How do you crush mobile measurement on iOS under SKAdNetwork? And how do you get 40% cheaper app installs on TikTok? There’s probably a lot of answers to that question, but one of them is having the right partner for mobile measurement. And another just might be having the right attitude.
“You just need to be brave,” says Carry1st’s senior manager for ad monetization and user acquisition Claire Rozain.
(First step: check out everything she said by signing up for SKANATHON and watching the third episode first. The insights here are extracted from a recent webinar in the SKANATHON series.)
Being brave on iOS … and using every data point possible
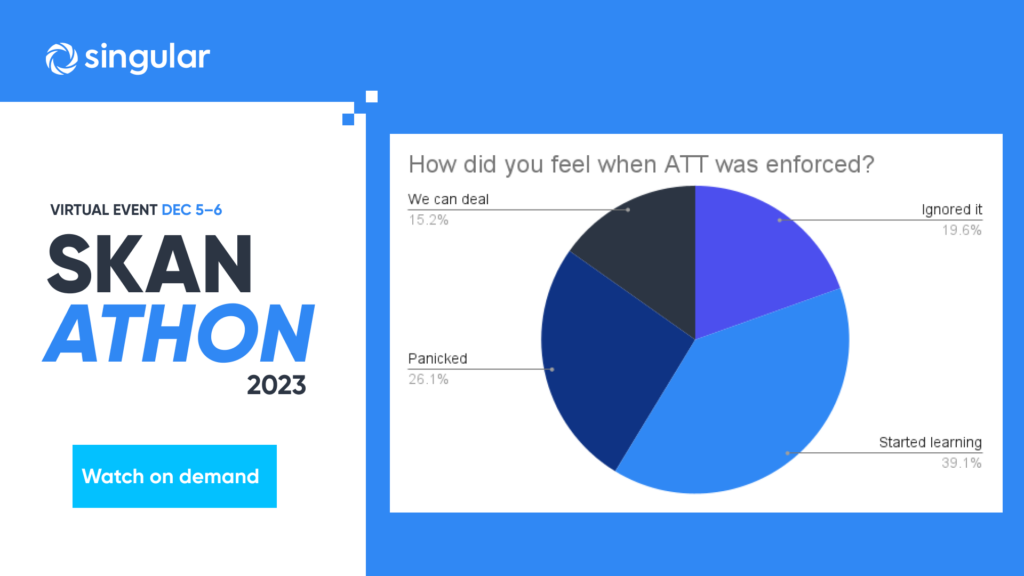
Even now, coming up on 2 years since Apple upended the mobile measurement space with SKAdNetwork, there’s a lot of fear, anxiety, and stress about mobile app install attribution without the IDFA.
Is making everything work again as simple as just being brave?
Let’s put it this way: it’s the first step.
It’s the first step because the initial step of faith starts a new journey for marketing optimization, measurement, and attribution. There are some challenges and minefields on the path. But without the first step, you’ll never arrive at the destination. And the destination, says Claire and others who have arrived, is very much worth the trip.
Crush mobile measurement on iOS …
Step 1 is taking the first step and trying. Step 2 is grabbing every privacy-safe datapoint you possibly can.
Singular VP Victor Savath explains how to achieve “full-fledged iOS reporting:”
“One of the key premises is that SKAdNetwork data cannot operate in a silo. It’s not operating in a vacuum. We still need to rely and lean on all the other adjacent data types to make the best use of the SKAdNetwork framework.”
What data is he talking about?
- SKAN data
- Network-reported data, including impressions and delivery
- Cost data
- First-party device-level data
- IDFV data
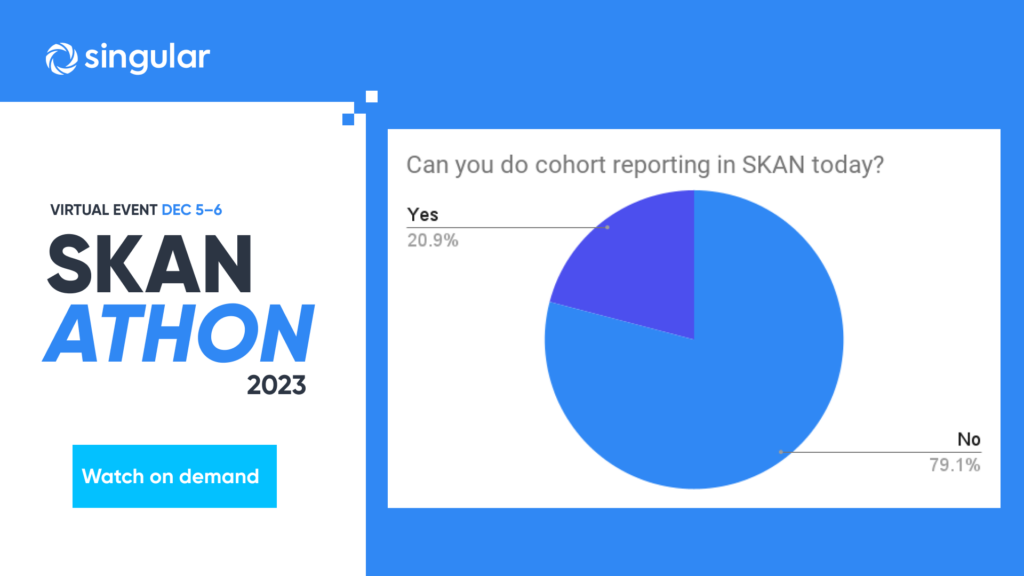
SKAN is critically important, but especially in SKAN 3 with very strict privacy thresholds, you’re going to be missing key insights. That’s where first-party data comes in: if half of the IDFVs who complete task A turn out to be high-value customers/players/users, you can apply that assumption to your SKAN data as well. The same applies for any other data you can capture.
“From our SKAN reporting layer, we have some of the key campaigns, sub-campaign publisher-level data sets,” says Singular customer success expert Nabiha Jiwani. “But at the same time, we are pulling in your network-reported clicks, impressions, cost alongside your postback and conversion value counts to really show you a full-fledged iOS summary report.”
Add in the IDFV data and identify which events are truly meaningful to help segment users and estimate the value of individual cohorts and campaigns.
Making your app work for SKAN
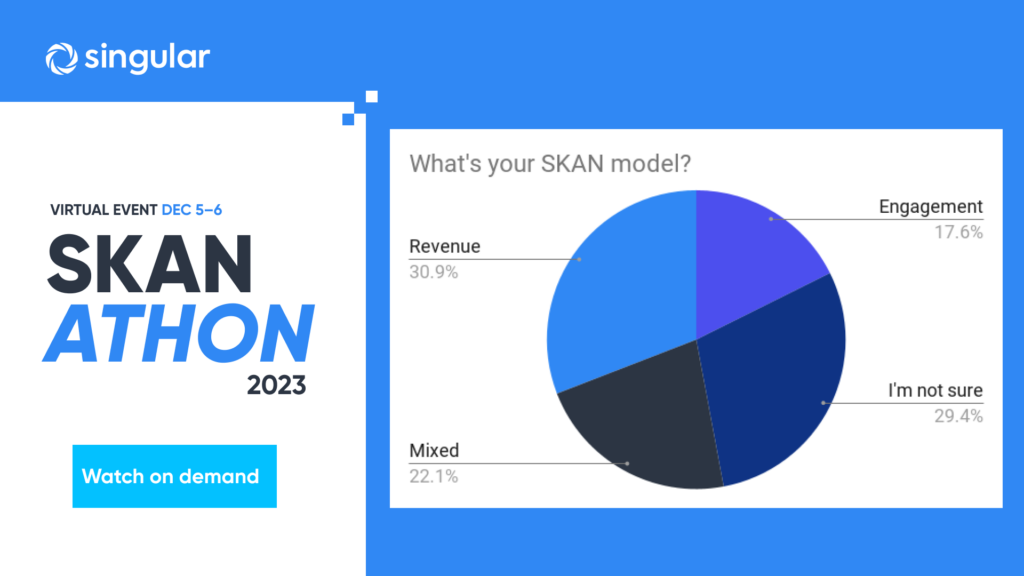
Measurement methodology matters, but making SKAN work for you rather than against you could also require some changes in how you design your app and the funnels you create for users.
There are so many events and such a limited set of data SKAN can return that some get a little flustered, says Jiwani.
“There’s so many different options that I think sometimes folks can get a little bit overwhelmed. So, going back to the drawing board with your marketers, with your UA team, and figuring out what is the user journey and what model makes the most sense is something that can really influence and help enrich your SKAN reporting from the get-go.”
E-commerce apps she’s worked with often want to track big events like registration or add to cart or checkout completed. But there may not be enough of those events relative to the 50 or 75 or 230 users you acquired in Campaign 892 to optimize around them. So you need to find trigger events: antecedents to the big wins that offer predictive insight into those most-desired actions.
Sometimes that may require reconfiguring flows or rearchitecting apps.
“You need a product that is aligned with your model,” says Rozain. “And to have a product aligned with your model, you also need to know your audience and what kind of people you want to target at first from the start.”
Carry1st uses Singular for marketing measurement, of course, but also additional in-app analytics programs to deeply understand user behavior, segment users, and score them.
“I feel like it’s something that is overlooked, especially on SKAN,” she adds. “And when a lot of people gave up on getting whales … some didn’t.”
The implication is that Carry1st is able to use its multiple datasets and smart data science team to still find whales — extreme high-value users — even under SKAN, when theoretically (according to many) that ability died when IDFA became scarce.
Making it all make sense with hybrid measurement
Data science is great, but how do you trust modeled data? There are so many different sets of modeled data now:
- Network modeling to try to recapture conversions obscured by SKAdNetwork
- MMP modeling to reconstitute censored data
- MMP modeling to make predictive insights into cohort value beyond D1 or D2
Number 2 is fairly easy: if you’re getting the event that you’ve titled conversion value 20 about 50% of the time in your actual user base, Savath says, you can assume that the same is true in your SKAN data, even if 25% of the values are censored. Number 3 is getting easier under SKAN 4 and additional postbacks from longer timeframes.
(And the good news is that Singular reports confidence intervals, so you always know the range of possible values.)
To make the data you’re working on better and better, Singular’s building hybrid measurement.
“It’s this idea of how we collect all the different signals,” Savath said.
“We’re going to get Privacy Sandbox data sets coming … more modeled metrics from the various partners … the iOS SKAN 4 data … iOS SKAN 5 data … App Store information.”
And more, of course:
- Network KPIs
- Cost data
- Optimization KPIs
- MMM for broader insights
- First-party data
- And much more …
The magic is in both collecting all the data, using each data type at the right time and for the right purpose, and also using each dataset to in essence sanity check other datasets. The goal is that mobile marketers who understand they don’t have complete deterministic data and never will have that … can still have confidence in their overall performance and metrics.
The goals is also to crush mobile measurement on iOS.
So much more the full webinar
Check out the full webinar for all the insights, including more details into how Carry1st is achieving best-in-class results.