen-Dazs and Pepsi and I think this is the third time we’re chatting. Welcome, John.
John Riccitiello:
Well, it’s great to be here and good morning, John.
John Koetsier:
Good morning. Excellent. Love the art behind you. Love the topic as well, generative AI. Let’s start with the big picture. What is Unity doing in generative AI?
John Riccitiello:
It’s hard to say what we’re not doing, actually.
John Koetsier:
Good.
John Riccitiello:
Let me focus it for you. So, you know people think of Unity as doing two things in our business. One is helping creators create games or digital twins. So we’re a content creation platform. And the second is we’re a platform for helping people operate and monetize their games and other applications.
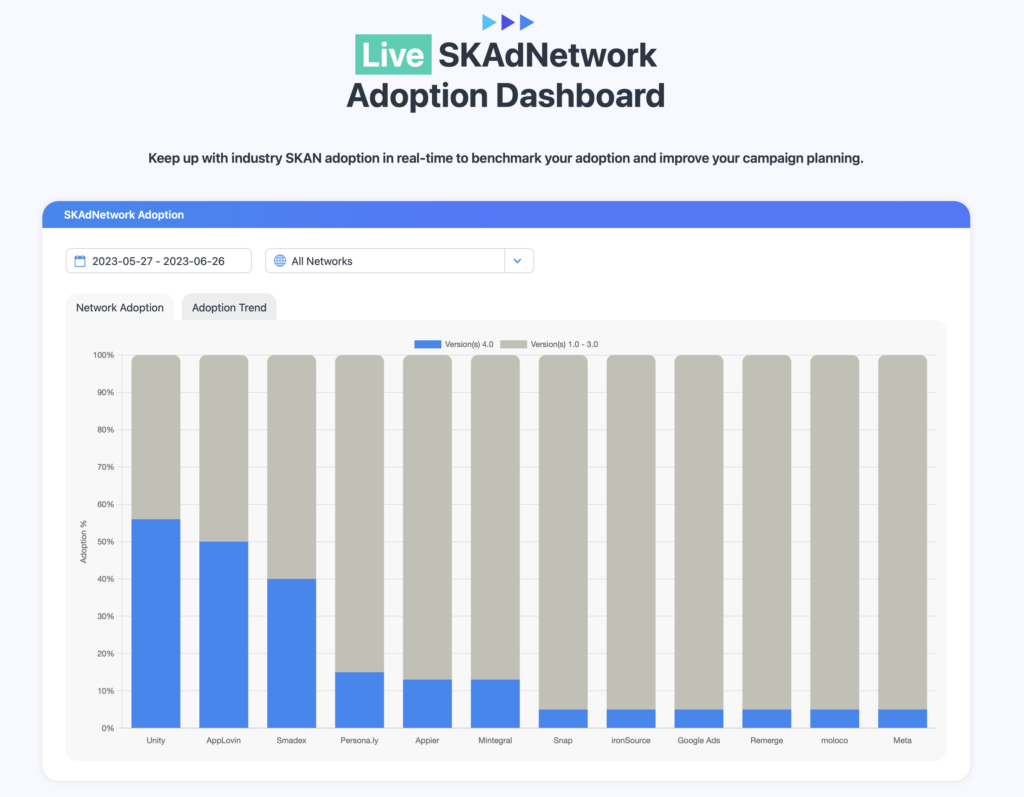
And, you know, we’re the leader in both spaces. So, we’re the benchmark, if you will. Now well over half in mobile, over 70% of games are built in Unity. I’m very proud of that.
We’ve been doing AI in that space for several years now. And so there are lots of tools inside of Unity that enable people to leverage the best of what AI can offer to advance or accelerate or to improve upon the output that they’re trying to get to, the content they’re trying to build.
And that lives within our Weta tool chain where most of those tools wouldn’t be possible without components of AI. And it lives within Unity, the tools we use for facial animation and all sorts of things. I’ll talk to you about where that goes, but we’ve been at that for a long time.
It also lives with our Operate side of the business. We’ve been using neural networks for three years to help developers find users, do it more cost efficiently, to deepen the engagement of their audience. Again, for us this is not a new subject. It started before OpenAI started, before ChatGPT was sort of on the forefront of everyone’s conversation and thought process. And we’re doing a lot more.
And what I think might be interesting to talk about is where that goes for content creators, the winners and losers and such. But also, I’m going to talk to you, one of the first people I’m going to talk to, about how some of what we’re doing will change the very nature of what a game is and make it a lot more compelling. And I would argue in many ways something that feels so alive that maybe we prove out the thesis that we’re living in a simulation, because we create one that’s every bit as believable as the world we live in today.
John Koetsier:
So there’s a lot to unpack in what you just said there, because what I think you’re saying is that, hey, not only have we been using AI for a long time, we’re going to be using AI a lot and generative AI to help people make games in a lot of different ways, but also we’re putting that into the gaming experience so that it’s real time. There’s real time generative AI happening for maybe dialogue, maybe settings, environments, maybe objects. Did I hear that correctly?
John Riccitiello:
More than the art. Let’s tackle the first part, the creation side, maybe, and then we’ll come on to the worlds that you could build. So I’m sure you and many of your viewers have used tools like ChatGPT or some of the generative art, the hugging face type of things to I wanna see a girl on a bike in the style of Van Gogh or whatever. But when you’re using it, for example, to help you write something, what are you doing? You put in a prompt and you get something back. And then ultimately you take that something you got back and you move it into a Word Doc or a Google Doc or something and then you edit it and make it your own.
So, defining a couple terms, you’re using a natural language, large language model when you’re doing the first step. You’re using a deterministic tool to make it precise, to make it what you want it to be. And you’re iterating back and forth. Now, I think that’s going to be true for animators, character artists, level designers, lighting people, physics people. They’re going to be a lot more productive because they’re going to continue to use deterministic tools because they need to… you can’t publish the outgrowth of an AI tool. I’m going to dig into that a little bit more in a minute. But they can be two times or three times or ten times more productive using the combination.
And that’s how I see this going for most creation. And it’s how the tools are used today.
Now, the difference between, say, a Unity and Word or a Google Doc is pretty profound, though. And so a large language model, whether it’s studying photos or paintings or books or articles, whatever, to crunch, you know, dialogue or scripts, on what it’s studying, the model itself sees everything if it just has the frame. So if it sees the script, it knows all the words. If it sees the painting, it knows all the pixels. Even if it looks at a movie, and right now we’re not at a point where we’re creating efficiently with any of these models’ film, if it sees the 20 frames a second that is on television or film, it’s got all of the data.
Games are profoundly different than that. You use, I don’t know, we’re playing Call of Duty, you know, you who had X hit me in the shoulder, I duck. Think about what’s going on there. I get hit in the shoulder, my ragdoll physics, I fall to the floor. There’s your input, there’s my input. There’s all that content that is in fact in the frames, in this case, 60 frames a second.
Then, underneath that, there’s the instructions for lighting, there’s instructions for all those interactions. And for a model to study that, all it really sees is the frames. But there’s a boatload of information that made those frames possible.
So my sense is, well, while these models will eventually produce simple games, you know, the Flappy Birds of the world, I think the rich and complex things are gonna be very hard for these models to produce for a bunch of reasons. One is they can’t study all the data. The second thing, but I’m going to tell you why we can’t, but they can’t study all the data. And they also kind of skipped the point that you’ve got 100 people or 20 people or 10 people working on a product together and it’s a wildly iterative process.
John Koetsier:
Mm-mm.
John Riccitiello:
Trying to get from it looks like this, how to make it fun, how to make it more engaging and that iterative process for creation that’s existed since literally the beginning of art. People would sketch what they’re going to paint and then sketch it 15 more times. That iterative process, the very process of creation, especially in teams, is always hugely iterative. Those things you can’t just simply, I’ll give you a prompt and we get a product back.
So Unity is by far the largest and most used editor in the world for creating games. And we’ve already got a bunch of AI tools in our product and we’re going to be introducing… more and more natural language interfaces so you can talk to it and get that juicy, lovely relationship between I get a first draft from something that’s non-deterministic, then I edit it to make it better.
So, to give you an example, I might want to tell it to give me a character that looks like X or an environment that’s got trees, and that’d be great, but then I’m imagining a war over those trees or using that character. I want to move the river over. Okay, so now, so you might get a first draft and you’re over here on editing and then you edit this, you go back and forth. But now let’s assume that I want fog. All right, now everything uses fog, right?
It’s like, part of the melodrama of entertainment is all those beautiful foggy intersections with life and it helps people build a better story. I wouldn’t even know how to describe fog, to be honest with you, but within Unity, the deterministic tools are a bunch of sliders. It gets thicker and thinner, more reflective, non-reflective. It takes a second. Do I want to talk to a natural language thing for like a week to figure out how to describe it, or just make it in a second?
And the workflow I imagine that is going to replace the one that most people use today is that brilliant accelerant, the power that a creator can have, where natural language gets them half the way there. Then they do something over here to make it a little bit better and then they go back over here to close the gap. And then they’ve got it, and they’ve got a build of their game. And then it isn’t fun. And so when they go back and the team edits it and makes changes, and that iterative process is one that I don’t think goes away, I just think that creators are gonna be two to 10 times more productive than they’ve ever been before, which will open all sorts of frontiers for cool new stuff.
John Koetsier:
There’s some really good news in what you’re saying and in how you’re framing it because there’s a lot of concern that AI will cost jobs, and in some cases it will and hopefully open up many other jobs as well. But you have Dropbox CEO saying that we’re in the age of AI that’s one of the reasons why we let go of 500 people, right?
But what’s interesting about what you’re saying is that it gives you superpowers. And what comes to my mind, I believe it was Red Dead Redemption or maybe it was No Man’s Sky, one of the two. It was a game that was massive in scale and scope for the world and the universe. And it took eight years for hundreds of artists. They had literally 100 musicians scoring all the music that was used in it. And it took eight years to get this game off the floor.
And how much does the world change? How much does technology change? How much do our tastes change? Eight years and how much investment do you have if you’re building this triple-A game for eight years and you don’t even know if you’re going to get some ROI on it.
And so what I’m hearing and what you’re saying is there’s a lot of tools. That is going to speed up… I need some music, I need a character, I need an object, other things like that that you can work with. That’s interesting, that’s good, because then it’s an interplay between a person, a creator, an intelligent designer, developer, and the machine. So that’s cool.
The other thing that’s interesting is that a lot of generative AI that is visual is 2D. There’s not a ton that’s 3D. And as you said, not any, perhaps, that understands the interplay, the rules of the universe in a particular game, the rules of what can happen or not happen, why things are happening, what’s going on.
It’s interesting to imagine a generative AI built within the Unity environment, understanding the physics and other things and the fog and other things like that and the capabilities that you could have in that world.
John Riccitiello:
You make some really interesting points. First off, I wasn’t involved in the production of either Red Dead or No Man’s Sky. But if I recall press at the time, I believe they were, they’re both giant worlds, but I believe they actually use very different methodologies for creating their environments. Red Dead, I believe, was actually quite a traditional process, you know, artists drawing environments. I believe, no matter what you do, most of the environments were algorithmically created.
I remember at the time, there were some really beautiful things that were algorithmically created, but there was also some comment about how it felt a little lifeless. In a weird sort of way, dead straight up, sort of lacking humanity. I don’t know if that’s actually a legitimate way of looking at it, but I do believe they had different ways of getting it. I do remember some of the criticism.
Now, within this world, I think, you make the point that humans are going to be involved. 100% agree. And, you know, one of the things that we tell you is I don’t think in this world where, you know, we live at the bleeding edge of the most interesting entertainment media in the world and the content creation end of it, I don’t think anybody’s job in this world, in the creation side, is going to be taken by an AI. But it will get taken by a human using AI. Because those people are going to be more productive, and they’re going to have to be, you know, they’re going to just force multiply their ability to realize what they can conceive.
Now, you know, within that added productivity, remember the most successful games are multi-billion dollar franchises. And at least what I’ve witnessed in the quarter of a century I’ve been working on building games, which is… a frightening thought right there, is that… given the size of the prize, the most important developers on the planet will put anything in terms of effort and spend to make their product better and more compelling.
And so my expectation is these ambitious companies are going to use AI to make things even more entertaining and more engaging than it was ever possible before. But you know, maybe that’s a good pivot to what might be possible. more is possible that heretofore wasn’t even imaginable. And I think that’s a super interesting subject.
John Koetsier:
Mm-hmm. Let’s talk about that. And I also want to get to the marketplace, so let’s not forget that piece as well. But let’s talk about that in-game experience. We’ve grown up with games, right? And the dialogue, for one thing, is very stilted, sometimes inappropriate, just doesn’t fit the situation. You’ve got the Jumanji movies, right, where they’re in the game environment, and they get the same guy saying the same thing every single time, doesn’t get it. Imagine something like ChatGPT hooked up to characters who are NPCs that don’t feel like NPCs. Talk about what you’re thinking about for in-game experiences that are powered by AI.
John Riccitiello:
So I’m going to describe to you something beautiful that is going to be both too expensive and virtually impossible to make work, and then I’m going to bridge it to tell you how it actually can work.
So, virtually every game… not every game, but you know if you play a MOBA this isn’t true because there’s no non-player characters or they’re not a lot of non-player characters… but most games have lots of non-player game characters and then we interact with them and somebody wrote every line of dialogue. They wrote every bit of animation and it very quickly becomes repetitive.
And, you know, if you’re playing GTA for example, and you pull over to rob a liquor store, the writers, in this case, it was probably Dan Howser, if you go back and audition in the title, he and his team will have imagined, you know, ten interactions and each one has a line of dialogue. Maybe the clerk fights you or the clerk just gives you the money or the clerk runs away and they’ve anticipated that and then they wrote dialogue for that. That’s fine.
And if you’re playing a war game and you’ve got all these NPCs and you’re trying to get to another place in the city but these guys are fighting you off and getting in the way, somebody wrote very simple rules around what those things are. Go left, go left, go right, go right, go right, go left. Maybe they respond, if you go right, they go left. But they’ve written a collection of rules and it doesn’t often take all that much effort to figure out the seams. And you realize you’re in a scripted world with severe limitations pretty quickly. Now it’s still the most compelling form of entertainment in the world, but it has its limits.
And so… what we imagine when we look at AI today is that each one of these characters could be as smart as ChatGPT and talk to you about anything. You could walk from the pitch to the stadium in FIFA and talk to the fans. What do you think? Hey, come out in the pitch and play with me. They can not only talk, you know, a new game, but they can also act in a new way.
Now, if you could imbue those NPCs with all that, you know, seeming intelligence of a large language model, both in action and in dialogue, you’d have a staggeringly interesting world to live in and play in. And one of the things that would be the first thing a developer would need to do, they put all this intelligence in their games, is now we have these beta periods to iron out the bugs.
We’re going to need a beta period to train all the NPCs, you know, OpenAI and ChatGPT. Really the first few million people trying to get to be infinitely smarter in terms of how a human would judge it. The first million players playing that game, messing around with it for a couple of days, those NPCs would go from sort of feeling off the reservation to being entirely alive.
And it would be a combination of what the company that developed the game wrote for the backstory, like who is this character? What are these characters, you know, human or non-male, female, whatever gender, whatever they put in there for, it’s ambition. So, back to that GTA liquor store clerk, is he or she a meth addict that’s just trying to make enough for whatever the expression is that they would buy at the end of the day, I’m not in that market? Or are they on summer vacation from an Ivy League school? And they might have a different orientation to what it means to be worth living for, right? So they might behave differently.
And so you could imagine almost anything happening with that range of choice, but the creator will write that for all of them. Less than the dialogue, less than the interaction, they’ll write that, but they will imbue it with … a learning algorithm that will train it to achieve what it needs to achieve and maybe a game will take a month of doing this. By the way, I would love to be a beta tester when it’s off the reservation, getting it on the reservation, because that would be so much fun too.
These worlds, when they’re built, will be so compelling, in my view, that it’s going to drive a growth spurt in gaming that, like the likes of which we haven’t seen since 2D became 3D or we saw the internet or we saw mobile. Those are all done, double-triple the industry in a short period of time, this is gonna do that again, because this is what we’ve been dreaming about since we watched our first Star Trek episode in Imagine the Holodeck. We’ve been wanting this for a very long time. We’re gonna get it.
Now the problem, this is the almost insurmountable problem, but I have a surmount of that problem for you, is that right now, all of that capability is on a server someplace. So you have latency issues and you have cost. Nobody really wants to, you know, we’ve all read about how much money OpenAI has invested with Microsoft to run all of that.
And this is where sometimes it’s better to be lucky than good, but over five years ago, I was with one of my colleagues, Silvio Druin, and we were talking about AI then, like a lot of people talk about it now. And we decided to start a project to see if we could get an inference engine, a learning AI tool, in Unity’s runtime. And the runtime ships with every game. It’s what drives all of the movement and dialogue and the effects. It takes the creator’s content and turns it into interactive content.
And we decided to start working on that over five years ago. We had lots of ups and downs. We ultimately built it. We call it Project Barracuda. And what that allows is the runtime that’s on the device, on your iPhone or Android device or PC or console, that runtime can now have essentially an AI model inside of it to drive those things. So it can be done locally. So as those actions are driven locally, it doesn’t cost anything.
And it happens fast. And we’re unique in the world of having done that. And look, I’ve started a lot of things, didn’t turn out to be quite so prescient. So I’m not gonna claim that I’m a seer of all things. Got lucky on this one. We kept it alive when there wasn’t an obvious use for it because we thought it would be useful. We didn’t know exactly what for.
But now, as we look at our business around digital twins where they’re gonna want to go from reporting the past to asking about fixing the problem, as opposed to just reporting it.
Or we were thinking about games that could be smart and alive, like I’ve just described, I can’t wait to play the games that the better creators make that are … it may be more interesting than my friends to hang out with. I mean, apology friends if you happen to be listening.
John Koetsier:
The mind boggles on a lot of different levels there. First of all, having quote-unquote NPCs that are seemingly super intelligent, powered by AI, is incredible. You could meet that clerk that you are going to rob and have a conversation about the meaning of life. You could be in a foxhole with a soldier in Call of Duty and, well, this is my girlfriend and she just broke up with me and here’s the letters. You could have those kinds of human engagements and interactions in a game and it could be powered there.
And you know what? The nice thing is that people have supercomputers in their pockets. They’ve got supercomputers in their console so they can run that kind of power.
John Riccitiello:
And the deposit is picked up on four billion of those today. My runtime is already on them. And so the deployment already exists. And so against that deployment, what we need is … I don’t know how long you’ve been a student of the game industry, but I remember when I was a kid in my parents’ living room playing Pong. But it’s always been the case that there’s like a substantial innovation and then there’s a lot of followers.
And I remember calling Sam Houser when I was playing GTA 3, thinking this is the first open world game I played. I know a lot of times it sort of felt open, but this was the first one I could drive, I could fire it, I could shoot, I could hold up a liquor store. I could do anything I wanted to do. Some things I won’t tell you in live interview format that you could do. And I remember thinking, this changes everything. And it did.
And so many games have now moved on to that model of an open world because of the freedom that players feel in the environment. And, you know, that was to me a super important milestone in the industry and I was so impressed by the work.
I think this is 10x the potential transformation because I don’t think anybody looks at their games and thinks of them as real worlds. They’re sort of scripted fantasy worlds, whether you’re playing an RPG like Dragon Age or a sports game or an open world environment like a GTA or you’re playing an endless wonder. Whatever you’re playing, you know, they’re great. But what has happened is the creators have basically taken the long set of rules that we used to read for board games and transformed them into real-time 3D. But they’re still constraints in rules. And we’re about to find out what happens when we make these worlds fully alive in the… in terms of how it feels to the player. I can’t wait.
John Koetsier:
Unleashing games and unbounding games. That is super interesting. I do want to hit on the marketplace. You’ve talked about that and the news that you released I think something like a month ago or so is you will have an AI marketplace or a marketplace for objects that people have created with generative AI. It reminded me a little bit of people made a living on Second Life making clothing and other objects and stuff like that. People made six figure salaries there. Talk about what you’re doing with the marketplace and how that fits.
John Riccitiello:
Well, first off, Unity’s had an asset store for over a decade. And more people make a living in the Asset Store, creating assets and characters and particle effects and all sorts of different things that plug into Unity already. So the marketplace exists for… and virtually nobody, maybe some very large companies, but most game companies, either at prototype stage or through production, end up getting a lot of things out of the Asset Store from these entrepreneurs that have built really cool things.
And, I don’t know if you’re building a real-time strategy game and you’ve got some sort of a unit out there that might be a fortress or whatever it happens to be, depending on the fiction of the game, and you want that thing to blow up, all right, and you want to have dust clouds and flames and other stuff when it blows. I mean, because it’s kind of fun. Like you’ve blown it up and you wanna see it, you don’t wanna see it disappear, like say, somebody taking a chess piece off the table. You wanna see it melted, broken, and now a team of 10 can spend a month, or a couple weeks maybe, drawing and animating all of those effects.
They go to the Asset Store, they get paid 20 bucks, it’s done. And so that’s what they’ve been using the Asset Store now for years. And the point that we wanted to make with the Asset Store here, and we’re working with a large number of AI startups and larger skill companies, is that Unity has the largest number of 3D real-time creators on the planet by orders of magnitude. It’s a gigantic audience of creators.
And we’ve already got a business, and always people have a business catering to that audience so they can build faster. And we’re building and have built a number of AI tools. But we don’t think we’re the only people in the world building AI tools for 3D creation. We think there’s a lot of smart people out there, lots of them. And what we want to facilitate is for a simple API connection or a quick install of an SDK, whatever, depending on the product and the service being offered, that just happens quickly and easily inside of the environment people are already using to build games.
You know, a lot of things take place outside of that approach too, but then they’re downloading something in their PC or whatever Mac or PC or workstation they’re using to create something. They’re running something over here, they’re trying to figure out some sort of a workflow to get it into the product or to get the outgrowth of that into the product. And that’s a cumbersome, difficult process.
It’s also really difficult for the AI startup or larger company to even find these people, right? You’ve got to go through this big marketing campaign to say, and we just want to make that easy, as we’ve always wanted to do. The intention here is to expand the marketplace very deliberately around AI tools because I think AI tools are profoundly important. We just want to do anything and everything we can to help our creators be more productive.
John Koetsier:
Cool, cool. Well, this has been super interesting. I think your outlook is calling and many other things as well. Thank you for taking this time. Really do appreciate it.
John Riccitiello:
Alright, well thanks John and have a great rest of your day and until next time.