Leveling up SKAN performance: 3 stages of SKAdNetwork effectiveness
“SKAN performance sucks”
“SKAdNetwork is useless”
“Performance marketing is over”
I’ve spent more hours, days, and months in the last two years than I care to count thinking about, talking about, working on, consulting about, and advising on how to extract every possible ounce of marketing signal from Apple’s SKAN framework. Over the course of countless deep dives into data, connectors, conversion models, and SKAN set-ups, a few things have become clear about SKAN performance.
- Everyone’s at a different stage with SKAN
- It’s easy to do SKAN wrong
- When you do it wrong, the data looks … well, insane
- When the data looks insane, it’s easy to give up on SKAN
- But … everyone can get better at setting SKAdNetwork up
- Everyone can optimize their conversion models
- Everyone can get usable signal out of SKAN
- Everyone can still do performance marketing on iOS at scale
I’m not claiming it’s easy. Nor am I saying you’ll get it right the first time around. You may need some help from a tool like Singular’s SKAN Advanced Analytics to model missing data and re-create cohorts, or our latest tech to automatically optimize SKAN conversion models. But — with a little help from friends — you can run high performance marketing campaigns on iOS with SKAdNetwork.
Let’s go through the levels that I’ve seen out there.
SKAN performance level 1: beginner
Not everyone’s an early adopter, and that’s OK. No one can decide better than you where to allocate your finite resources for product development, marketing, and data science.
But here we are.
The App Tracking Transparency reality is people aren’t opting into sharing IDFAs. The tracking reality is that fingerprinting violates Apple’s guidelines and risks getting your app yanked from the App Store. If you’re going to do mobile user acquisition measurement on iOS, SKAdNetwork is the way.
Want to do incrementality instead? Want to do media mix modeling instead?
Sure, go ahead. There is some value in those approaches (and stay tuned for more from Singular on this). But you’ll find the data science, modeling, and tweaking you’ll need to do here outweigh what you’ll need to make SKAN work by an order of magnitude, at least. And do you really want to turn your back on the one deterministic (if aggregate) measurement methodology we still have on iOS?
Of course not.
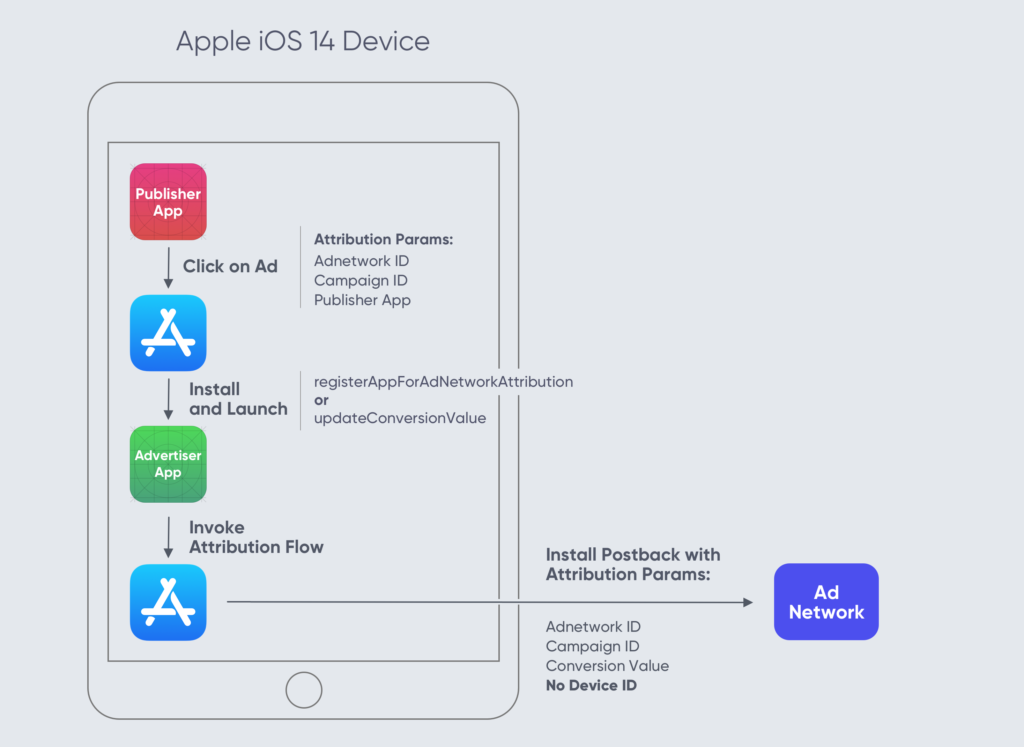
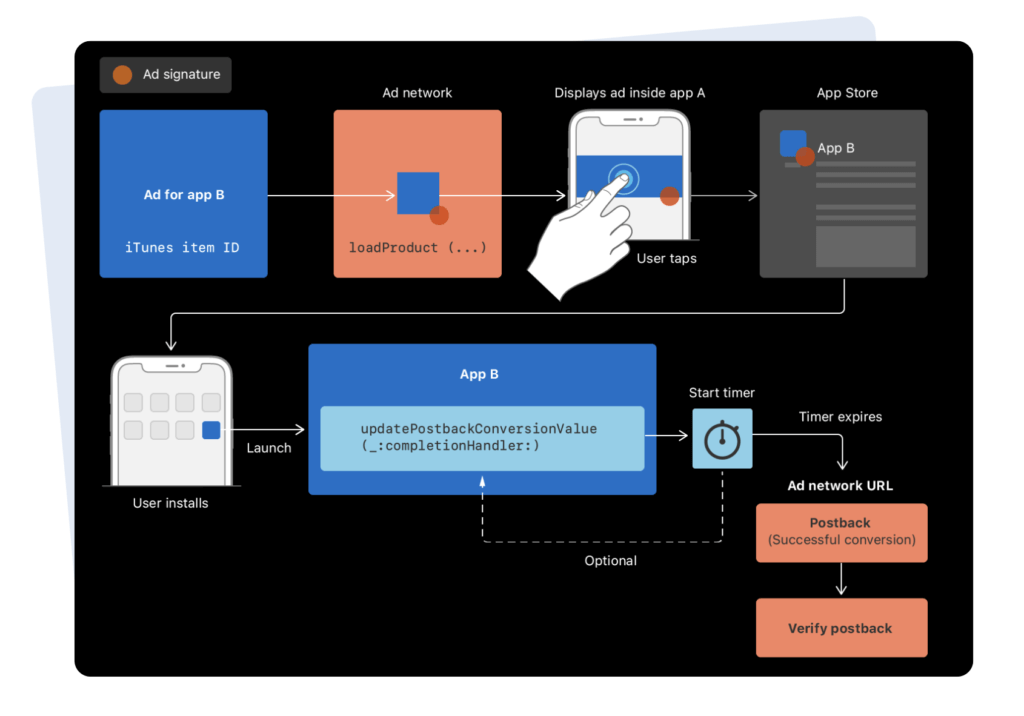
So, here’s how SKAN works in a nutshell
- A publisher app shows an ad for your app (the advertiser app) from a network for a specific “SKAN Campaign ID”
- A person clicks the ad, installs, and launches your app
- Your app, the advertiser app, updates a “Conversion Value” (CV) for that user in the first 24 hours, which is a number between 0-63
- After a random timer of 24-48 hours, their device sends a “SKAN Postback” to the ad network (and you) to report on the new install
- If the number of installs per SKAN Campaign ID passes Apple’s “Privacy Thresholds”, the postback includes the CV
There’s a bunch of problems from a mobile marketing point of view with this model, especially compared to what you had before App Tracking Transparency. The core problem: restricted visibility of post-install events is causing a gap between the data SKAN provides and the data marketers have traditionally needed.
The challenges include:
- Capturing complete SKAN data
- Navigating complexities in SKAN conversion value management
- Dealing with very limited 24-hour data windows, mainly driven by how major ad networks implement SKAN for campaign optimization
- Missing data due to unmet privacy thresholds
The solution has three core parts
The solution has three parts, each of which is essential for optimal SKAN performance: a foundational conversion management system, out-of-the-box SKAN reporting, and advanced data science to model missing data and restore your ability to analyze, optimize, and predict.
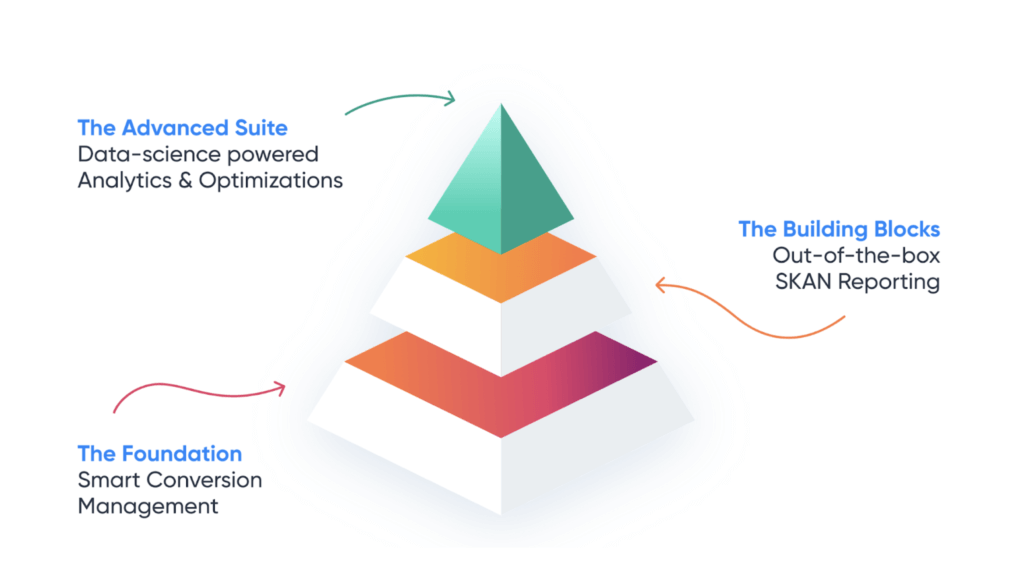
That’s Singular’s solution for SKAN, where:
- The SDK manages all the API calls you need
- Our conversion management technology encodes your conversion values and shares your model with the ad networks you partner with so they understand what good results look like for you and can optimize campaigns
- SKAN reports aggregate and validate all your SKAN postbacks from all your partners, decode your conversion values, and calculate cost per acquisition and return on ad spend
- Advanced analytics return missing data to provide complete visibility into your SKAN campaigns performance
I always recommend marketers start with a very simple conversion model and iterate. Pick events that you can easily validate, and that are highly indicative of high-value users. The events you choose MUST be likely in the first 24 hours post-install.
Also, include revenue buckets in your conversion model (don’t worry, there’s a simple wizard to walk you through setting it all up) if you have in-app purchases or ad revenue. We call this using mixed conversion models, and I’ve seen it result in getting literally 50% more data out of SKAdNetwork.
Worried about getting the right conversion model?
We can help, but most importantly, Singular has automated technology that in many circumstances can detect if there’s a more optimized SKAN model to use and will notify you.
All the major ad networks support SKAN today, so start with whichever one you’re familiar with. Don’t just put a few dollars on it: due to privacy thresholds data returned from below about 20 installs per SKAN Campaign ID will be incomplete and unusable. So drive some scale with each partner and in each campaign. Talk to your partners about how many SKAN campaign IDs they use for internal optimization processes, and get their recommendations for campaign budgets and scaling.
Once you’re up and running, check your SKAN reports in Singular’s dashboard. See if the conversion values look right. Scan through the estimated CPA and ROI numbers and check for anomalies.
Once you’re happy with the results, iterate onward and upward: you’re ready to level up your SKAN performance.
SKAN performance level 2: advanced (optimizing and scaling)
It’s a big leap from wiring up SKAN and defining an initial conversion model to optimizing SKAN, and this big leap is what separates those who find iOS performance marketing success and those who never really get their SKAdNetwork reporting to the point where it becomes a useful tool for user acquisition and growth marketing at scale.
There are a bunch of challenges mobile marketers typically face when they get SKAN up and running:
- Your data looks completely different from what you’re used to and expecting
- You’re not getting enough conversion values
- Which means you’re barely seeing any revenue
- And, of course, there’s no granular device-level information
The result is that your initial performance looks bad, and this is the point where many give up. Persist: there are practices to both optimize and scale your campaigns.
But you have to go beyond the basics.
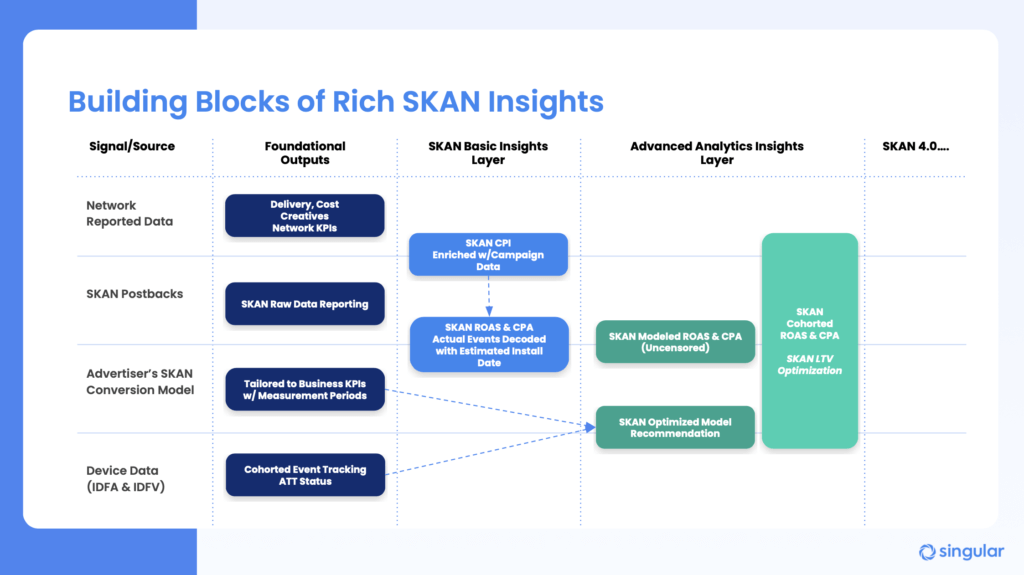
Your foundational outputs in a SKAN world are not just from SKAdNetwork. You have more data than you think: you just need to unlock it, combine it, enrich it, and use it to generate meaning, accuracy, and insight.
It starts with campaign data from ad partners: delivery, cost, creative … all your network KPIs. It continues with all the data you get from the SKAN framework — raw postbacks — and the conversion model you set up that is tailored to just your specific KPIs and measurement periods. (Note for those with multiple apps: this is generally unique to each app.) And then you cap it all off with device-level data that you can still get: IDFAs where you get ATT consent, IDFVs for all your installs. This will help you build measurable, trackable, privacy-safe cohorts.
How?
Singular’s SKAN solution combines all these outputs of your marketing and mobile activity and, in the SKAN basic insights layer, delivers actual SKAN CPI that is enriched with campaign data. Plus SKAN actual ROAS and SKAN actual CPA, using actual decoded events and estimated install dates.
Alone, however, that’s not enough to generate the level of measurement and insight you need to really optimize current campaigns and strategize future ones. The reason is that with missing data due to privacy thresholds and single point-in-time postbacks, the actual hard data that SKAN returns is insufficient.
You also need Singular’s advanced analytics insight layer, which models missing conversion data using your own first-party data, including IDFV, to deliver modeled and de-censored ROAS and CPA, estimated cohorts with ROAS and CPA, and SKAN LTV optimization. All of which unlocks Singular’s ability to automatically check and re-check your operational conversion model and provide recommendations for improvement that will unlock even more accuracy.
Why is optimizing conversion models so incredibly critical?
Our best customers — the smartest mobile marketers we know — test 6 models on average before finding success. (And guess what: when the world changes, when your app changes, when your marketing changes … the “best” SKAN conversion model may have to change as well.)
The ideal SKAN conversion model uses both early signals and strong predictors of high LTV. Revenue is the most accurate predictor, but it’s scarce. Events have a much higher volume, but they’re significantly less predictive. So most user acquisition experts end up using a mixed conversion model using all of SKAN’s bits that includes both revenue and events: 2 bits for 3 events, and 4 bits for 16 different revenue buckets.
(Note: coming soon we’ll have a new mixed model type that will support 3 “preliminary” events and up to 60 revenue buckets. Stay tuned!)
Why is it critical to have so many revenue buckets to achieve SKAN performance?
When you don’t have enough granularity in your revenue buckets, you lose accuracy.
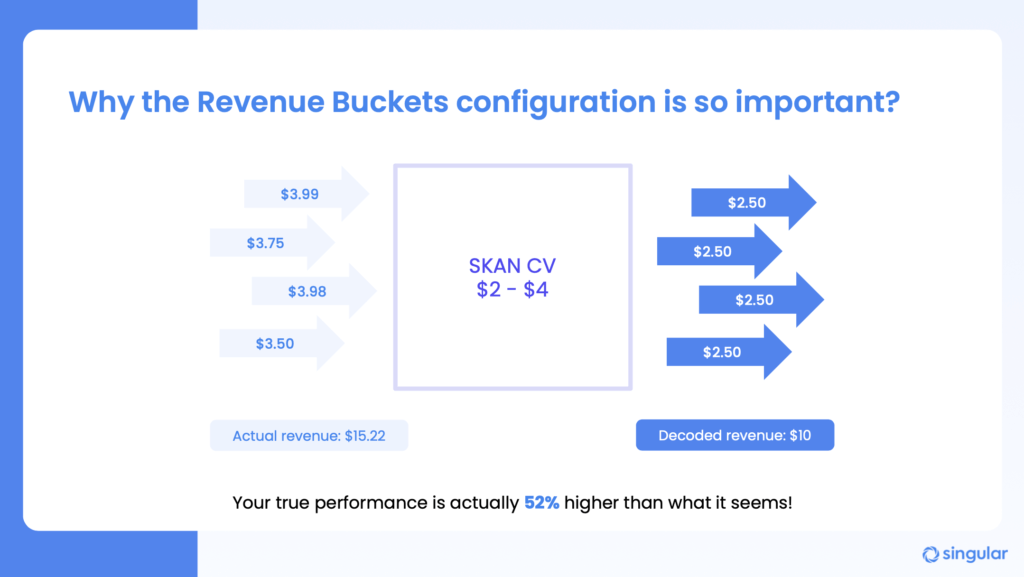
For example, a bucket that’s from $2 to $4 might end up containing events that, on average, cost $3.75. But when you decode SKAN conversions, you don’t know that. So your average estimated revenue might just be $3 per conversion. True performance is significantly higher, but none of your network optimization or internal accounting knows that. Partners can’t optimally optimize (if I can say that) and you report much lower ROI, ROAS, and predictive LTV than you should.
This makes a couple things about SKAN performance really clear.
- Working with your product team is essential to building your conversion model right. You simply have to be in super tight communication so that events and revenue that are likely to happen — and that product incentivizes or guides users toward — are reflected in your conversion model.
- Matching revenue buckets as closely as possible to the actual distribution of revenue — what gets sold at what price points early in your users’ journey — is really, really important.
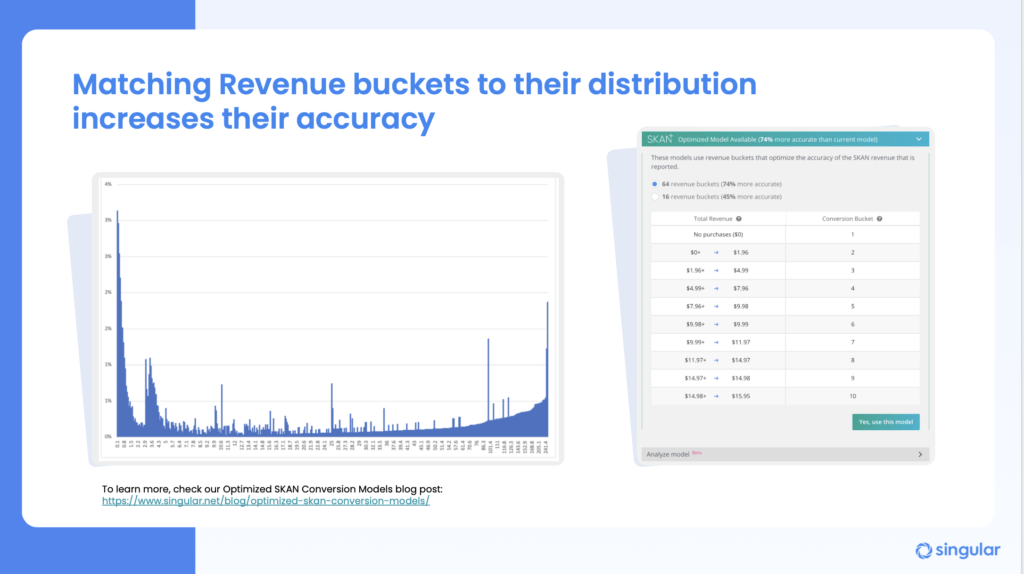
For instance, using 16 revenue buckets instead of 8 can increase accuracy 45%. Using 32 revenue buckets can make you 74% more accurate.
That’s huge.
You have to know the good, and you have to know the bad. As bad as it is being unable to optimize campaigns that are working well BUT YOU DON’T KNOW IT, it’s even worse to be unable to optimize campaigns that are failing … but you also don’t know it …
All because your individual revenue buckets are simply too big.
Best practices for optimizing SKAN conversion models
As you work through your 3 or 6 or 9 different steps of getting to the perfect SKAN conversion model for your app, here are a few things to keep in mind.
- Keep at least one baseline event to ensure your conversion values make sense, and to get at least SOME signal if revenue doesn’t happen
- Ad revenue is a massive advantage: it’s very useful as a short-term early indicator. (Of course, this depends on your app and its category.)
- Creativity is critical. Think — and check the data — for user actions that are predictive of future revenue activity.
- And, again, revenue bucket ranges are critical for accuracy. Define these based on your observed user behavior, or try our recommended models.
You will arrive at a solid conversion model and you will get good data … if you’re persistent. It takes time and effort, so a little bit of patience is a good thing too!
Understanding privacy thresholds to maximize SKAN performance
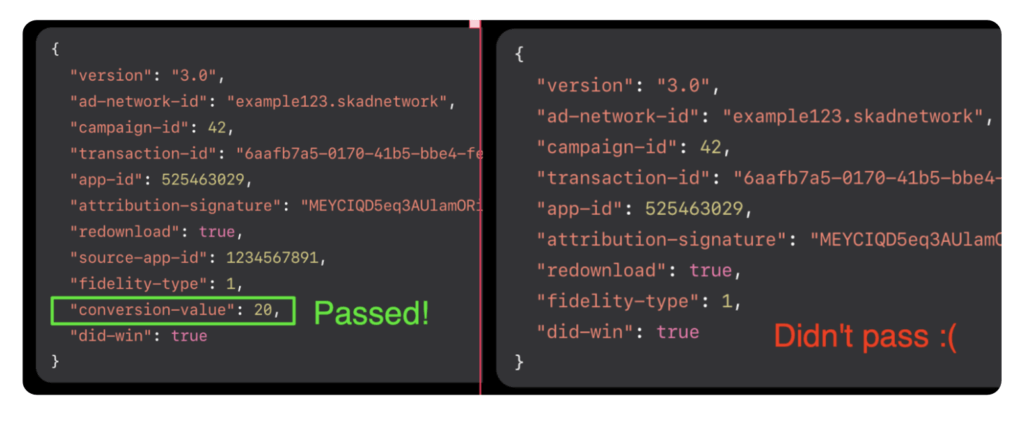
None of the above matters if you don’t understand privacy thresholds in SKAdNetwork and optimize your campaigns to minimize data loss via censorship. Postbacks without conversion values give you some signal, but it is insufficient to optimize.
The SKAN framework decides whether or not to censor conversion values at time of install. It’s not related to what the user does or who the user is: it’s simply predicated on how many installs you’ve generated per SKAN campaign ID in the last 24 hours.
You need at least 10-15 installs to get conversion values. Over 30 per SKAN campaign ID is better, and obviously, with more scale, you increase the percentage of SKAN installs that come with SKAN conversion values, thereby increasing accuracy.
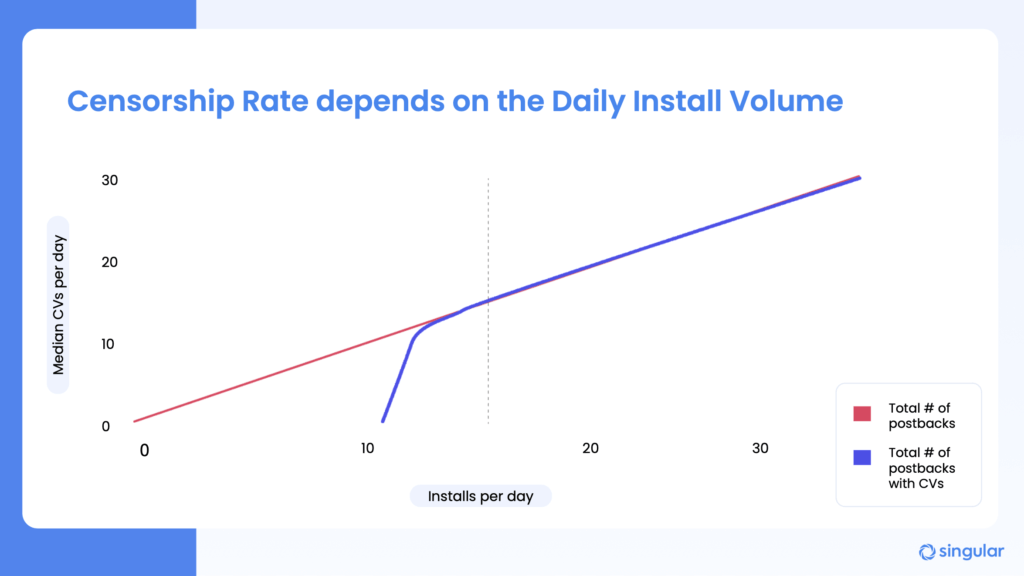
As we’ve seen multiple times from multiple customers and partners, daily install volume is your friend when seeking to optimize the percentage of SKAN postbacks with conversion value payloads.
But there’s a catch.
Just because you have something classified internally as a single campaign doesn’t mean it shows up in the SKAN framework as a single campaign ID. Ad partners will often decompose a single campaign into multiple SKAN campaigns in order to test placements, creative, or other elements of your ads so that they can run their own optimization engines. Since censorship happens at the campaign ID level, this can reduce signal fast if you’re not pumping enough volume into each partner.
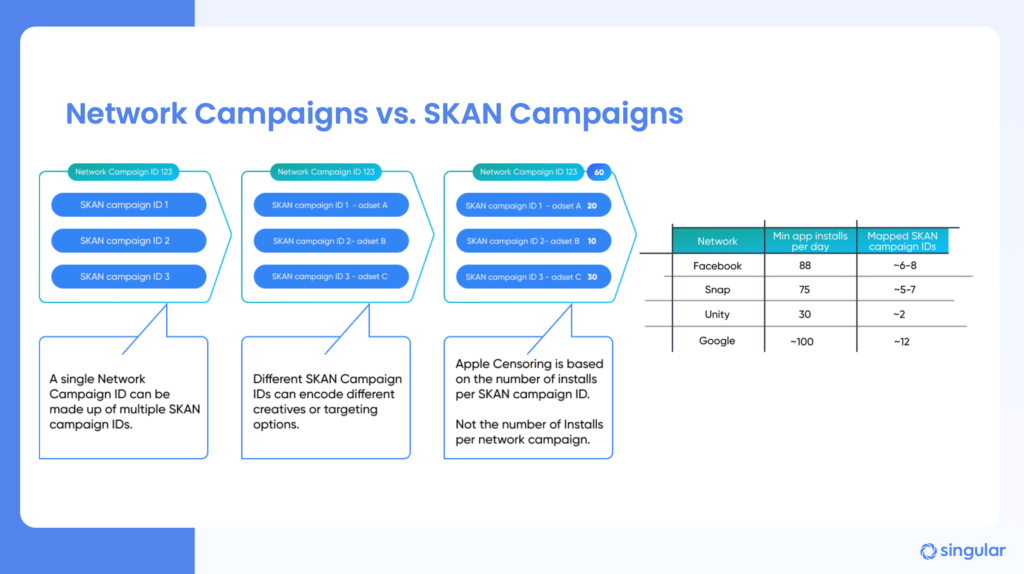
The solution is communication.
Talk to your partners about how they break down campaigns into different SKAN IDs, and how much volume they typically distribute in each one. Use that data to inform how much volume to run with each partner. And, while this may take some juggling as you experiment with new partners, concentrate spend in periods of time to ensure maximum signal delivery.
One other thing: don’t panic.
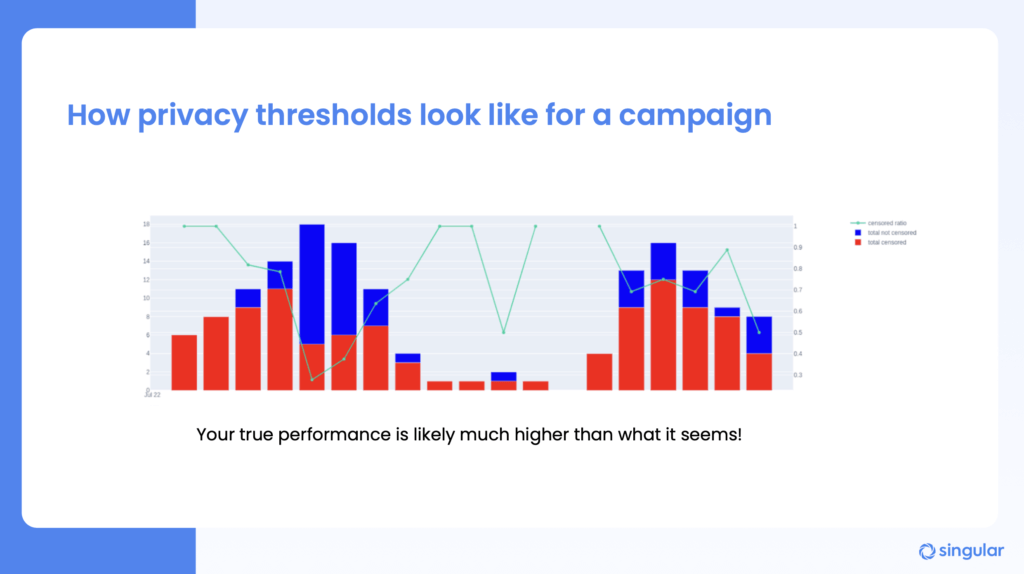
Performance might look like it really sucks early on in your SKAN journey. And it may not look amazing even when you become advanced SKAN users. But your true performance is almost certainly much higher than what it seems.
And you can see that with our modeled metrics.
Singular’s Advanced SKAN Analytics pulls back the curtain on censored values, estimates your missing conversions and revenue, and is completely upfront about the confidence intervals so you know exactly how much to trust the insights. This single step can increase your visible SKAdNetwork performance by 50%, which is absolutely huge and gives you the confidence to run performance marketing at scale on iOS, knowing what your return on investment is.
Two keys to keep confidence intervals tight and to improve the accuracy of your modeled metrics:
- Consolidate campaigns to reduce missing data due to privacy thresholds
- Use optimized conversion models to get more accurate inputs
Bringing cohorts back to iOS
With easy IDFA access, mobile growth marketers had the ability to monitor cohort ROI and LTV performance over the long term. The biggest limitation of SKAN v3 is the incredibly short window: essentially 24 hours in most cases thanks to the optimization needs of ad partners.
That is just not enough time to really know how performant a campaign has been or how good a cohort of users it brought in. Longer cohorts give users more time to use your app, develop a habit, and convert into highly engaged paying customers. Just because a new player doesn’t buy something in your game immediately does not mean they won’t become one of your most valuable players down the road.
Time makes a huge difference in campaign analysis … often 2X to 5X just between D1 and D7!

Singular revives long cohorts on iOS by combining SKAdNetwork-derived conversion data with actual device-level data: what does SKAN say you did, informed by aggregated data about what actually happened in your app. The result is modeled data, with confidence intervals, showing what a particular SKAN campaign delivered in D7 revenue.
Bringing all your insight layers to life
Advanced mastery of SKAdNetwork requires bringing all of these insight layers together in one place. That includes:
- Partners
- Publisher apps
- Campaign names
- Foundational outputs
- Cost
- Impressions
- SKAN-reported installs
- SKAN basic insights layer
- SKAN eCPI
- SKAN revenue
- SKAN ROI
- SKAN Advanced Insights layer
- Modeled metrics
- Modeled SKAN revenue
- Modeled SKAN D7 revenue
- SKAN Cohorts
- Modeled SKAN ROI
- Modeled SKAN D7 ROI
- Modeled metrics
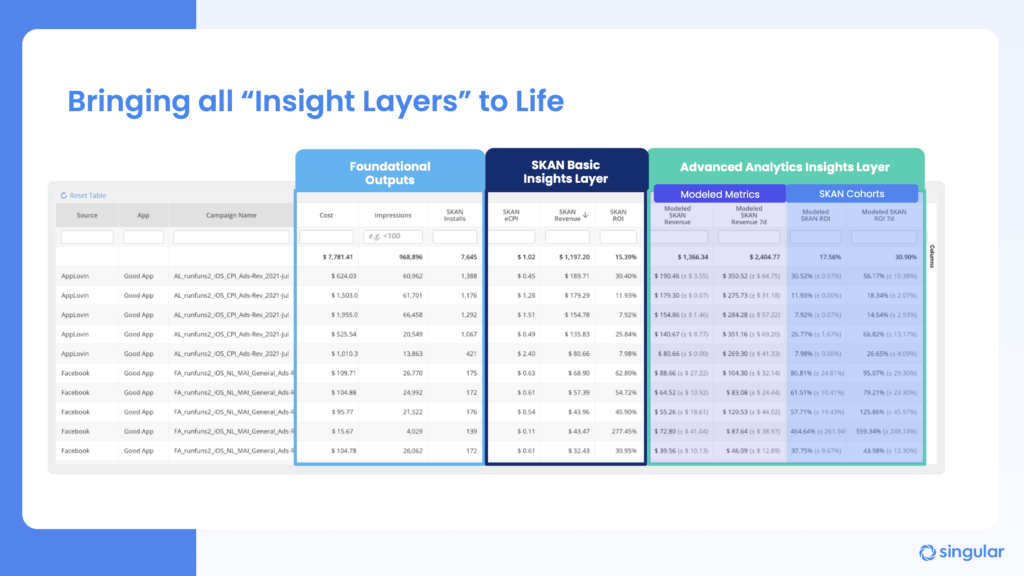
Now, at last, you have the tools you need to accurately assess the result of your iOS user acquisition campaigns. Now you have the data you need to make decisions about future growth.
Key indicators of advanced SKAN experts
SKAN experts consistently do 5 things that others don’t.
- Continuously test and iterate different mixes of conversion models
- Use optimized revenue buckets to increase model accuracy
- Rely on modeled metrics to overcome SKAN’s privacy thresholds
- Consolidate campaigns in case of high censorship rates
- Use modeled longer cohorts to understand your true ROI
It sounds simple when you put it in 5 steps. It’s really not, and some of the world’s best marketers and best mobile growth teams have struggled with SKAdNetwork like no other measurement framework ever before.
But the good news is that there is light at the end of the SKAN performance tunnel. You can make SKAN function. And you can make SKAN-assisted attribution the foundation of high-performing mobile marketing.
But wait, there’s more on SKAN performance (later!)
Right up at the top of this way-too-long blog post, I said there were 3 levels of SKAdNetwork effectiveness. Readers who can count may have noticed that we’ve only covered 2 of them so far.
There’s a good reason for that, and it’s not only that I’m tired of writing such a long blog post, or that you’re tired of reading it. It’s simply that level 3 will come with SKAN 4 later this year.
As you’ve heard, SKAN 4 is a massive change to SKAdNetwork. It’s also a massive upgrade, providing significantly more data (while remaining privacy-safe) and covering a significantly longer time frame. We’ve written a lot about SKAN 4 already, which you can check out in these blog posts:
But the reality in terms of leveling up with SKAN 4 performance is that it’s simply not here yet. It’s going to enable much more (and require much more), but we’ll have to share more about how to make it work and perform well after it’s released, not before.

And … keep tuned
We are always working with our very best customers to reveal top techniques and insights on iOS attribution and everything else you need to do. Keep tuned to stay in the loop.

Stay up to date on the latest happenings in digital marketing

