Migrating Our Events Warehouse from Athena to Snowflake
At Singular, we have a pipeline that ingests data about ad views, ad clicks, and app installs from millions of mobile devices worldwide. This huge mass of data is aggregated on an hourly and daily basis. We enrich it with various marketing metrics and offer it to our customers to analyze their campaigns’ performance and see their ROI.
The upshot is that we receive tens of thousands of events per second and handle dozens of terabytes of data every day, managing a data set of several petabytes.
Migrating this vast and complex data warehouse from Athena to Snowflake was a complicated process. This post will discuss why we decided to take this difficult step, how we did it, and some lessons we learned along the way.
Snowflake vs. Athena
We started using Athena in 2018 as our user-level events warehouse. It looked like an excellent solution since it separates computing from storage, easily integrates with S3, and requires low effort. It felt a bit like magic.
We streamed user events through Kinesis streams and uploaded the data to S3, partitioned by customer and day. The files were saved in S3 using Athena’s best practices as much as possible.
But after a year in production, issues started cropping up, leading us to explore other solutions.
Lack of Computing Resources on Demand
The first painful issue was the need for scale as well as high computing power on demand. Athena is a multi-tenant service, and you don’t have control over the computing power a query will receive. Since our production pipeline runs about 4,000 queries an hour and heavy queries once a day per customer, we experienced failures at peak hours due to a lack of computing resources.
Poor Resource Management
You can’t split and control the computing resources according to usage; for example, when some data sets have to be queried faster than others (hourly query vs. a big daily query). We wanted to give some performance guarantees to our customers, but we had no control over the computing resources.
Lack of Out-of-the-Box Clustering
We had to buffer customer-level data for some time (or by size) before uploading it to S3. Buffering isn’t a good practice for a streaming pipeline, and it didn’t perform well when we had high data throughput. Buffering also affected our data update cadence in our aggregated reporting.
Tedious Deleting and Updating of Specific Records
We are obligated to support deletions of specific records when end-users demand it, to comply with EU privacy laws (GDPR). In Athena, deleting specific records from files is a long and complicated process.
Why Snowflake?
Our decision to migrate was based on the fact that Snowflake supports these critical features by design:
- You can control the query computing power by planning your warehouse’s usage correctly. You can split different queries to different warehouses with varying instances, granting more resources where you need them.
- You can cluster data in Snowflake’s micro-partitions by defining a cluster key and sorting the data according to it when ingesting it. You can also use auto-clustering to optimize the micro-partitions according to the cluster key. By clustering your data wisely according to query usage, you can significantly optimize your queries.
- Deletions are simple in Snowflake, mainly if they’re based on the cluster key. Updating specific records is still expensive but much more efficient than in Athena since you can separate the computing power and scale it as needed.
Pre-Migration Step: Proof of Concept
When we planned a POC with Snowflake, we wanted to test all the types of usage our system would need. We divided the POC into three main categories: reads, writes, and deletions.
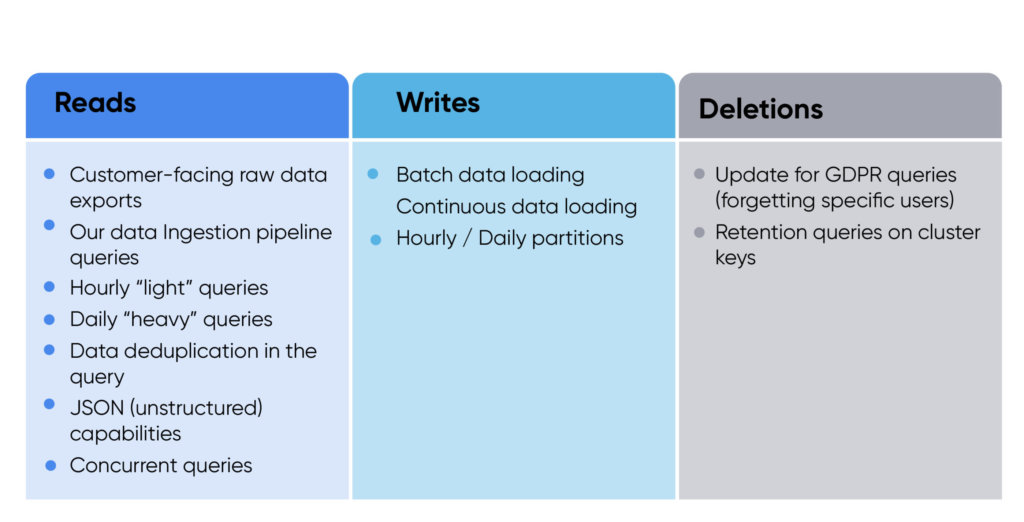
Setup requirements included one day of data of all customers (around 100 TB); multi-tenant table; and indexing (no cluster keys, one cluster key, and two cluster keys).
We had four success criteria:
- Loading data on time: We needed our data ingestion pipeline POC to prove that it will be fast and cheap.
- Support for existing queries: We needed to prove that we can run our current queries on Snowflake.
- Meeting query SLA: We tested query duration, ensuring that the only way it was improved was through migration to Snowflake.
- Cost requirements: We wanted to make sure that running our production load on Snowflake will be cheaper than Athena (this wasn’t the primary project metric, but it was important not to raise our costs).
Our Snowflake POC was successful in all aspects. In addition, Snowflake’s team was both accommodating and helpful.
Building a Robust Ingestion Pipeline
Requirements
We knew that we had to build a Snowflake ingestion mechanism that filled all the following needs:
- Robust and durable. The volume of data we ingest into Snowflake can increase dramatically over a short period, so our ingestion pipeline must scale accordingly. A drastic increase in traffic to one of our clients can happen quite suddenly and can occur from both planned and unplanned events. A significant piece of news can cause a surge in social media activity, for example. This kind of abrupt traffic overload has happened in the past. Therefore, we must plan and build our ingestion pipeline in anticipation of a sudden doubling of our overall data volume. We need to be able to scale easily.
- Fast. The load process must meet specific SLAs. Our customers need to pull user-level data with only a few minutes’ delay. We have to make sure that Snowflake does not delay data availability beyond that threshold.
- Highly available. We cannot afford downtime. Customers start to notice when new data is delayed for more than one hour.
- Optimized for our most common query usage. We’re querying Snowflake over 4,000 times an hour to keep our aggregated reporting up to date. To ensure we have optimized query plans, we need to be sure our data ordering and clustering are as prepared as possible for that usage scenario.
- Compliant with all privacy requirements, such as data retention and data segregation at rest. Some partners require different retention rules on their user-level data. Some partners need to segregate their marketing user-level data at rest completely. We had to support these privacy-related features. In Athena, we handled that by creating different files in S3 (which decreased file sizes, negatively impacting Athena’s performance). In Snowflake, we could use other tables to segregate and define different retention rules for each partner if necessary.
We decided to build our Snowflake ingestion pipeline as lean and self-healing as possible.
Design
Here’s a closer look at our design:
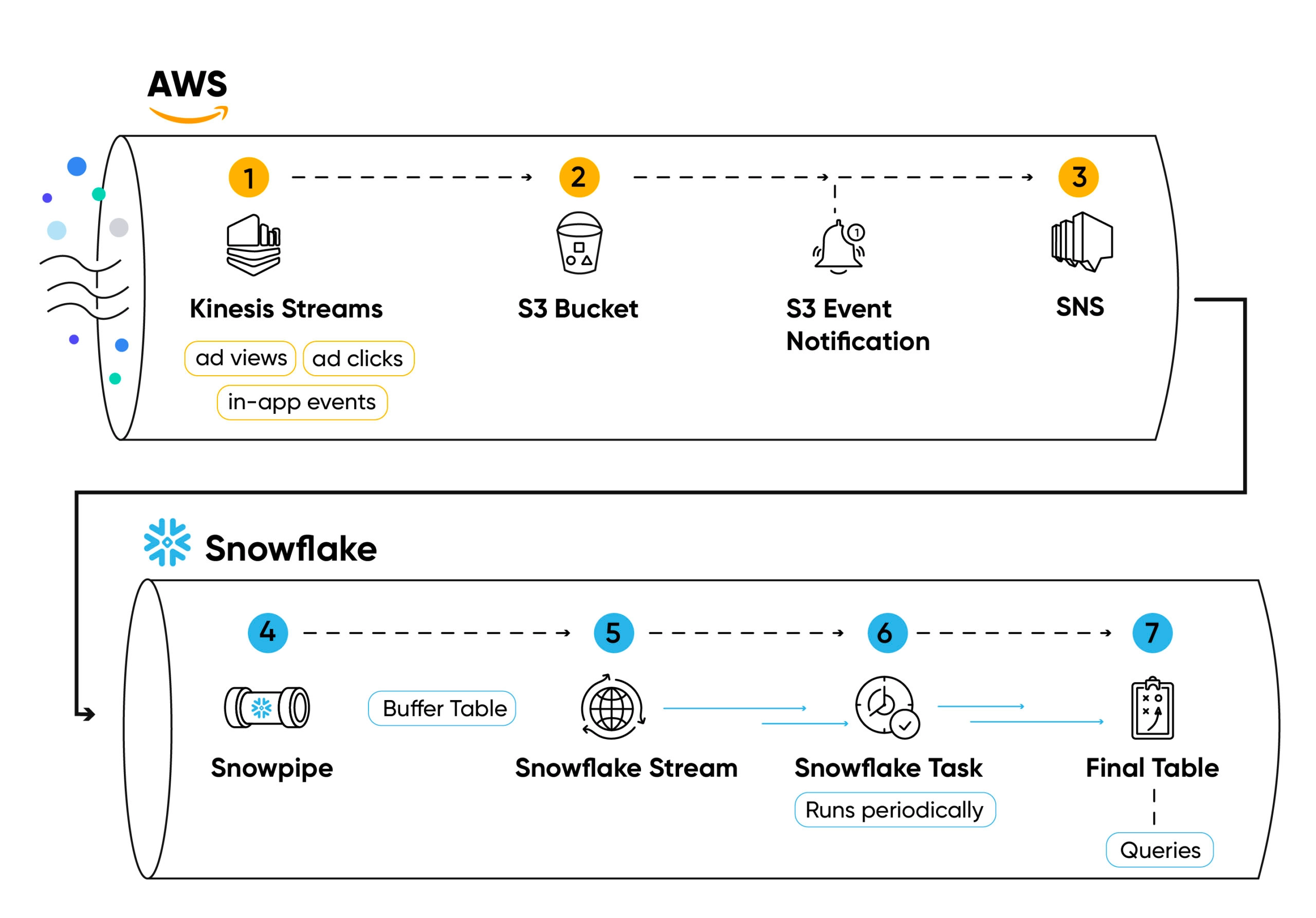
We stream user-level events in Kinesis streams from Singular’s stack (1).
The events (such as ad clicks, ad views, app installs, or in-app events) are read from the stream in a batch-like manner, saved into a .csv file (compressed with zstd), and uploaded to S3 files using Python workers (2) managed by Kubernetes.
Every file creation creates a notification in an SNS topic (3), subscribed by Snowpipe (4).
Snowpipe then inserts the file’s content into a buffer table (5) on every file added to the bucket, using the COPY INTO command.
The data saved in the buffer tables is not clustered or ordered, so utilizing it for aggregated queries won’t be efficient.
To ensure data is organized and optimized for querying, we define a stream (6) over the buffer table.
We then use a Snowflake periodic task (7) to query the stream, sort the data, and insert it into a final table (8).
Snowflake Services
These are some of the major Snowflake services we used:
- Snowpipe: A Snowflake-managed queueing service that copies data into Snowflake tables from external sources, such as S3. An SNS topic can trigger Snowpipe, so every file you save into an S3 bucket will be copied into a table in Snowflake. Snowpipe’s computing costs are supplied by Snowflake and don’t use a user-defined warehouse.
- Streams: A Snowflake service you can define on a table in your database. Every time you read from the stream, it’s reading the data in the table since the last read, so you can take action using the changed data. It’s a streaming service (like Kafka/Kinesis) but implemented on a Snowflake table.
- Tasks: Snowflake periodic tasks are an excellent tool for consuming the data from the streams into another table if necessary. We’re utilizing Snowflake tasks as a batching mechanism to optimize micro-partition depth.
Monitoring, Self Healing, and Retention Handling
To make sure our Snowflake pipeline can withstand sudden data bursts, we used some cool Snowflake features in addition to building a few internal tools.
- Warehouses optimized for ingestion: We split our “heavy-duty” and “lightweight” ingestion sources to different warehouses, according to usage.
- Horizontal auto-scaling: All of our warehouses are multi-cluster and scale up horizontally when needed.
- Task failure monitor: Snowflake’s tasks mechanism handles sporadic failures easily. When tasks fail, they are just retired from the same checkpoint they failed on. The problem for us was that every time a task runs, it pulls all the stream data. If the stream contains too many rows of data, the task may time out (or just take a long time). Ingestion lags due to data bursts would be very costly to manage. We tackled the problem by building an internal monitor that reads Snowflake’s task history and checks if a task is taking too long. If it is, the monitor kills it, scales up the warehouse, and reruns it. Later, it scales the warehouse back down to its original size. This monitor—a function that couldn’t be fulfilled quickly using existing services—turned out to be a lifesaver.
- Data retention: We handled data retention efficiently using periodic tasks every day and deleted data older than x days (changes by marketing source/customer). Snowflake’s DELETE commands are efficient and non-blocking, especially when running them on the cluster key (for example, deleting whole days of data).
Every hour, Python Celery tasks in our ingestion pipeline query Snowflake on the ingested data.
Handling Scale
The different ways we use Snowflake in Singular add up to a unique querying pattern:
- Singular’s aggregated data ingestion pipeline: Running hourly aggregation queries on each customer’s data.
- Customer-facing ETL processes: Singular’s ETL solution queries raw data every hour and pushes it to customers’ databases.
- Customer-facing manual exports: On-demand exports of raw data.
- Singular’s internal BI.
- GDPR “forget users” queries: Specific row updates, running in batches every day, handle GDPR forget requests.
We execute thousands of queries every hour, and we need them completed quickly over a large variety of data volumes. Moreover, we need Snowflake to update specific rows with minimal effect on data clustering. Our querying processes run periodically in a distributed manner on Python Celery workers.
When we started migrating to Snowflake, we assumed we would need to manage the virtual warehouse sizing according to usage and scale. With our distributed query pattern, it’s natural that each worker will query Snowflake directly, which opens a new session with each query. This means we soon encountered Snowflake’s soft limits on concurrent sessions (different from concurrent queries, which Snowflake handles practically without limitations).
The good news is, you don’t need to be limited by sessions in Snowflake—you can run asynchronous queries, bound only by the warehouse queue size. We chose to take advantage of this and create a pool of live sessions that tasks can be run from. By design we planned it to be completely asynchronous and stateless, so it would be only limited by warehouse usage. Building a stateless Python ASGI server that manages our connections was a rather simple and elegant solution for us.
We implemented our Python Snowflake connection pool service using SqlAlchemy Snowflake integration, Uvicorn and FastAPI. And we plan to open-source and share it with the community soon, so others building applications on Snowflake can save time and effort when creating their own session pools.
Currently, using our Snowflake connection pool, we’re running over 4,000 queries an hour on several Snowflake virtual warehouses. Virtual warehouses automatically scale horizontally if needed. Our GDPR updates are running on a large dedicated warehouse, so complex UPDATE queries are running efficiently. The virtual warehouse is automatically suspended when no requests are processed.
Data Validation
Singular customers rely heavily on our data for their business operations. We couldn’t afford any data discrepancies when migrating from Athena to Snowflake.
While running both ingestion pipelines in parallel, we built a continuously running monitor that compared the querying on Athena and Snowflake for each file uploaded to S3. That way, we immediately knew if there were data ingestion issues. In addition, we launched a Snowflake query and compared the results for every Athena query we ran in production.
Building this monitor helped us validate that the data migration was being done correctly and with no inconsistencies.
Other Lessons Learned
When the migration was complete, we examined our credit usage and setup more closely and found a few easy ways we could optimize:
- Plan warehouse usage according to use. For instance, our “heavy” queries run once a day (all launched simultaneously) on a large-scale warehouse with auto-suspend on, while our hourly “light” queries run on a smaller warehouse with higher horizontal cluster scaling. This ensures that our daily usage is cost-optimized (running heavy queries fast and suspended most of the time). Our hourly queries have the necessary elasticity for their concurrency scale.
- Work with Snowflake to understand the costs of cloud services. We discovered that our heavy query pattern created a heavy load on the query compilation time when calculating NDV on the table. Snowflake helped us by changing the feature configuration. It saved us a lot of query compilation time that our query types didn’t need for our specific use case (querying new clusters only on a heavily updated table).
- Query optimization: We optimized the duration of many of our queries using the Snowflake profiling tool. It helped us with complex queries like GDPR updates.
What’s Next?
- Data sharing: There are fantastic opportunities regarding secure data sharing with Snowflake. We’re working with the Snowflake team on leveraging the idea of a distributed clean room for secure data sharing.
- IP obfuscation: We had to implement 30-day retention on IP-related fields to keep our security seal certificate. To do that, we implemented a cool and efficient flow, utilizing Snowflake masking policies and session variables to save all of our IP-related fields encrypted and decrypt them only on demand. We’re planning on publishing another blog post deep-diving into our solution.
- Open-sourcing the connection pool: We plan to open-source our Python Snowflake connection pool service in the upcoming months. If you think that this might be useful to you—for example, if you plan on running a large number of queries every hour—reach out and let us know!
This blog was originally published on Snowflake’s blog.

Stay up to date on the latest happenings in digital marketing

