SKAN 4 전환이 이렇게 오래 걸려 개인적으로 우울했습니다. 작은 버그 하나가 전환 값을 완전히 망가뜨립니다 전체 생태계가 위축되고 몇 달간 침체되었습니다. 하지만 나는 ’기쁩니다. 긍정적인 소식을 전합니다: 전체 포스트백 중 SKAN 4 포스트백 비율이 몇 달간 꾸준히 상승하고 있습니다.
SKAN 4 파티에 참가한 한 주요 플레이어는 누구일까요?
Reddit.
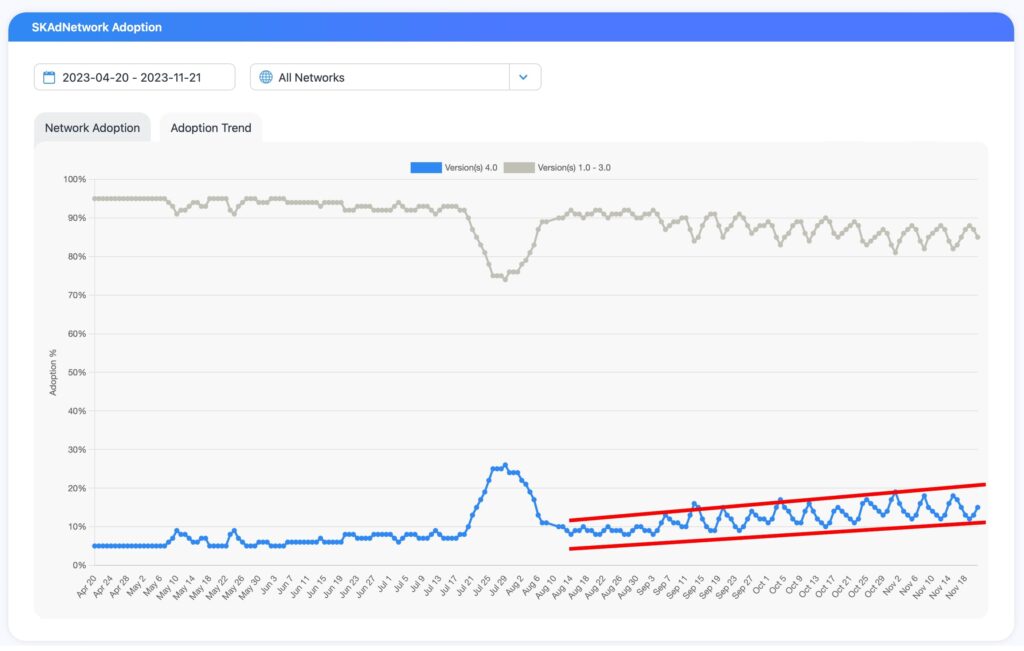
SKAN 4 사후 보고 증가 추세
먼저, 여기’는 추세선입니다. 아직 샴페인을 터뜨리지 말고, SKAN 4 IS HERE 파티를 미루세요, 하지만 8월부터 11월까지 SKAN 4 포스트백 비율이 점진적으로 상승하는 확실한 추세가 있습니다. (7월 말 큰 급증은 Meta going SKAN 4 SKAN 4 버그가 발생하기 직전이었습니다.)
그래서 무엇이 바뀌었나요?
안녕, Reddit
지난 30일, 특히 지난 주에 Reddit은 SKAN 4 포스트백 전달을 거의 90% 수준까지 급증시켰습니다. Reddit 발표했습니다 업데이트를 — 물론 — 서브레딧에 게시했으며, “SKAN 4.0 지원을 시작했고, 제품 솔루션을 한 단계 끌어올리고 파트너에게 다양한 개선 사항과 새로운 기능을 제공하게 되어 기쁩니다.”
Reddit for Business 팀이 추가한 몇 가지 사항은 다음과 같습니다
Reddit의 SKAN 보고서는 광고 그룹 수준 및 광고 수준에서 이루어지며, Reddit은 이를 통해 더 빠르게 사용자 익명성을 달성하는 데 도움이 된다고 말합니다
Reddit의 각 앱 ID는 최대 200개의 활성 광고를 가질 수 있습니다(SKAN 3의 100개에서 증가)
최대 20개의 활성 광고 그룹을 가질 수 있습니다
각 광고 그룹은 최대 10개의 활성 광고를 가질 수 있습니다
Reddit은 SKAN ID 관리를 간소화하여 새로운 광고 그룹에 사용 가능한 ID 수를 더 잘 파악할 수 있습니다.
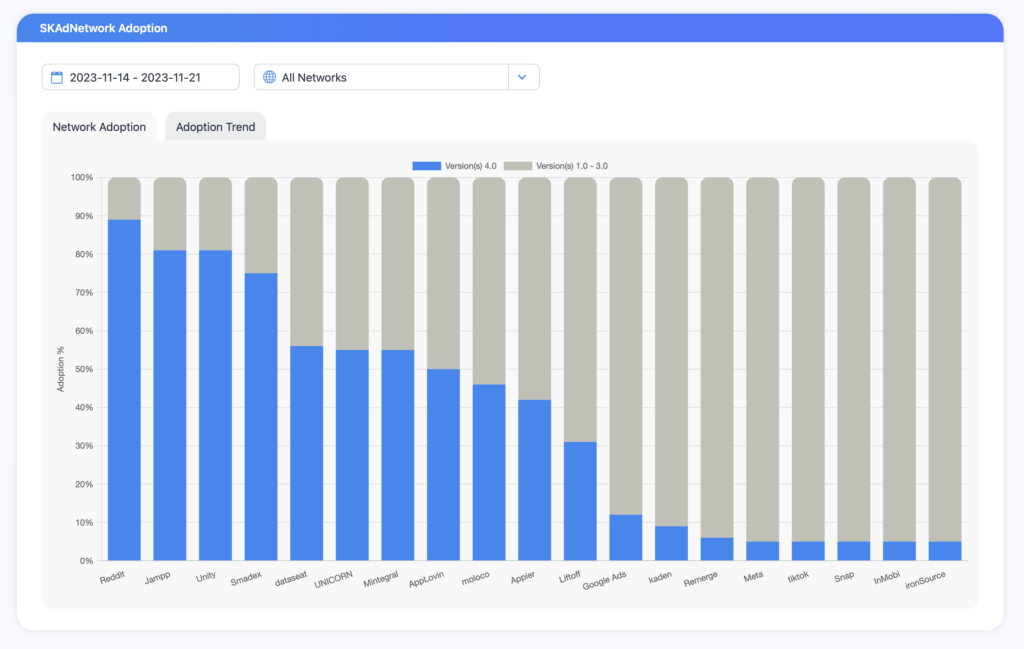
Reddit’s 움직임으로 Reddit이 이제 SKAN 4 도입을 위한 주요 플랫폼·광고 네트워크가 되었습니다. Singular’s SKAN 4 도입 대시보드.
또 다른 주요 광고 파트너는 SKAN 4 트렌드에 합류하고 있습니까?
기타 주요 광고 파트너는 다음과 같습니다:
Jammp
단일성
스마덱스
Dataseat
Unicorn
Mintegral
AppLovin
몰로코
아피어
이륙
구글 광고
Kaden
다시 나타나다
우리가 아직 보지 못한 것은 Meta가 대량으로 SKAN 4 피드백을 다시 발행하는 것입니다. Google은 여전히 테스트/보류 단계에 있으며 TikTok 및 Snap과 같은 플랫폼도 마찬가지입니다.
최근 웨비나에서 대부분의 전문가들은 SKAN 4가 2024년 1분기까지만 피드백 공유의 대다수를 차지할 것이라고 예측했습니다.
제 생각에는 생태계는 기본적으로 지금 당장 준비가 된 것 같습니다. 대부분의 iOS 기기는 SKAN 4 CV 리셋 버그 수정을 통해 업데이트되었으며, 걸림돌은 플랫폼이 SKAN 4보다 자체 모델링 결과를 우선적으로 투자하고 지원한다는 것입니다. 그들은 결국 SKAN 4로 갈 것이며, 준비가 됐을 때 스위치를 켤 것입니다. 그리고 그들의 고객이 주로 내부적으로 모델링된 수치에 의존하기를 바랍니다. SKAdNetwork보다는 말이죠.
아마도 제가 너무 비관적일지도 모릅니다.
어쨌든, 우리는 지금 상승세를 보이고 있으며, 추가적인 중소형 및 대형 광고 네트워크가 SKAN 4로 전환하기 시작함에 따라 계속해서 상승세를 보일 것으로 예상합니다.
그나저나 … SKANATHON에 참가 신청 하셨나요?
우리는 뭔가를 하고 있습니다. 그리고 정말 멋진 일입니다: SKANATHON. SKAN 4 포스트백이 상승함에 따라, 참여를 고려하는 것이 현명합니다.
SKANATHON은 2일간 진행되는 라이브 웨비나 시리즈로, 총 4개의 세션과 17명의 연사가 여러분을 2023년 SKAN 4에 대비할 수 있도록 도와드립니다.
세션 1: SKAN 리뷰 SKAN 3의 작동 원리와 활용 방법
세션 2: ASA와 ASO 애플 검색 광고 운영 및 앱 스토어 최적화를 통한 SKAN 영향 완화
세션 3: Singular’s SKAN 솔루션 업계가 보는 이유가 있습니다 Singular’s SKAN 솔루션은 iOS용 선도 측정 제품입니다. 작동 방식과 경쟁보다 더 나은 결과를 제공하는 이유를 깊이 파악하세요.
세션 4: SKAN 4 심층 분석 SKAN 4가 출시되었습니다(거의). SKAN 4의 모든 장점을 활용하는 방법을 알아보고, SKAN 3와의 하위 호환성을 유지하는 방법도 확인하세요
어떻게 SKAN 실제 세계에서 작동시키려면? … 이 비디오를 보고 시작하세요. 재생 버튼을 눌러 스크롤을 계속하세요 …
iOS용 SKAN을 제외하면 측정 옵션은 까다롭습니다. 캠페인 측정을 위해 모델링된 광고 네트워크 데이터를 사용해 볼 수도 있고, 미디어 믹스 모델링을 통해 광고 효과를 분석할 수도 있습니다. 핑거프린팅 기법을 계속 시도해 볼 수도 있고, 자사 데이터와 로직을 활용할 수도 있습니다. 사실, 여러 가지 방법을 복합적.
하지만 iOS에서는 SKAdNetwork만이 유일하게 확정적인 옵션을 제공하여 (특정 조건 하에서) 앱 설치 기여도 분석을 위한 포스트백을 받을 수 있도록 보장하고, 광고 네트워크가 캠페인 최적화에 필요한 데이터를 확보할 수 있도록 합니다. 따라서 SKAdNetwork를 사용하는 것이 합리적이며, 제대로 활용하는 방법을 배우는 것도 중요합니다.
으로 인해 데이터 손실이 너무 커지지 않도록 광고 파트너 및 캠페인을 관리합니다. 개인정보보호 기준 (SKAN 3)이나 크라우드소싱 익명성 (SKAN 4)
그래서 저는 Singular에서 가장 뛰어난 SKAN 전문가 두 명에게 실제 환경에서 SKAN을 활용하는 방법에 대해 함께 논의해 달라고 부탁했습니다. 두 전문가 모두 수백 명의 고객과 협력하여 설정, 모델 및 앱을 최적화하고 SKAdNetwork에서 최대한의 정보를 추출하도록 지원해 왔습니다.
빅터 사바스, 솔루션 컨설팅 부사장
나비하 지와니, 고객 성공 팀 리더
그들이 내게 말한 내용은 다음과 같습니다…
1. 한 번으로 끝나는 게 아니라는 걸 깨달으세요
IDFA 방식에서는 모든 데이터를 수집한 후 필요한 데이터를 파악할 수 있었습니다. 하지만 SKAN 방식에서는 적절한 측정값을 선택하는 데 훨씬 더 신중해야 합니다.
하지만 충분히 똑똑하지 않다. 우리 모두 마찬가지다. 올바르게 만들려면 반복하고, 더 많이 반복해야 함을 깨달아라 더 정확히. 그리고 세계가 변함에 따라 — Apple이 무언가를 바꾸고 파트너가 무언가를 바꾸면 — 다시 반복하게 될 것임을 인식하라.
사바스는 "일회성 작업이 아니라는 인식과 이해가 필요합니다."라고 말합니다. "SKAdNetwork에 접근하는 핵심 철학의 일부로 반복적인 과정을 중요하게 생각합니다. KPI나 제품이 바뀌는 것뿐만 아니라 생태계 자체가 변화하기 때문입니다."
2. 목표를 이해하십시오
주로 내부 팀을 위한 측정 지표가 필요하신가요? 아니면 광고 파트너 최적화가 특별히 필요하신가요? ROAS , 아니면 고객 여정과 같은 다른 요소가 더 중요한가요? 제품 팀과 성장 팀이 구체적으로 무엇을 필요로 하는지는 어떻게 다른가요?
지와니는 "특히 제 고객들과 함께 일하면서 파트너들이 SKAN 데이터를 이해하고 해석하는 방법, 그리고 이러한 이벤트들이 서로 연결되는 방식을 더욱 심층적으로 살펴보는 것을 보았습니다."라고 말하며, "두 번째 단계는 수익에 집중하는 것입니다."라고 덧붙였습니다
SKAN은 기술이지만, SKAN을 제대로 활용하려면 무엇보다 명확한 전략이 필요합니다.
3. SKAN 기반 광고 수익화 측정 모델의 큰 장점
광고 수익화는 구독과 같은 수익화 모델에 비해 피드백 속도가 훨씬 빠르다는 점에서 큰 장점이 있습니다.
사바스는 "전환 모델을 보다 포괄적으로 생각할 때, 저는 항상 좋은 초기 신호를 제공하는 요소와 시간이 지남에 따라 고품질 사용자 및 높은 고객 생애 가치(LTV)를 예측하는 데 도움이 되는 요소를 고려합니다."라고 말합니다. "그래서 종종 이산 변수와 연속 변수가 혼합되어 사용됩니다. 하지만 광고 모니터링 분야에서는 초기 신호(일반적으로 광고 노출)가 존재하기 때문에 두 가지 모두를 활용할 수 있으며, 이러한 신호는 높은 수준의 변동성을 가지고 있습니다."
즉, 광고 노출량만으로 사용자를 쉽게 세분화할 수 있으며, 이러한 세분화를 통해 어떤 그룹이 인앱 구매를 할 가능성이 더 높은지, 또는 향후 구독 옵션이 있는 경우 구독할 가능성이 더 높은지 예측하고 테스트할 수 있습니다.
SKAN 3에서는 측정 기간이 매우 짧기 때문에 모델링 작업이 많이 이루어집니다. 이러한 모델링은 매우 정확할 수 있지만, 결국 모델링일 뿐입니다.
SKAN으로 측정한 초기 신호들을 안드로이드 데이터와 비교해 보세요.
지와니는 "세션 시작이나 기타 작은 신호들을 포착하고, 안드로이드 사용자들의 성과에 대한 정보와 결합하여 이 두 데이터셋을 비교하는 것이 많은 고객들이 iOS 데이터의 흐름을 이해하는 데 도움이 되었습니다."라고 말합니다.
물론, SKAN 4 측정 기간이 더 길어지며, 이는 크게 도움이 됩니다. 다만 대규모 적용은 내년 초까지는 어려울 수 있습니다. SKAN 4 포스트백은 현재 전체 포스트백의 약 15%에 불과합니다. Singular 가 확인하고 있습니다, 하지만 추세는 상승하고 있습니다.
5. SKAN을 효과적으로 활용하세요: 사용자를 그들 자신보다 더 잘 이해하십시오
미래의 행동을 예측하기 위해 초기 지표를 활용하고 싶은 것은 당연합니다. 첫 번째 단계는 현재 측정하고 있는 것과 실제로 앱에서 무슨 일이 일어나고 있는지를 구분하는 것입니다.
그렇게 하면 실제 행동을 기반으로 SKAN 모델을 구축할 수 있습니다.
사바스는 "예를 들어 인앱 구매 시 평균 제품 가격을 기준으로 수익을 구간별로 나누는 대신, IDFV 데이터 세트를 살펴보고 튜토리얼을 완료한 사용자들이 첫날에 평균적으로 얼마를 벌어들이는지 확인해 보는 건 어떨까요?"라고 말합니다. "이렇게 하면 전환 모델을 정의할 때 수익 구간의 임계값으로 활용할 수 있고, 관찰할 수 있는 효과적인 세분화 그룹 또는 코호트를 설정할 수 있습니다."
SKAdNetwork로 현재 측정할 수 있는 기간보다 훨씬 더 긴 시간 동안 해당 그룹을 관찰하면 해당 세그먼트의 수익 창출 잠재력에 대한 좋은 통찰력을 얻을 수 있습니다. 그런 다음 새로운 SKAN 설치를 해당 세그먼트에 할당해야 함을 나타내는 초기 예측 신호를 실험해 볼 수 있습니다.
6. 테스트 시 SKAN 변환 모델을 매달 반복적으로 업데이트하십시오
SKAN을 실제 환경에서 반복적으로 적용하는 것은 쉽지 않은 일입니다. 매일 반복할 수는 없는데, SKAN 캠페인이 광고 네트워크 파트너의 생태계에 충분히 반영되려면 시간이 필요하기 때문입니다. 너무 빠르게 반복하면 혼란스러워지고, 현명한 의사결정을 내리는 데 필요한 데이터가 부족해질 수 있습니다.
그렇다면 테스트 과정에서 얼마나 자주 반복 작업을 해야 할까요?
지와니는 "처음에는 고객들이 매달 최적화 기준을 바꾸는 경우가 있었습니다."라고 말합니다. "튜토리얼 완료, 등록, 계정 생성 등 초기 단계의 지표를 변경하는 거죠. 구매 여부나 입금 여부를 나타내는 초기 지표를 바꾸고, 그 데이터를 바탕으로 모델링하는 겁니다. 이렇게 첫 번째 이벤트 지표를 변경하는 것이 일부 고객에게는 매우 효과적이었습니다."
물론, 그런 속도를 영원히 유지하지는 않겠지만, 그렇다고 1년 동안 같은 모델을 고수할 가능성도 낮습니다.
참고로, 초기에 SKAN 캠페인을 전환할 때는 모든 작업을 일시 중지하고 48~72시간 기다린 후 다시 시작해야 했습니다.
Singular 이제 반복 작업을 훨씬 빠르고 간편하게 수행할 수 있는 기술을 제공합니다. 전환만 하면 바로 사용할 수 있습니다. 또한 Singular 실제 변경 없이 SKAN 변경을 시뮬레이션하고 업데이트된 측정 데이터가 어떻게 나타날지 확인할 수 있는 제품 기능도 제공합니다.
단순히 전환 가치 수익 구간을 설정하고 방치하지 마세요. 수익 구간이 사용자의 실제 행동과 일치하지 않으면, 사실상 데이터를 낭비하고 정보 활용을 극대화하지 못하는 것입니다.
SKAN이 제대로 작동하도록 하려면 로그 데이터를 확인하세요
지와니는 "혼합 모델이나 인앱 결제(IAP) 수익 모델을 사용하는 사람이라면 누구나 로그 수준 데이터에서 전환 모델에 사용되지 않는 구간이나 감소 구간이 있음을 알게 될 것입니다."라고 말합니다. "이러한 구간을 조정하여 실제로 해당 사용자 하위 집합을 포착하거나, 구간을 확장 또는 축소하여 감소 구간이 없도록 하고 각 실제 전환 값이 모델에 사용되도록 하면 최대한 많은 데이터를 확보할 수 있습니다."
지와니는 고객들과 함께 이러한 과정을 수없이 반복해 왔으며, 거의 항상 더 나은 데이터 수집으로 이어진다고 말합니다.
8. SKAN 4는 코호트를 하위 그룹으로 세분화하여 더 높은 정확도를 얻을 수 있도록 도와줍니다
수 있습니다 did_tutorial, 이후 행동을 관찰하고, 해당 코호트에 대한 초기 지표를 기반으로 수익을 예측할
SKAN 4에서는 훨씬 더 심층적인 분석이 가능합니다.
사바스는 "첫날 '튜토리얼 완료'를 하고 인앱 구매를 한 사용자 집단이 있다고 가정해 봅시다. 이 집단은 64개의 버킷 중 하나로 기능합니다."라고 말합니다. "이것이 바로 사용자 코호트입니다. P2와 P3의 장점은 사용자가 P2 기간이나 P3 기간에 진입할 때 이 코호트를 관찰하여 '아, 이 단일 코호트가 이제 3개의 추가 그룹으로 나뉘는구나'라고 알 수 있다는 점입니다. 예를 들어, 첫날 '튜토리얼 완료'를 하고 구매한 사용자, 그리고 P2 기간에 다시 세션을 진행한 사용자, 또는 추가 구매를 한 사용자, 혹은 고액 구매를 한 사용자 등이 있습니다. 이제 하나의 코호트가 3개의 그룹으로 나뉘게 되는 것입니다."
이 모든 것이 모델링의 정확성을 높이고 초기 지표를 기반으로 더 나은 ROAS 및 LTV 모델을 구축할 수 있는 능력을 향상시킵니다.
SKAN 4에 대한 간단한 안내입니다. 네, 아직 SKAN 4 관련 게시글이 충분히 모이지 않았습니다. 사실, 한참 멀었습니다.
하지만 Singular사용하면 SKAN 4 변환 모델을 설정하고, 협력 중인 SKAN 4 파트너의 이점을 누릴 수 있으며, SKAN 3 파트너의 데이터도 손실하지 않습니다. 하위 호환성이 있기 때문입니다.
9. 스트리밍 분야 및 구독: 네, 초기 데이터가 있습니다
SKAN에서 구독을 유지하는 것은 어렵습니다. 특히 이전에 7일 무료 체험 기간이 있었던 경우에는 더욱 그렇습니다.
하지만 프록시로 활용할 수 있는 초기 이벤트는 항상 존재하며, 음악, 엔터테인먼트, 비디오와 같은 스트리밍 미디어 분야에서는 다른 분야보다 더 많은 초기 이벤트를 활용할 수 있습니다. 이러한 초기 이벤트를 활용하여 SKAN을 제대로 작동시키세요.
사바스는 "스트리밍 서비스를 생각해 보면, 신호를 읽어낼 수 있는 연속 변수들이 있습니다."라고 말하며, "이러한 변수들은 좋은 초기 지표가 될 수 있고, 그 종류도 매우 많습니다."라고 덧붙였습니다
예시:
그들은 몇 번이나 들었을까요?
그들은 영화를 몇 편이나 봤을까요?
더 큰 화면으로 스트리밍했나요, 아니면 외부 스피커로 스트리밍했나요?
또한, 어떤 유형의 구독 상품을 테스트했는지(가족 요금제, 개인 요금제, 학생 요금제 등)와 같은 세분화 지표도 있습니다. 이러한 모든 정보는 세분화를 구축하고 예측 지표를 찾는 데 도움이 됩니다.
예를 들어, 가족 요금제에 다른 사람이 가입해서 추가되었나요?
10. 다양한 수익 창출 방식은 더 나은 데이터 확보에 도움이 됩니다
구독을 통해서만 수익을 창출하는 경우 측정할 항목이 하나뿐이며, 이는 어렵고 SKAN에서 제공하는 측정 기간보다 더 오래 걸리는 경우가 많습니다.
광고 수익화를 추가하면 더 많은 신호를 신속하게 얻을 수 있고, 더 많은 정보를 확보할 수 있습니다. 그리고 인앱 구매를 추가하면 더욱 풍부한 정보를 바탕으로 더욱 정교한 예측을 구축하고 코호트 가치를 더욱 정확하게 평가할 수 있습니다.
더 좋은 점은 사용자/고객/플레이어가 자동으로 스스로를 세분화할 수 있게 되고, 당장 장기적인 투자를 원하지 않는 사람들에게 구매 전에 체험해 볼 수 있는 기회를 제공한다는 것입니다.
11. 소매업: 첫 구매는 쉽지만, 이후의 가치 평가는 어렵다
소매 앱은 SKAN(스캔 기반 자동화) 환경에서 적어도 초기 구매 단계에서는 상당히 잘 작동하는 경우가 많습니다. 사람들이 특정 목적을 위해 소매업체의 앱을 다운로드하고 즉시 구매를 진행하는 경우가 많기 때문입니다.
그래서 첫 구매는 대개 아주 빠르게 이루어집니다.
문제는 후속 구매를 위해 적절한 측정값을 얻는 것입니다.
바로 그런 점에서 세션, 조회수, 검색, 장바구니 담기 등과 같은 참여 변수와 사용량 변수를 살펴봐야 특정 신규 고객이 추가 구매를 할 가능성을 파악할 수 있습니다.
개인적인 경험을 바탕으로 한 주의사항입니다. 저는 앱을 설치만 하고 아무것도 구매하지 않았는데, 몇 달 후에 수백 달러어치를 구매한 적이 있습니다. 당장 아무 일도 일어나지 않는다고 해서 앞으로도 계속 아무 일도 일어나지 않을 거라고 생각해서는 안 됩니다.
SKAN 4는 도움이 되겠지만, 만병통치약은 아닙니다
지와니는 "P2 및 P3 포스트백을 통한 잠금 해제는 누군가가 다시 방문했거나 다른 상품을 구매했거나 특정 카탈로그에서 다른 상품을 보고 있다는 추가적인 신호를 제공하는 것입니다."라고 말하며, "이는 SKAN 4에 도움이 될 것입니다."라고 덧붙였습니다
12. 소매업: 보고 계층과 파트너 최적화 계층을 명확히 구분해야 합니다
신규 사용자 집단의 수익성을 측정하는 것은 매우 중요합니다. 또한 광고 파트너에게 신규 사용자의 가치를 효과적으로 전달하는 것도 중요합니다. 소매 앱에서는 종종 SKAN 전환 모델을 활용하여 수익뿐 아니라 참여 이벤트까지 측정하는 방식을 사용합니다.
여기서 핵심적인 도구는 IDFV입니다.
사바스는 "가입, 장바구니 추가 등을 예로 들면, 참여 및 이벤트 퍼널 모델을 사용할 수 있습니다."라고 말합니다. "이러한 모델을 사용하는 경우, Singular는 여전히 수익 보고 기능을 제공합니다. 예를 들어, '퍼널을 사용하여 IDFV 데이터 세트를 세분화하고, 각 코호트를 관찰하여 시간이 지남에 따라 실제로 발생하는 수익을 확인하고, Singular 보고 인터페이스에서 이러한 수익 추론을 보고할 수 있습니다. 이를 통해 네트워크는 모델 구성 방식에 따라 이벤트를 최적화할 수 있을 뿐만 아니라, 분석 또는 LTV 보고 관점에서도 수익을 확인할 수 있습니다.'라고 말할 수 있습니다."
13. 핀테크: 참여도와 수익 지표를 결합하세요
SKAN(스위스-앤드 ...
따라서 혼합형 전환 모델이 나아갈 방향입니다
지와니는 "대부분의 고객은 앱에 처음 접속하여 일정 수준의 정보를 입력하고, 앱 내에서 다양한 계정을 연결하는 등 사용자의 활동성을 파악하기 위해 참여도 지표와 수익 지표를 모두 활용하는 것을 보았습니다."라고 말합니다. "동시에 수익 측면에서는 입금액이나 거래에 사용된 금액을 파악합니다."
핀테크 분야에서 퍼널 모델은 드물지만 잠재력은 있다고 그녀는 덧붙였다.
14. 온디맨드 방식이라니, 정말 운 좋은 놈들이군!
SKAN 이론에 따르면 온디맨드 앱은 매우 유리한 위치에 있습니다. 온디맨드 앱을 다운로드하는 대부분의 사용자는 구매 또는 참여 과정의 일부로 다운로드하기 때문입니다.
예시: 차량 호출이 필요하면 Uber 또는 Lyft 앱을 다운로드하고 결제 정보를 입력한 후 차량을 호출합니다.
하지만 SKAN을 활용하여 LTV를 추정하려면 고려해야 할 사항이 더 많다고 사바스는 말합니다.
"그러면 연속 변수의 세계로 들어가게 되는데… 운행 시간의 변동성이 크기 때문에 수익 금액은 확실히 일반적인 지표가 아닙니다. 따라서 핵심은 이용률과 이용 빈도입니다."
일반적으로 많을수록 좋다. (당연하지.) 하지만 오해의 소지가 있을 수도 있다. 휴가나 출장으로 여행하는 사람들은 매우 불규칙적일 수 있기 때문이다.
15. 게임: 하이퍼 캐주얼 vs 미드코어
하이퍼캐주얼 게임은 SKAN에 딱 맞는 장르일지도 모릅니다. 관리자 권한과 게임 속도는 이 두 장르에서 공통적으로 중요한 요소입니다
사바스는 "마치 이런 사용 사례를 위해 설계된 것 같아요. 왜냐하면 사용자들이 첫날부터 적극적으로 참여하고, 하이퍼 솔루션의 수명 주기는 훨씬 더 단축되는 경우가 많기 때문이죠."라고 말합니다.
또한, 저희가 어떤 방식으로든 도움을 드릴 수 있다면, 빅터 사바스와 나비하 지와니 같은 전문가들이 고객 및 잠재 고객과 매일 협력하여 Singular 도구를 활용해 마케팅 캠페인의 효과를 극대화할 수 있도록 지원하고 있습니다. 때로는 Singular CTO인 에란 프리드먼을 만나보실 수도 있는데, 그는 아마도 세계에서 가장 박식한 개인정보 보호 및 측정 전문가일 것입니다.
2021년 4월 26일, Apple이 iOS 14.5와 SKAdNetwork를 출시하면서 모바일 마케팅 절반이 변했습니다. 2024년쯤 Google이 Android와 웹에서 Privacy Sandbox를 동시에 켤 때, 나머지 절반도 비슷한 변화를 겪을 것입니다. 우리는 최근 웨비나를 개최했습니다 Google, Gameloft와 함께, Tinuiti 생태계 준비를 돕기 위해. 우리가 배운 핵심: 마케터들이 Privacy Sandbox에서 가장 어려워하는 부분.
저희는 Singular 공동 창립자인 Eran Friedman과 함께 Google, Gameloft, Tinuiti의 패널들을 초청했습니다
켈리 기셴, 구글 프라이버시 샌드박스 전략 파트너 매니저
Vasil Georgiev, Gameloft UA 디렉터
Mollie Sheridan, Tinuiti 모바일 앱 유료 검색 담당 선임 매니저
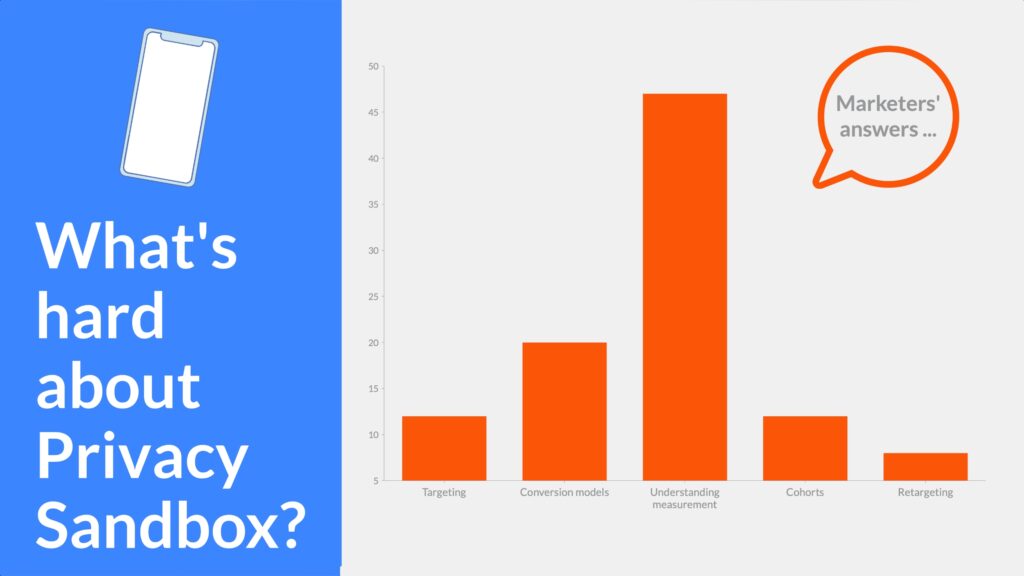
알고 보니 프라이버시 샌드박스에서 가장 어려운 부분이자 가장 중요한 부분은 바로 측정 결과를 이해하는 것이었습니다.
웨비나 참가자들에게 가장 어려운 점이 무엇일 것 같냐고 물었을 때, 다음과 같은 답변을 받았습니다
측정 결과 이해도: 47%
전환 모델 설정: 20%
코호트 추적: 12%
타겟팅: 12%
리타겟팅: 8%
안드로이드에서 어트리뷰션, 타겟팅, 리타겟팅 및 SDK 관리를 위한 새로운 공식 시스템을 배우는 데 따르는 어려움과 그 외 여러 가지 문제들로 인해 마케터들은 상당한 스트레스를 받고 있습니다.
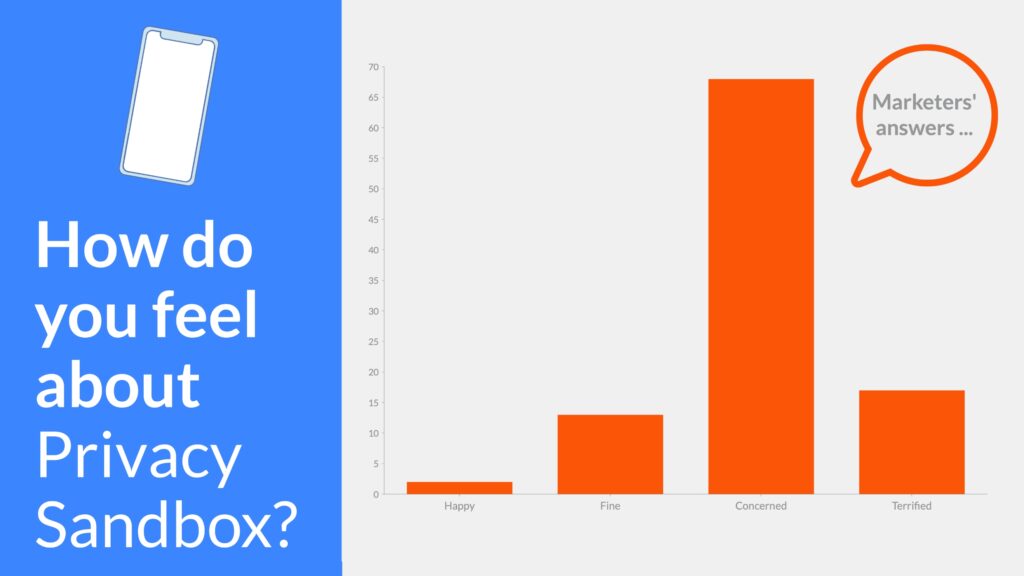
웨비나에 참석한 마케터들을 대상으로 한 조사에 따르면, 68%가 우려하고 있으며, 17%는 두려움을 느끼고 있습니다. "만족스럽다"거나 "괜찮다"고 답한 사람은 15%에 불과합니다
다행스러운 점은 Singular, Gameloft, 그리고 Google이 Privacy Sandbox의 가장 어려운 부분을 포함한 모든 부분에 대해 이미 베타 테스트를 진행하고 있다는 것입니다. 웨비나를 해당 테스트 진행 상황에 대한 최신 정보는
프라이버시 샌드박스는 첫째, 사용자 개인정보 보호와 건전한 모바일 생태계가 상충되지 않는다고 믿습니다. 둘째, 효과적인 대안을 제시하지 않고 일방적으로 접근하는 것은 효과가 없으며 오히려 사용자에게 더 큰 피해를 줄 것이라고 생각합니다. 따라서 이러한 두 가지 원칙을 바탕으로, 기업이 번창하고 성공할 수 있으면서도 개인정보 보호가 최우선시되는 기술을 구상하고 있습니다
- 켈리 기셴, 구글 프라이버시 샌드박스 전략 파트너 매니저
기셴은 본질적으로 이는 기업들이 세부적인 사용자 수준 데이터를 사용하거나 앱 간 추적에 사용될 수 있는 기기 식별자를 수집하지 않고도 성장과 마케팅 활동을 지속할 수 있도록 하는 것이라고 말합니다.
광고 API 및 컨텍스트 API
대부분의 모바일 마케터들은 이제 프라이버시 샌드박스의 핵심 API들을 잘 알고 있을 것입니다. 하지만 구글 내부 관계자들이 이러한 API들을 어떻게 접근하는지 살펴보는 것은 흥미롭습니다. 그들은 API들을 업계가 혁신을 이루어낼 수 있는 기반 요소로 여깁니다.
광고 API는 총 3개이며, 그중 2개는 "관련성 API"입니다
주제 및 보호 대상은 관련성 API입니다
세 번째 광고 API는 어트리뷰션 보고서입니다
“주제 고급 사용자 신호 관심사를 제공하고 컨텍스트 신호와 1인당 데이터와 결합해 SSP와 퍼블리셔가 관련 광고를 선택할 수 있습니다. 그리고 보호된 잠재고객, 보다 세분화된 리마케팅 사용 사례를 지원하며, 광고 기술 마케터, 개발자, 광고주가 특정 브랜드나 제품에 관심을 보인 잠재고객에게 프라이버시를 보호하면서 도달할 수 있게 합니다.”
- 켈리 기셴, 구글 프라이버시 샌드박스 전략 파트너 매니저
Singular 공동 창립자 에란 프리드먼은 "그런 것들은 MMP 분야에서 중요하며, 관련 작업이 진행 중이지만, 마케팅 측정 회사들이 집중할 곳은 자연스럽게 어트리뷰션 리포팅 API가 될 것"이라고 말합니다.
"당연히 MMP로서 저희에게 가장 중요한 부분이며, 프레임워크 테스트, 다양한 미디어 파트너와의 통합, 필수적인 성과 보고를 제공하는 제품 설계 등 많은 자원을 투입하고 있습니다."
SKAN과 프라이버시 샌드박스의 차이점
"두 프레임워크 사이에는 유사한 원칙들이 있지만, 차이점에 대해 이야기하자면 매우 많습니다."라고 에란 프리드먼은 말합니다.
몇 가지 차이점은 다음과 같습니다
캠페인, 크리에이티브, 게재위치 및 최적화 데이터에 대한 프라이버시 샌드박스 집계 키는 SKAN 4의 캠페인 ID보다 훨씬 더 광범위한 범위를 제공합니다
프라이버시 샌드박스에서 더 많은 데이터 포인트를 얻으려면 그에 따른 대가를 치러야 합니다. 인코딩하는 값이 많아지고 세분화 정도가 높아질수록 데이터에 무작위 노이즈가 더 많이 유입됩니다. SKAN에서는 데이터 포인트 수는 적지만, 개인정보 보호 임계값(SKAN 3)이나 크라우드 익명성(SKAN 4)을 충족하면 사실상 모든 데이터를 얻을 수 있습니다.
Privacy Sandbox에서는 캠페인 규모가 매우 작더라도 항상 일정량의 데이터를 수집할 수 있는 반면, SKAN에서는 특정 최소 설치 수 임계값을 넘어야 합니다. SKAN 4에서는 이 임계값이 SKAN 3보다 낮아졌지만, 여전히 존재합니다. Android용 Privacy Sandbox의 단점은 임계값이 낮을수록 노이즈 또는 불필요한 데이터가 더 많이 삽입된다는 것입니다.
Gameloft UA 디렉터인 Vasil Georgiev가 강조한 SKAN과 Privacy Sandbox의 또 다른 중요한 차이점은 테스트입니다.
프라이버시 샌드박스에서는 SKAN보다 변수를 인코딩할 수 있는 기능이 더 많기 때문에 훨씬 더 많은 테스트를 훨씬 쉽게 수행할 수 있습니다.
게오르기예프는 "가장 분명한 차이점 중 하나는 테스트 기회가 엄청나게 많아질 것이라는 점입니다."라며, "우리는 테스트할 수 있는 것들에 제한받지 않을 것입니다."라고 말했습니다
모든 것을 추적하는 것부터 절충안까지
개인 정보 보호에는 대가가 따릅니다. AT&T와 SKAdNetwork를 사용했을 때 iOS에서 발생했던 것과 유사하게 신호 끊김 현상이 발생할 것입니다. 신호 끊김 현상은 이전보다 덜하겠지만, 어쨌든 끊김은 있을 겁니다.
기셴은 "오늘날 마케터들은 원하는 모든 것, 가능한 모든 것을 추적할 수 있습니다."라고 말하며, "그러한 관행은 근본적으로 바뀌어야 할 것입니다. 마케터들이 구체적으로 어떤 정보를 살펴보고 싶어하는지에 따라, 정보의 세분성과 풍부함 대 잡음비와 지연 시간 사이에서 절충점이 생길 수 있습니다."라고 덧붙였다
위에서 언급했듯이, 절충점 중 일부는 얼마나 자세한 정보를 원하는지와 관련이 있습니다. 또 다른 절충점은 정보를 얼마나 빨리 얻고 싶은지와 관련이 있다고 티누이티의 몰리 셰리던은 말합니다.
"보고서를 더 자주 가져오면 데이터의 정확도가 떨어지고, 구글은 개인정보 보호를 위해 그 오차 데이터를 삽입할 것입니다."라고 그녀는 말합니다. "더 정확한 데이터를 얻기 위해 더 오랜 기간을 기다릴지, 아니면 더 짧은 기간을 기다릴지 결정해야 할 것입니다."
하지만 오늘날 마케터들이 원하는 대부분의 작업은 안드로이드용 프라이버시 샌드박스에서도 여전히 가능합니다. 핵심은 마케터의 기여도 분석 요구와 광고 네트워크의 최적화 요구 사항을 충족하기 위해 세부적인 데이터 분석과 집계, 속도와 정확성 사이의 균형을 맞추는 것입니다. 완벽하지는 않더라도 가능한 최상의 결과를 얻는 것이 중요합니다.
셰리던은 "CPI, 목표 ROAS, 특정 이벤트 등 원하는 목표를 중심으로 최적화할 수 있으며, 이러한 데이터는 여전히 활용 가능합니다."라고 말합니다. "다만, 보고 빈도와 보고 대상을 세분화하여 개인정보 보호 중심의 프레임워크 내에서 가장 정확한 데이터를 얻을 수 있도록 충분한 데이터 양을 확보하는 것이 중요합니다."
다행인 점은, 실제로 대규모 마케팅을 전문으로 하는 사람들이 이 방법이 효과가 있을 거라고 생각한다는 것입니다.
"구글이 최소한의 필수 데이터 상태를 인지하고 있으며, 마케터들이 최적화를 계속하는 것을 막지 않으려 한다는 점이 매우 분명합니다."라고 게오르기예프는 말합니다. "그리고 저는 구글이 필요 이상으로 복잡하게 만들지 않으려고 노력하고 있다고 생각합니다."
프라이버시 샌드박스 전체 출시 일정
간단히 답하자면, 아직 없습니다.
하지만 구글은 프라이버시 샌드박스 전체 출시 전에 충분한 사전 공지를 할 것이라고 약속했습니다.
기셴은 "현재로서는 100% 마이그레이션이 언제 이루어질지에 대해 공개적으로 공유할 수 있는 업데이트 사항은 없습니다."라고 말했습니다. "하지만 이전과 마찬가지로 베타 및 정식 출시와 관련된 변경 사항이 있을 경우 생태계 및 파트너에게 충분한 사전 공지를 제공할 것입니다."
구글 및 게임로프트와 함께 진행 중인 프라이버시 샌드박스 베타 개발 진행 상황을 포함하여 훨씬 더 많은 내용이 전체 웨비나에서 공개됩니다
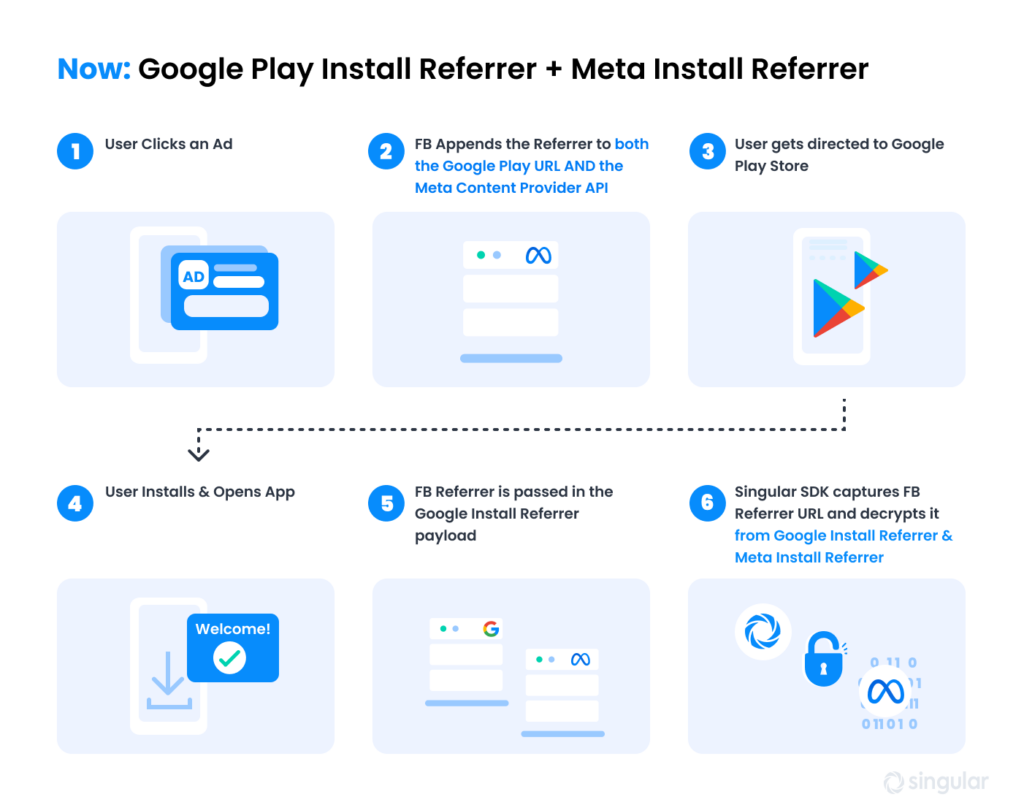
메타가 사용자 수준 클릭 및 그리고 사용자 수준 뷰-스루 어트리뷰션 을 안드로이드에서 페이스북 또는 인스타그램 광고에 대해 다시 얻을 수 있는 프라이버시 보호 방식, 메타 설치 리퍼러를 도입합니다. 메타 설치 리퍼러.
이 기능은 Google Play Install Referrer 을 통해 이미 사용 가능한 측정 가능성을 크게 확장하며 이는 큰 변화입니다. 수년 만에 처음으로 Android 앱 광고주는 메타에서 뷰-스루 어트리뷰션을 다시 제공받아 캠페인의 결과에 대한 더 정확한 그림을 구축하기 위한 추가 세부 정보 및 데이터를 얻을 수 있습니다.
Meta Install Referrer (MIR)는 2023년 11월부터 Singular 에서 지원됩니다.
다음은 Google Referrer와 새로운 Meta Install Referrer의 간단한 비교입니다:
Google Play Install Referrer
Meta Install Referrer
목적
메타에서 광고를 통한 Android 설치 어트리뷰션
메타에서 광고를 통한 Android 설치 어트리뷰션
사용 사례
클릭-스루
클릭-스루
뷰-스루 (대부분의 시나리오)
다른 세션 클릭-스루
앱 스토어
구글 플레이
구글 플레이
기타 Android 앱 스토어
Singular 는 원래의 Google 설치 리퍼러와 MIR을 모두 지원하지만, MIR이 모든 Google 리퍼러 사용 사례를 포함하고 더 많은 것을 추가하기 때문에 Singular 는 사용자 수준의 속성 결정을 위해 Meta Install Referrer를 우선적으로 사용합니다.
몇 가지 주의 사항이 있다는 점에 주목하는 것이 중요합니다. MIR을 사용할 때 뷰-스루 어트리뷰션을 사용할 수 있습니다:
Advantage+ 앱 캠페인
광범위한 타겟팅 수동 앱 프로모션 캠페인
수동 앱 프로모션 캠페인을 위한 지원되는 캠페인 구성은 다음과 같습니다:
기본 연령 설정(18-65+)
모든 성별
국가 또는 국가 그룹
관심 세그먼트, 행동 및 인구통계를 광범위한 타겟팅으로 설정
맞춤 타겟도 광범위하게 설정
Meta Install Referrer 작동 방식
대부분의 사람들은 Google Play Install Referrer가 작동하는 방식을 이해합니다. 왜냐하면 클릭 리퍼러의 개념에 기반하기 때문입니다
사용자가 메타 속성에서 앱 광고를 클릭합니다
메타는 캠페인 메타데이터를 암호화합니다
메타는 이를 플레이 스토어 URL의 리퍼러 매개변수에 추가합니다
플레이 스토어 URL은 사용자를 앱 목록으로 안내합니다
플레이 스토어는 리퍼러 문자열을 저장합니다
싱귤러의 SDK는 플레이 설치 리퍼러 API에서 리퍼러를 읽습니다
싱귤러는 설치 어트리뷰션을 위해 데이터를 복호화합니다
메타 설치 리퍼러는 다르게 작동하지만 본질적으로 유사한 목적을 달성합니다. 아주 높은 수준에서 다음과 같이 작동합니다:
MIR 설계를 검토했을 때, Google 광고 ID나 기타 디바이스 식별자에 의존하지 않고, Meta 또는 MMP 서버가 작동합니다. 따라서 우리는 it’s 기존 GAID·IDFA 기반 솔루션보다 훨씬 프라이버시 친화적이라고 믿습니다. 또 다른 관점에서는 이 솔루션이 웹 표준 링크의 UTM 파라미터와 거의 동일하게 작동한다고 할 수 있습니다(뷰스루 상황에서도).
따라서 다른 주요 플랫폼도 유사한 메커니즘을 채택할 수 있습니다.
이 새로운 방법론으로 마케터는 광고, 크리에이티브, 캠페인이 Meta 전환으로 이어진 모습을 명확히 파악하고, 투자 가치를 더 정확히 측정할 수 있습니다.
캠페인에서 MIR 활성화하기
캠페인에 MIR을 활성화하려면 고객 성공 담당자에게 문의하세요. 현재 Singular 고객, 시작하기 좋은 곳입니다.
불과 얼마 전까지만 해도 대규모 성장 팀의 핵심 과제 중 하나는 광고 크리에이티브. 기본적인 자동화 도구를 사용하더라도 테스트에 필요한 수천 개의 시안을 제작하는 것은 쉽지 않았습니다. 그런데 어제 구글이 P-Max에 광고용 생성형 AI 기능을 베타 버전으로 추가한다고 발표했는데, 정말 멋진 기능들이 많습니다.
향후 몇 달 동안 광고 기술 플랫폼들이 광고용 AI 생성 기능을 모든 광고주를 위한 핵심 기능으로 도입하는 움직임이 본격화될 것입니다. 현재 많은 플랫폼들이 AI 생성 이미지를 테스트하고 있지만, 머지않아 개인 맞춤형 이미지와 콘텐츠를 실시간으로 생성하는 단계로 나아갈 것입니다.
그런 점에서 대형 플랫폼들은 엄청난 이점을 갖게 될 것입니다.
구글의 퍼포먼스 맥스와 광고용 생성형 AI
P-Max의 생성형 AI는 인상적이면서도 한계가 있습니다.
P-Max는 브랜드 홍보대사를 기업, 가정, 해변 또는 전원 풍경 등 다양한 배경에 배치하여 광고 이미지를 생성합니다. 헤드라인과 설명은 물론, 다양한 광고 유형과 배경에 사용할 핵심 이미지도 만들 수 있습니다. 이미 제품 이미지가 있다면 P-Max로 가져와 원하는 만큼 다양한 변형을 시뮬레이션해 볼 수 있습니다. 구글은 P-Max가 동일한 이미지를 두 번 생성하지 않는다고 밝혔으므로, 경쟁업체가 귀사와 매우 유사한 광고를 게재할 염려가 없습니다.
(이제 '내가 틀렸다는 걸 증명해 보이겠다'는 사람들이 몰려들 것이다.)
현재는 미국에서만 이용 가능하며, 단계적으로 출시될 예정이므로 모든 광고주가 이번 주 또는 이번 달에 이용할 수 있는 것은 아닙니다. 정치나 제약과 같은 민감한 분야에 속한 광고주는 이용할 수 없습니다.
당연히 특정 인물이나 유명인, 또는 브랜드 제품의 이미지를 만들 수는 없습니다. (최근 OpenAI와 Dall-E를 이용해 오프라 윈프리의 이미지를 만들려던 시도는 실패했지만, Creative Diffusion에서 이를 허용해 주었습니다.)
모든 이미지에 워터마크가 삽입됩니다 SynthID 이를 통해 인공 생성 사실을 드러내는 기록과 책임이 확보됩니다.
P-Max의 광고용 생성형 AI 솔루션은 Google 사용자에 대한 정보와 광고주의 제품 및 제안에 대한 정보를 결합하여 관련성을 극대화하기 위해 실시간 또는 거의 실시간으로 완전히 개인화된 일회성 광고를 생성하는 실시간 개인 맞춤형 제품 맞춤형 생성형 AI 솔루션이 아닙니다.
함께 즐겨봐요: 모두가 하고 있잖아요
모두가 광고용 생성형 AI 열풍에 동참하고 있습니다. 그중 일부는 생성형 AI를 광고 도구와 통합하는 능력에서 다른 기업들보다 앞서 나가고 있습니다.
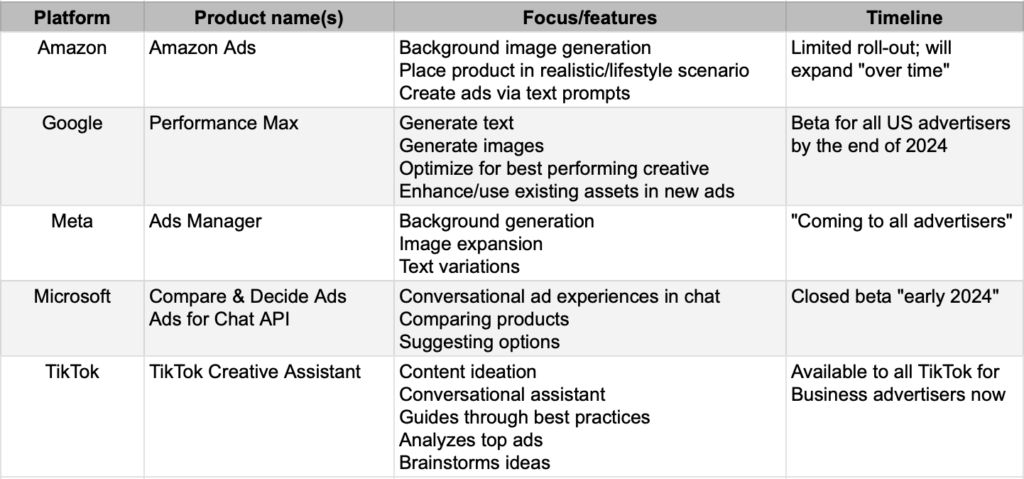
Meta출시 Ads Manager에 생성 AI 도입: 지난달 시작, 전 세계적으로 “내년까지” 배경 생성, 이미지 확대, 텍스트 변형을 위해 순차적으로 확대
Amazon출시 이미지 생성 베타를 지난달 출시, 주로 제품 이미지용 라이프스타일 배경에 초점
Microsoft 는 Microsoft Advertising Platform에 Copilot을 추가하고 있으며, Microsoft’s 이미지 라이브러리를 활용해 새로운 이미지를 생성하고 대화형 채팅을 제공합니다 … 출시 는 비공개 베타에서 “2024년 초”
TikTok 방금 출시 생성형 AI “creative assistant”를 “창의성을 촉발하고 호기심을 위한 발판이 되도록” 플랫폼 광고 제작에 활용합니다
Snap은 My AI에서 텍스트 광고를 게재하고 있지만, 아직 생성형 AI 기반 광고는 게재하지 않고 있습니다.
Pinterest 아직 발표된 내용이 없습니다
Reddit 아직 발표된 내용이 없습니다
대형 브랜드들은 Dall-E를 비롯한 여러 도구를 활용하여 자체적인 생성형 AI를 개발하고 있습니다
WPP, 퍼블리시스, 옴니콤 같은 광고대행사들도 마찬가지다
궁극적으로 이는 모든 주요 플랫폼과 대부분의 주요 광고 대행사 및 광고 네트워크에서 표준 기능이자 필수 선택 항목이 될 것입니다.
실시간 생성형 AI를 위한 플랫폼의 큰 장점과 그 미래는 어떨까요?
모든 광고 플랫폼이 결국에는 광고 도구, 추가 기능 또는 플러그인에 생성형 AI를 추가할 가능성이 높지만, 대형 플랫폼은 막대한 이점을 가지고 있습니다. 이들은 생성형 AI를 광고 도구에 더 빠르게 도입하는 데 필요한 문제를 해결하기 위해 더 많은 엔지니어와 자금을 투입할 수 있을 뿐만 아니라, 플랫폼 내 데이터 측면에서도 우위를 점하고 있습니다.
즉, 실시간으로 생성되는 AI를 활용할 때 사용자의 관심사, 습관, 행동에 대한 훨씬 더 많은 정보를 바탕으로 메시지를 만들어낼 수 있으며, 이는 사용자에게 공감을 불러일으킬 가능성을 크게 높여줍니다.
물론 플랫폼 자체에서도 인정하듯이 아직 할 일이 많습니다. 가장 큰 개선점 중 하나는 마케터들이 브랜드 색상, 이미지, 스타일, 심지어 대화 톤까지 정의할 수 있도록 하여 제작하는 광고가 브랜드에 부합하고 브랜드 구축에 기여할 수 있도록 하는 것입니다.
“모든 브랜드의 고유한 목소리와 시각적 스타일에 맞춘 결과물을 제공하는 데 아직 해야 할 일이 남아 있습니다,” Meta says. “우리는 브랜드와 에이전시와 협력하는 새로운 방식을 정의하여 이 모델들을 브랜드 고유의 관점에 맞게 학습시켜야 합니다.”
다른 하나는 GPU 시간을 효율적으로 활용하는 방식으로 이 모든 작업을 수행하는 것입니다. 특히 실시간 생성형 AI의 경우 GPU 부하가 매우 클 것입니다.
Snap은 이미 이에 대해 고민하고 있으며, 온‑디바이스 작업을 진행할 계획입니다 온‑디바이스 작업. 나는 모든 경우에 작동할지 확신하지 못하지만, 요즘 Apple이 기기에 탑재하는 칩 종류와 — 그리고 Android의 새로운 Snapdragon Gen 3 칩 — that’s 가능성이 있는 시점이 올 것 같습니다.
모바일 웹은 사용자 확보 가 성장하고 있으며, iOS와 Android 지출 패턴이 정상화되고, CPI가 하락하고 있습니다. 이는 새로운 2023 사용자 확보 현황 보고서, 이는 $10 billion 규모의 하위 집합을 기반으로 합니다 Singular 비용 데이터, 수조 건의 광고 노출, 수백억 건의 클릭, 그리고 수십억 건의 앱 설치.
이 보고서는 파트너인 Apptopia의 수십억 창의적 최적화 결정 인사이트를 기반으로 합니다.
그렇다면 2023년 말 현재 UA의 상황은 어떻습니까?
정말 이상한 시기입니다. 사용자 확보 전문가뿐만 아니라 모든 사람에게 마찬가지입니다.
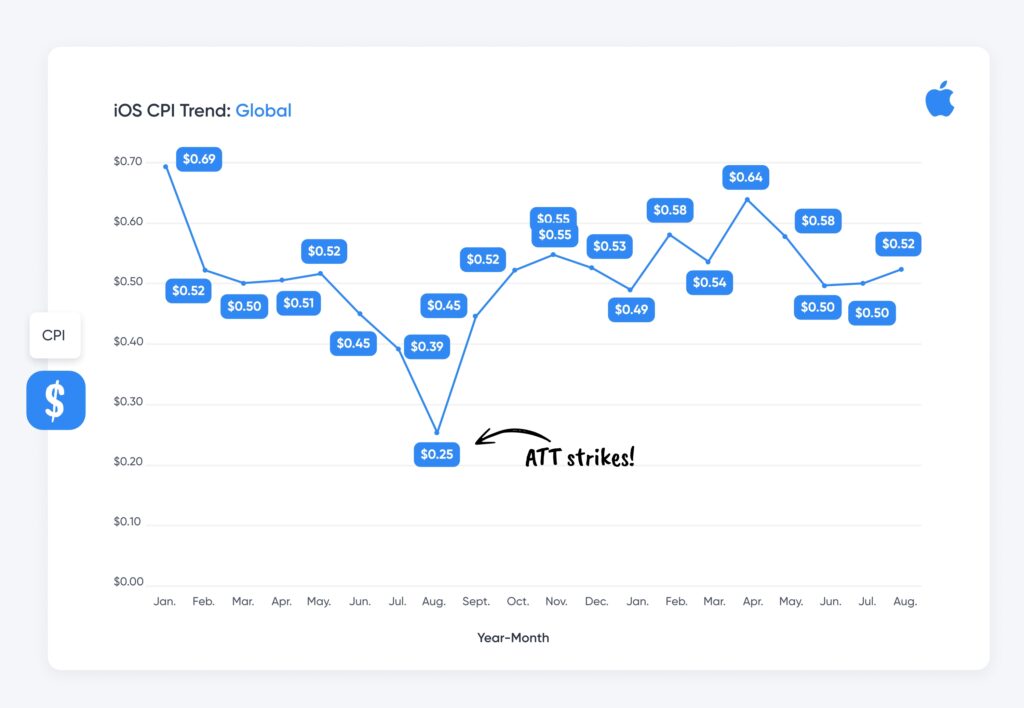
소비가 감소하고 있습니다. 세계 경제는 코로나19, 군사 분쟁, 그리고 심화되는 정치적 양극화의 여파를 느끼고 있습니다. 또한 AT&T와 SKAdNetwork 사태 이후의 혼란이 여전히 남아 있으며, 향후 프라이버시 샌드박스 개편으로 인해 유사한 문제가 더욱 악화될 것이라는 전망도 있습니다.
보고서에는 어떤 내용이 담겨 있나요?
이번 UA 현황 보고서에서는 다음 사항에 중점을 두겠습니다
대규모 생태계 변화
가장 큰 영향을 받은 업종
iOS/Android 지출 변경 사항
CPI 추세
주요 글로벌 지역별 지출 분포
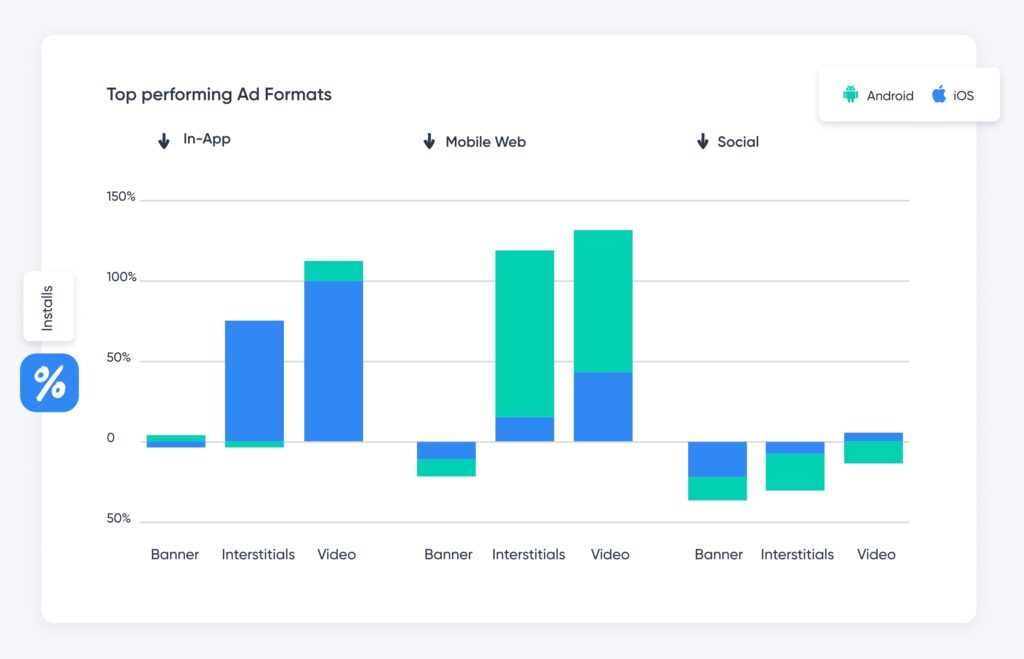
광고 형식 변경에는 다음이 포함됩니다
동영상
배너
간질액
다음과 같은 브랜드를 기반으로 한 성장 인사이트
침착한
세포라
테무
UA의 현재 상황은 연말이라는 것입니다
2023년도 이제 얼마 남지 않았고, 중요한 연말연시 시즌이 코앞으로 다가왔습니다. 이 보고서의 데이터는 연말은 물론 2024년 1분기까지 전략을 세우는 데 도움을 줄 것입니다. 사용자 확보 전문가들이 모바일 웹을 어떻게 활용하고 새로운 광고를 테스트하는지 살펴보고, 전 세계적으로 그리고 아프리카, 아시아, 유럽, 북미 등 주요 국가별 안드로이드와 iOS 간의 광고비 지출 분포도 분석합니다.
파트너사인 Apptopia 덕분에 광고 형식 변경, 효과적인 광고, 변화하는 광고, 그리고 인기 있는 광고에 대한 수십 가지의 인사이트를 얻을 수 있었습니다.
또한, Calm이 전월 대비 다운로드 수를 83% 증가시키고 분기 대비 두 배 이상 늘린 비결을 자세히 살펴봅니다. Temu는 새로운 파트너를 테스트하여 안드로이드 설치 수를 3,000% 이상 늘렸습니다. 그리고 Sephora는 주요 신생 경쟁업체와의 모바일 앱 설치 경쟁에서 어떻게 약자에서 강자로 도약했는지 분석합니다. 이 모든 내용은 사용자 확보 관리자뿐만 아니라 자본, 크리에이티브, 캠페인을 대규모로 활용하여 성공을 거두고자 하는 성장 전략가에게도 매우 유용한 정보입니다.
첫 번째 배너 광고 는 생성 AI 광고와는 거리가 멉니다. 하지만 그 작은 유료 인터넷 역사의 조각을 배치한 같은 사람 중 한 명이 아직도 광고 기술 산업에 참여하고 있습니다. 이제 그는’생성 AI와 기타 신기술에 집중하고 있습니다.
첫 번째 배너 광고
29년 전인 1994년, AT&T는 현재 Wired로 이름이 바뀐 HotWired.com에 최초로 배너 광고를 게재하기 위해 실제로 돈을 지불했습니다. 노트북으로 해변에서 원격 근무를 하거나 화상 회의를 하는 사람들의 미래를 예견하는 광고 캠페인의 일환으로, 무지개색 글꼴로 "여기 마우스를 클릭해 본 적 있나요? 이제 클릭하게 될 겁니다."라는 문구가 적힌 배너 광고였습니다
처음에는 배너 광고라고 불리지도 않았습니다.
처음 이름은 "타일"이었다
"원래 아이디어는 화이트보드에 웹사이트들의 윤곽을 그려보는 것에서 시작됐습니다. 우리는 그걸 '타일'이라고 불렀죠."라고 현재 Data Axle의 엔터프라이즈 솔루션 부문 사장이자 이전에는 Modem Media에서 근무했던 Tom Zawacki는 말합니다. "처음에는 '타일 하나를 가져다가 한 웹사이트에 배치하고, 사용자가 그걸 클릭하면 다른 웹사이트로 이동할 수 있다면 정말 멋지겠다'라고 생각했습니다. 그게 바로 최초의 아이디어였죠."
텍스트가 포함된 상자로, 다른 웹사이트로 연결됩니다.
인터넷 광고의 시작은 상당히 소박했다고 생각할 수도 있습니다. 오늘날 광고 분야에서 활용되는 생성형 AI라는 개념과는 상당히 거리가 멀죠.
광고 개인화에 있어 생성형 AI의 활용
물론 지금은 단순한 배너 광고가 아니라 생성형 AI가 가장 주목받는 기술이며, 창의성과 다양성을 발휘할 수 있는 기회가 기하급수적으로 증가하고. 자와키는 생성형 AI에서 광고 크리에이티브 개인화가 큰 기회 중 하나라고 생각합니다.
그는 "생성형 AI를 사용하는 장점 중 하나는 카피라이팅이나 시각 디자인 제작 시 생산량을 늘릴 수 있다는 점입니다."라고 말합니다. "저희는 항상 개인 맞춤형 서비스를 제공하겠다고 약속해 왔지만, 문제는 창의적인 메시지와 시각 디자인을 조합하는 데 필요한 변수들의 양과 속도가 인간이 따라잡을 수 없을 정도로 빠르다는 것입니다."
저도 그렇게 생각해요. 예를 들어 아마존이 인공지능 기반 광고를 통해 얼마나 큰 기회를 가질 수 있을지 정말 놀라워요. 아마존 광고의 대부분은 아마존 플랫폼에 게재되니까요. 즉, 아마존은 광고를 보는 사람들에 대해 많은 정보를 알고 있다는 뜻이죠. 구매 내역, 검색 기록, 아마존 프라임 비디오에서 시청하는 콘텐츠, 프라임 뮤직에서 듣는 음악, 킨들에서 읽는 책까지 말이죠.
아마존이 판매하는 수천만 개의 제품에 대해, 특히 플랫폼 내에서 인공지능 기반 생성 광고를 통해 얼마나 다양한 개인 맞춤형 서비스를 제공할 수 있을지 상상해 보세요. 텍스트 및 이미지 광고는 비교적 쉽게 구현할 수 있을 것입니다. 동영상 광고 역시 컴퓨팅 자원이 더 많이 필요하긴 하지만 충분히 가능합니다.
오프 플랫폼에서는, 물론, 더 어렵습니다. 그것은’ ATT, SKAN 및 Privacy Sandbox 가 디바이스 식별자 접근을 차단하면서, 오프 플랫폼 개인화는 더 어렵고 덜 타깃팅됩니다.
하지만 다른 플랫폼들은 폐쇄형 생태계, 그리고 소매 미디어 플랫폼도 자체 환경에서 유사한 기능을 수행할 수 있어야 합니다: Facebook, TikTok, Snap, Pinterest, DoorDash, Uber 등. 마케팅 개인화의 황금기는 온-플랫폼 생성 AI 광고에 있을 가능성이 높으며 … 브랜드를 위해 앱 및 웹사이트와 같은 자체 공간과 허가된 커뮤니케이션에서도 추가될 수 있습니다.
창의적인 캠페인 구축을 위한 생성형 AI
또 다른 질문은 마케터들이 생성형 AI를 활용하여 핵심 광고 콘텐츠를 어떻게 구축할 것인가 하는 것입니다
앞서 말씀드렸듯이, 기계가 알아서 일을 해주길 바라는 건 쉽습니다. 마치 막대기로 미드저니를 쿡쿡 찌르면서 멋진 일을 해내라고 시키는 것처럼 말이죠. 하지만 특정 캠페인이나 광고 기회에 완벽하게 부합하는, 세계적인 수준의 훌륭한 크리에이티브를 만들어내는 것은 훨씬 더 어렵습니다.
자와키는 생물학과 인공지능의 결합이 언제나 승리할 것이라고 믿는다.
"IBM 왓슨은 2017년에 인간 지능과 인공지능을 활용하여 일련의 작업을 수행하는 훌륭한 연구를 진행했습니다."라고 그는 말합니다. "그리고 모든 경우에 있어, 인간과 인공지능이 협력하는 것, 즉 증강 지능(당시에는 인지 컴퓨팅이라고 불렀습니다)이 모든 작업에서 우위를 차지했습니다."
그의 목표는 토니 스타크 모델처럼 인간의 지능이 인공지능을 지휘하여 혁신을 증폭시키고 가속화하는 것입니다. 아마 우리 모두 머지않아 JARVIS, 즉 아주 똑똑한 시스템(Just A Rather Very Intelligent System)과 같은 인공지능 시스템을 갖게 될지도 모릅니다.
그리고 그것은 판도를 바꿀 것입니다.
자와키는 "우리는 증강 지능을 활용하여 고객과 직원들을 슈퍼히어로로 만들고 있습니다."라고 말합니다.
메타는 2023년 11월부터 유럽 연합(EU)에서 연간 구독료로 미화 127.40달러를 부과할 예정입니다. 이는 메타가 유럽에서 사용자당 광고 수익으로 벌어들인 금액(지난 4분기 동안 약 64달러)의 거의 두 배에 달하는 금액입니다.
Meta는 오늘 EU 규정 변경으로 인해 Facebook과 Instagram에 광고 없는 구독 서비스를 제공한다고 발표했습니다. 핵심 이유: EU 입법자들은 거부했습니다 Meta’s가 “계약상 필요성”을 개인 맞춤 광고를 위한 사용자 데이터 처리의 법적 근거로 유럽에서 사용하는 것을 거부하고, Meta를 구독 옵션으로 유도했습니다. 이 옵션은 EU 시민들에게 데이터 처리가 없는 방식으로 Meta’s의 글로벌 규모 소셜 플랫폼에 접근할 수 있게 합니다.
Thanks to Meta’s detailed quarterly and annual reports, it’s easy to understand both how much Meta makes from advertising right now, and how many Europeans would have to subscribe to Meta’s services to replace that ad revenue.
기록했습니다. 월평균 4억 800만 명의 사용자지난 4분기 동안
평균 15.99달러를 수익으로 가져왔습니다. 분기당
Meta는 월간 활성 사용자(MAU)당 63.97달러를 광고를 통해
참고로, 사용자당 총 수익은 사용자당 광고 수익보다 약간 높은데, 이는 Meta가 일부 유료 상품을 판매하기 때문입니다.
하지만 이론적으로 메타의 구독 플랜은 평균 사용자당 광고보다 훨씬 더 많은 수익을 창출할 것입니다.
웹 구독자는 월 10.60달러, 연간 총 130달러(현재 연간 할인에 대한 언급은 없지만 향후 추가될 가능성 있음)를 지불하게 됩니다. 인앱 구독자는 더 많은 비용을 지불해야 하지만, 메타가 애플과 구글의 수수료를 충당하기 위해 트위터처럼 인앱 구매 가격을 인상하는 추세이므로 웹 구독 요금을 기준으로 설명하겠습니다.
그 130달러는 메타가 평균 사용자당 타겟 광고를 통해 벌어들이는 금액의 거의 두 배에 달합니다.
이러한 추세라면 메타는 모든 광고 수익을 대체하기 위해 2억 857만 2327명의 유럽 사용자가 구독을 구매해야 합니다.
물론, 우리가 트위터(OK, X)에서 본 것처럼, 구독하는 사람은 매우 적습니다. X에서는 약 640,000명 프리미엄을 위해 비용을 지불합니다, 이전에 트위터 블루였던. Twitter Ads Manager’s 추정치를 보면 372.9백만 대상 사용자이며, 그것은’s 사용자 중 1%보다 훨씬 적습니다. 정확히 말하면, 그것은’s .2% 미만입니다. 그리고 그것은’s 메타’s 사용자가 페이스북과 인스타그램의 경제에 영향을 줄 만큼 크게 다를 것이라는 증거는 거의 없습니다.
이는 메타의 사업 모델 변화에 관한 것이 아닙니다
2억 800만 명의 유럽인들이 광고 수신에 동의하는 것만으로도 페이스북을 이용할 수 있는데, 굳이 연간 130달러에 해당하는 유로화를 내고 페이스북에 접속하려 들지는 않을 것입니다.
오히려 이는 메타가 구독 모델을 내세워 유럽 규제 당국에 시민들이 서비스 비용을 지불하면 개인 맞춤형 광고를 위한 데이터 처리를 완전히 거부할 수 있다고 설명할 수 있도록 세부 사항을 정리하는 것에 불과합니다.
이는 광고주들에게 좋은 소식입니다. 광고주들은 소비자, 플레이어, 고객 및 사용자와 소통할 수 있는 소중한 수단을 잃고 싶어하지 않기 때문입니다.
이는 유럽인들에게도 좋은 소식입니다. 메타가 개인 맞춤형 광고를 위해 사용자 데이터를 계속 처리할 수 있는 법적으로 타당한 근거를 (거의 확실하게) 확보했기 때문에, 유럽인들은 앞으로도 친구, 가족, 커뮤니티, 유명인과 연결해 주는 소중한 서비스를 무료로 이용할 수 있게 되었습니다.
Google이 조용히 시작합니다 신호 IP Protection이라는 다가오는 Chrome 기능으로, 다음과 유사하게 작동합니다 Apple’s Private Relay 기능으로, IP 주소를 숨겨 추적 — 및 마케팅 측정 —을 더 어렵게 만듭니다. Google’s 곧 출시될 Privacy Sandbox 기술이며, Apple과 Google의 프라이버시 기술 사이에 흥미로운 유사점이 있으며, 몇몇 유사점 — 및 차이점 —이 두 기술 거인의 마케팅 및 귀속.
분명히 우리는 거대 기술 기업들로부터 서로 독립적이면서도 종종 연관된 소프트웨어, 표준, 프레임워크 및 요구 사항 모음이 등장하는 것을 목격하고 있습니다. 이러한 거대 기술 기업들의 이니셔티브는 서로 다르지만 매우 밀접하게 관련된 두 가지 영역에 있습니다
개인정보 보호 강화
마케팅 측정
이러한 연관성의 핵심 이유는 마케팅 측정에 있어 추적이 필수적이었고, 그 추적이 개인정보 보호에 상당한 영향을 미쳤기 때문입니다. 이러한 거대 기술 기업들의 계획은 측정 수단으로서의 세부적인 추적을 완전히 없애고, 분석 기능을 제공하면서도 개인정보를 보호하는, 다소 잡음이 섞인 방식으로 광고 효과를 확정적으로 평가하는 새로운 방식을 도입하는 데 목적이 있습니다.
* 보세요 Privacy Sandbox 웹사이트: “Privacy Sandbox는 사이트가 접근할 수 있는 정보량을 제한함으로써 지문 인식과 같은 다른 형태의 추적을 제한하고, 귀하의 정보가 개인적이고 안전하게 유지되도록 돕습니다.”
이러한 시스템은 양쪽 모두 매우 복잡합니다. iOS와 Android에서는 운영체제 수준의 구성 요소로 일부 기능이 내장되어 있고, 앱 제출 및 검토 과정에 통합된 부분도 있으며, 실제 코드로 구현된 기능이라기보다는 플랫폼 수준의 지침으로 작용하는 부분도 있습니다. 이러한 시스템들은 깔끔하게 세분화된 단일 프로젝트나 프로그램이 아니기 때문에 완전히 이해하기 어렵고, 개인정보 보호 및 마케팅 성과 측정에 미치는 전반적인 영향을 파악하기도 힘듭니다.
물론, 둘 다 모바일 앱의 세계와 개방형 웹의 세계를 다루고 있기 때문에 전체적인 상황이 더욱 복잡해집니다.
지능형 추적 방지 vs. 새로운 구글 IP 보호 기능
2017년 iOS 11과 macOS High Sierra에 처음 도입된 Apple의 지능형 추적 방지(Intelligent Tracking Prevention, ITP) 기능은 타사 쿠키를 차단하고, 자사 쿠키를 신속하게 삭제하며, 기기 특성을 흐리게 처리하여 기기 식별을 어렵게 함으로써 사이트 간 추적을 방지합니다. IP 주소를 숨기는 프라이빗 릴레이(Private Relay) 기능과 모바일에서 IDFA(식별자 인증)에 대한 권한 부여를 위한 앱 추적 투명성(App Tracking Transparency) 기능이 함께 작동하여 강력한 개인정보 보호 도구 역할을 할 뿐만 아니라 마케팅 측정에도 어려움을 줍니다.
이제 구글도 크롬 브라우저용으로 유사한 기술을 개발 중이며, 이로써 개인정보 보호, 마케팅, 측정 분야에서 애플과 구글의 기술 스택 간에 흥미로운 유사점과 차이점이 더욱 두드러지게 나타나고 있습니다.
구글의 새로운 기술은 공개 . 크로미움은 크롬을 비롯해 마이크로소프트 엣지, 브레이브, 오페라 등 크롬 기반 브라우저의 핵심 구성 요소인 오픈 소스 브라우저 엔진입니다.
구글의 선임 소프트웨어 엔지니어인 브리아나 골드스타인은 "IP 보호는 특정 도메인에 대한 타사 트래픽을 프록시를 통해 전송하여 사용자의 IP 주소를 해당 도메인으로부터 숨김으로써 사용자를 보호하는 기능입니다."라고 설명합니다.
그녀는 이 기능이 단계적으로 출시될 예정이며, 사용자가 직접 선택할 수 있는 기능이 될 것이라고 말했습니다. 또한 "사용자 추적에 사용되는 것으로 간주되는 스크립트와 도메인에만 초점을 맞출 것"이라고 덧붙였습니다
기능적으로, 이 기능은 Apple’s Intelligent Tracking Protection와 매우 유사하게 작동합니다, Goldstein이 말합니다. 현재 이 실험은 Android WebView, Android 앱이 웹 콘텐츠를 표시하도록 하는 기술에 영향을 주지 않으며, 초기에는 Google’s 자체 도메인에만 제한됩니다. 보안 우려를 일으킬 수 있으며, Bleeping Computer 노트, 프록시 트래픽은 “보안 및 사기 방지 서비스가 DDoS 공격을 차단하거나 비정상 트래픽을 탐지하기 어렵게 만들 수 있다”라는 점을 의미합니다.
개인 클릭 측정 및 SKAN 대 개인 정보 보호 샌드박스
Apple은 개인 정보 보호를 핵심 경쟁력으로 절대적으로 필요로 하며, 모바일 세계를 얼굴에 착용하는 개인용 PC로 확장하면서도 12개 이상의 카메라 그 위와 안에서 여러분의 세계와 얼굴을 모두 바라보며 — 플러스 6개의 마이크 — 회사는 광고가 무료 앱과 무료 웹을 견인한다는 점을 이해한다.
그리고 이를 위해서는 측정이 필요합니다. 광고주들은 투자 대비 수익률(ROI)을 얻고 있다는 것을 입증받아야 하기 때문입니다.
물론, 수익 측면에서 볼 때 광고 네트워크가 주된 사업인 구글은 그런 교훈을 배울 필요가 전혀 없었습니다.
프라이빗 클릭 측정은 웹 간 및 모바일 앱 간 광고 클릭을 모두 측정하며, 웹사이트 또는 앱당 최대 256개의 동시 광고 캠페인에 대해 소스에 대한 8비트 식별자와 전환에 대한 4비트 식별자를 제공하여 16가지 전환 이벤트를 측정할 수 있도록 합니다. SKAdNetwork와 유사하게 24~48시간의 시간 지연이 내장되어 있으며, 광고주와 광고 네트워크 모두에 대한 측정 포스트백은 브라우저와 기기에서 처리됩니다.
함께 모바일 앱용 SKAdNetwork — 여기서는 다루었으니 언급하지 않겠습니다 꽤철저히 에 대한 Singular 블로그 — Apple은 점점 풍부해지는 광고 측정 프레임워크를 진행 중입니다. 네, PCM은 쿠키(1차·3차)와 비교해 미미하고 SKAN은 제한 없는 IDFA 접근과 비교해 미미합니다. 하지만 that’s 요점: they’re privacy‑safe, 그리고 Apple은 시간이 지나면서 기능을 계속 추가할 것입니다.
반면, 웹용 프라이버시 샌드박스와 안드로이드용 프라이버시 샌드박스는 광고 작동 방식의 기본 원칙을 재정의하려는 본격적인 시도입니다. 애플의 시도는 애드테크의 문제점을 완화하는 데 중점을 두는 반면, 구글의 시도는 애드테크가 존재하는 세상을 재창조하는 데 초점을 맞추고 있습니다.
마케팅 측정 분야에서 두 솔루션의 가장 큰 차이점은 구글이 광고 및 마케팅에 필수적인 기능인 타겟팅과 리타겟팅 기능을 제공한다는 점입니다. 개인정보 보호를 고려한 제한적인 기능이지만, 어쨌든 이러한 기능은 제공됩니다. 반면 애플은 SKAN 5에서 기존 사용자, 플레이어 또는 고객에게 마케팅을 진행했는지 여부를 알려주는 리타겟팅 신호를 제공하지만, 개인정보를 안전하게 보호하면서 대규모 타겟팅을 하거나 기존 또는 과거 사용자를 대상으로 리타겟팅하는 기능은 제공하지 않습니다.
그건 아마 SKAN 6이나 SKAN 7까지 기다려야 할지도 모르겠네요?
구글과 애플의 개인정보보호/마케팅/측정 도구 모음: 유사점과 차이점
궁극적으로 진화하는 디지털 마케팅 생태계의 개인정보 보호 요구 사항을 종합해 보면, 쿠키, 식별자 또는 기기 특성을 통한 추적을 제한하기 위해 여러 가지 요소가 복합적으로 필요합니다.
개인정보 보호를 위한 안전한 마케팅 측정 도구 (SKAdnetwork, Private Click Measurement, Privacy Sandbox)
이러한 모든 점을 고려할 때, 구글과 애플의 기술 플랫폼 사이에는 분명한 유사점이 있습니다. 애플이 훨씬 일찍(2020년) 서드파티 쿠키를 금지했고, ITP와 프라이빗 릴레이가 이미 수년 전부터 시장에 나와 있음에도 불구하고, 구글의 프라이버시 샌드박스와 IP 보호 기능은 거의 동일한 결과를 가져올 것입니다. (참고: 이러한 기술들은 적용 강도에 차이가 있을 가능성이 높습니다. 구글은 거의 모든 수익을 광고에서 얻는 반면, 애플은 거의 모든 수익을 기기에서 얻기 때문입니다. 하지만 전반적인 흐름은 유사합니다.)
하지만 방금 언급한 것과 같은 이유로 분명한 차이점도 존재합니다.
구글의 프라이버시 샌드박스는 앞서 언급했듯이 광고 모델 전체를 재창조하는 것입니다. 인모비의 세르지오 세라는 이를 '360도 광고 스위트'라고 불렀습니다
"안드로이드용 프라이버시 샌드박스는 완벽한 광고 솔루션입니다. 타겟팅, 리타겟팅, 지문 인식 방지, 어트리뷰션 등 360도 전방위적인 기능을 제공합니다."
이는 애플의 ATT와 SKAdNetwork의 서비스 범위를 분명히 벗어나는 일입니다. 이들 회사는 개인정보 보호 및 개인정보 보호 규정을 준수하는 마케팅 측정에만 집중하고 타겟팅이나 리타겟팅은 고려하지 않습니다.
새롭게 부상하는 개인정보 보호 중심의 마케팅 인프라는 하이브리드 측정 방식의 필요성을 의미합니다
이 모든 것을 종합하면 개인정보 보호에 안전한 새로운 광고 인프라가 탄생합니다.
다음과 같이 정의됩니다:
개인에 대한 존중이 증가하고, 그 결과 개인의 사생활에 대한 존중도 증가한다
광고 기술 생태계의 데이터 수집 능력 감소
사이트 간 및 앱 간 사용자 추적 기능 감소
마케팅 측정의 복잡성 증가
반독립적 어트리뷰션 프레임워크 및 기술(프라이버시 샌드박스, SKAN)에 대한 의존도 증가
이 모든 현상은 마케팅 믹스 복잡성이 증가하고, 단순 웹·모바일에서 웹·모바일·CTV·야외·맞춤 SMS·리테일 미디어·인플루언서·데스크톱·콘솔 등으로 확장되는 동안 발생하고, 채널 및 플랫폼 … 이는 성장하는 필요성을 미디어 믹스 모델링 (MMM).
점점 더 요구되는 것은 Singular 라고 부르는 하이브리드 측정: 마케팅·광고 귀속은 플랫폼·비용·캠페인·전달·귀속·1인당 신호 등 다양한 요소를 기반으로 합니다. 일부는 SKAN·Privacy Sandbox 같은 결정론적 소스에서 파생되고, 집계·노이즈가 추가됩니다. 일부는 MMM 같은 확률적 기술에 의존합니다. 또 다른 일부는 가장 정확하고 상세한 1인당 데이터, 즉 자체 1인당 데이터를 기반합니다.
이 모든 것은 마케터들의 발밑을 송두리째 흔들어 놓는 엄청난 변화입니다. 하지만 이는 업계 차원뿐 아니라 전 세계적인 법률 개정이며, 결코 멈추지 않을 것입니다.
변화하는 모든 상황 속에서도 Singular 보장할 수 있는 한 가지는 마케팅 측정, 최적화 및 성장에 필요한 모든 것을 제공해 드린다는 것입니다.
Singular CTO Eran Friedman은 AdBites 팟캐스트에서 Redbox CTO Samual Chorlton과 함께 대화를 나눴습니다. 주제는 SKAdNetwork, 특히 SKAN 3에서 전환하는 사람들을 위한 SKAN 4 지원에 관한 모든 것입니다. Redbox CTO Samual Chorlton on the AdBites podcast. The topic: everything SKAdNetwork, especially SKAN 4 help for those working on a transition from SKAN 3.
SKAN 3에서는 우리가 알고 있듯이 Apple이 사용자를 익명화하기 위해 개인 정보 보호 임계값 을 제공했습니다. 캠페인 전환량이 적으면 전환 값이 거의 또는 전혀 발생하지 않습니다. 이는 효과가 있지만 소규모 광고주에게는 불이익을 주며, 광고 캠페인에 대한 피드백을 줄이고 ROI 및 ROAS 수치에 대한 신뢰도를 낮춥니다.
“누구나 SKAN을 사용할 수 있도록 하는 것이 아이디어입니다. 이제 막 시작했거나 예산이 거의 없고 테스트만 하는 경우 제한된 정보만 얻을 수 있지만 많지는 않을 것입니다.”라고 Friedman은 말합니다. “하지만 규모가 커지고 더 발전된 기능이 필요해지면 최적화를 위해 더 세분화된 정보를 더 많이 얻을 수 있을 것입니다.”
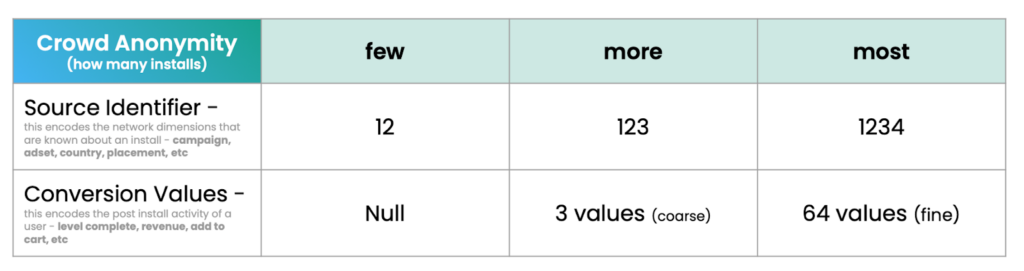
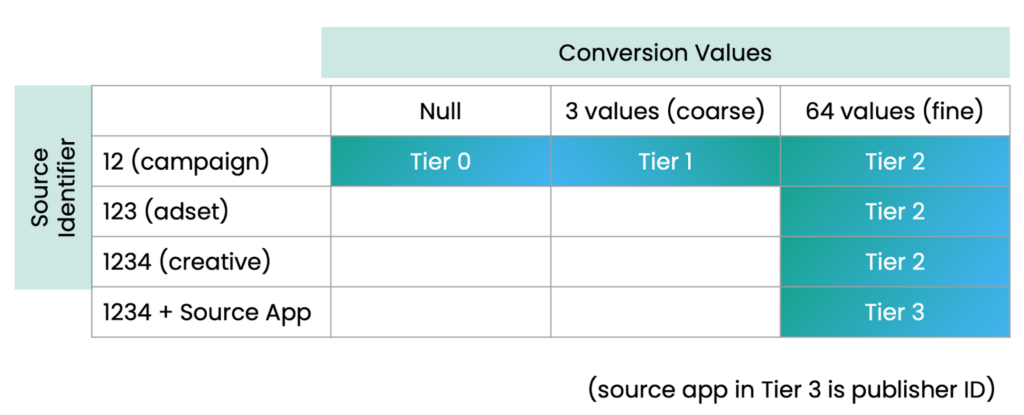
SKAN 4에서는 캠페인당 15 설치만으로 광고주에게 최소 데이터를 제공합니다: 최소 대략 전환값: 낮음, 중간, 높음. 많지는 않지만 최소한 일부 신호로 보정 및 최적화를 시작합니다.
그것이 자신감을 주어 귀하의 광고 지출, 귀하’ 더 많은 전환 값을 얻고 거친 값뿐 아니라 정밀 값도 얻을 수 있습니다: 64개의 잠재 값. 규모를 더욱 확대하면, 귀하’ 소스 식별자, 캠페인, 지역, 광고 위치를 태그하는 데 사용할 수 있는 보다 상세한 데이터를 제공합니다. 이러한 태깅은 캠페인 최적화와 개선에 정보를 제공하여 원하는 것을 더 많이 얻을 수 있게 합니다.
SKAN 4 도움말: SKAN 용어 정의
가장 어려운 부분 중 하나는 SKAN 전반적으로는 언어를 배우는 것입니다. 그것’은 특히 모바일 마케팅에 처음인 사람들에게 해당되며, 그것’은 업계 베테랑에게도 마찬가지입니다. 많은 용어가 새롭거나 다르게 사용되기 때문입니다.
그래서 프리드먼은 AdBites 청중을 위해 용어를 정의했습니다
전환 값
사용자의 가치를 나타내는 숫자를 선택합니다. SKAdNetwork가 해당 숫자를 포스트백으로 인코딩하고 MMP 가 이를 디코딩하면 광고 캠페인의 효과를 파악할 수 있습니다.
대략적인 전환 값
볼륨이 낮은 캠페인에서는 거친 전환 값(사용자 가치를 나타내는 낮은 값, 중간 값 또는 높은 값 3가지)만 있어 캠페인 효과를 나타낼 수 있습니다.
Fine conversion values
캠페인 볼륨이 높을 때 SKAN 4는 더 많은 데이터를 전환 값으로 인코딩하는 것을 허용합니다: 거친 전환 값의 3가지 가능한 값뿐만 아니라 SKAN 3에서 사용 가능한 64가지 가능한 값도 있습니다
(참고: SKAN 4에서는 첫 번째 사후 전송에 대해서만 세분화된 전환 값을 얻을 수 있습니다. 두 번째와 세 번째 사후 전송은 항상 거친 전환 값입니다.)
소스 식별자
SKAN 4에서는 소스 식별자가 캠페인에서 얻을 수 있는 추가 데이터입니다. 전환 값과 마찬가지로 사용자 익명성에 연결됩니다. 즉, 높은 볼륨일수록 낮은 볼륨보다 더 많은 잠재적 데이터를 제공합니다.
높은 사용자 익명성을 달성하면 소스 식별자는 캠페인, 타겟 지역, 사용된 광고 세트, 광고 게재 위치 등에 대한 데이터로 인코딩할 수 있는 4자리 숫자가 됩니다.
MMP가 SKAN에서 하는 역할
SKAN이 처음 나왔을 때 일부에서는 MMP가 더 이상 필요하지 않다고 생각했습니다. SKAdNetwork가 광고주에게 직접 결과를 전송할 수 있기 때문에 독립적인 결과 측정이 필요하지 않을 수 있습니다.
복잡성이 핵심 과제로 떠올랐습니다. 게다가 광고주 모델을 광고 네트워크에 대해 해석하여 알려진 좋은 결과에 따라 최적화할 수 있는 능력이 필요했습니다.
이것이 SKAN 4 지원이 절실히 필요한 핵심 이유 중 하나입니다.
“우리가 생각하는 이상적인 세계는 MMP가 SKAdNetwork 프레임워크 전체에 대한 기술과 관리를 제공하는 것입니다. 기본적으로 API를 사용하고 전환 값을 관리하며 사후 통계를 다시 가져오고 본질적으로 기술 용어와 세부 사항을 추상화하려고 노력하여 광고주가 인코딩된 숫자나 세부 사항을 생각할 필요 없이 최종 결과를 얻을 수 있도록 하는 것입니다.” Friedman은 말합니다.
캠페인, 설치, 달러, 등록과 같은 인간적인 용어로 표현된다는 의미입니다.
추가로, SKAdNetwork의 프라이버시 중심 난독화와 Apple이 숫자에 추가하는 무작위성을 고려해 사용할 수 있는 Singular의 AI 기반 모델링 SKAN Advanced Analytics 은 마케팅 측정에서 누락된 데이터를 복원하면서 사용자 프라이버시에는 영향을 주지 않습니다.
SKAN 4 도입: 아직 규모에 이르지 못함
두 사람이 팟캐스트에서 다룬 또 다른 주제는 SKAN 4 도입입니다. 현재 많은 광고 네트워크, 특히 큰 플랫폼에서 뒤처지고 있습니다.
“프리드먼은 “모두가 확실히 SKAN 4로 업그레이드하기 위해 노력하고 있다고 생각합니다.”라고 말합니다. “일부에서는 예를 들어 SKAN 4의 베타 테스트를 시작했으며 이미 SKAN 4 캠페인을 진행 중인 광고주를 선정했습니다. 다른 일부에서는 전체 출시를 완료했으며 이미 대부분의 트래픽이 SKAN 4로 이동한 것을 확인했습니다... 이는 네트워크별 수준에서 이루어지고 있습니다.”
내가 들은 대부분의 업계 전문가들이 언급한 일정은 2024년 1분기 범위입니다. 이에 대한 자세한 내용은 향후 Singular 블로그 게시물에서 다룰 예정이지만, SKAN 4 도움이 필요하신 경우 아직 시간이 있다는 것이 핵심입니다.
SKAN 4 전환에 대한 지침이 필요하십니까?
위의 동영상을 시청하고, 우리 SKAN 4 전환 가이드 도 확인하세요. 시작하는 데 필요한 모든 세부 정보를 얻을 수 있습니다.