SKAN 4 deep dive with Singular CEO Gadi Eliashiv (with your questions answered!)
SKAN 4 is here. Now what are you going to do about it?
I’ve seen such a range of opinion from the marketing community about SKAN 4. Most are happy there’s more measurement. Most are happy there’s more detail. Most are happy there’s more clarity. But most are also still trying to figure it all out. Many are poring over small details in the documentation looking for answers to questions that don’t seem obvious. And some are just reeling from all the complexity.
So Singular CEO Gadi Eliashiv and I spent an hour live on LinkedIn last week going over SKAN 4 in detail and taking marketers’ questions on the updated SKAdNetwork framework:
- What’s new
- What’s good
- What’s confusing
- What’s unfortunate
- And yes, what’s ugly
Watch the video above to get everything (or subscribe to our Growth Masterminds podcast to get it in audio form.)
Here are a few highlights …
First, the positive on SKAN 4
There’s a lot to like about the new SKAdNetwork version 4, as we covered in detail in our first post, as well as our Singular product updates post:
- More postbacks (!!!)
- More data in the first postback (potentially)
- At least some data even if you have very low numbers per campaign
- A pretty powerful new Source Identifier
- Web to app capability (but only for Safari)
- More clarity around crowd anonymity
- Earlier postbacks via locking conversion values
There’s a lot to keep straight in SKAN 4. Here’s a chart that helps you kind of see it all at once:
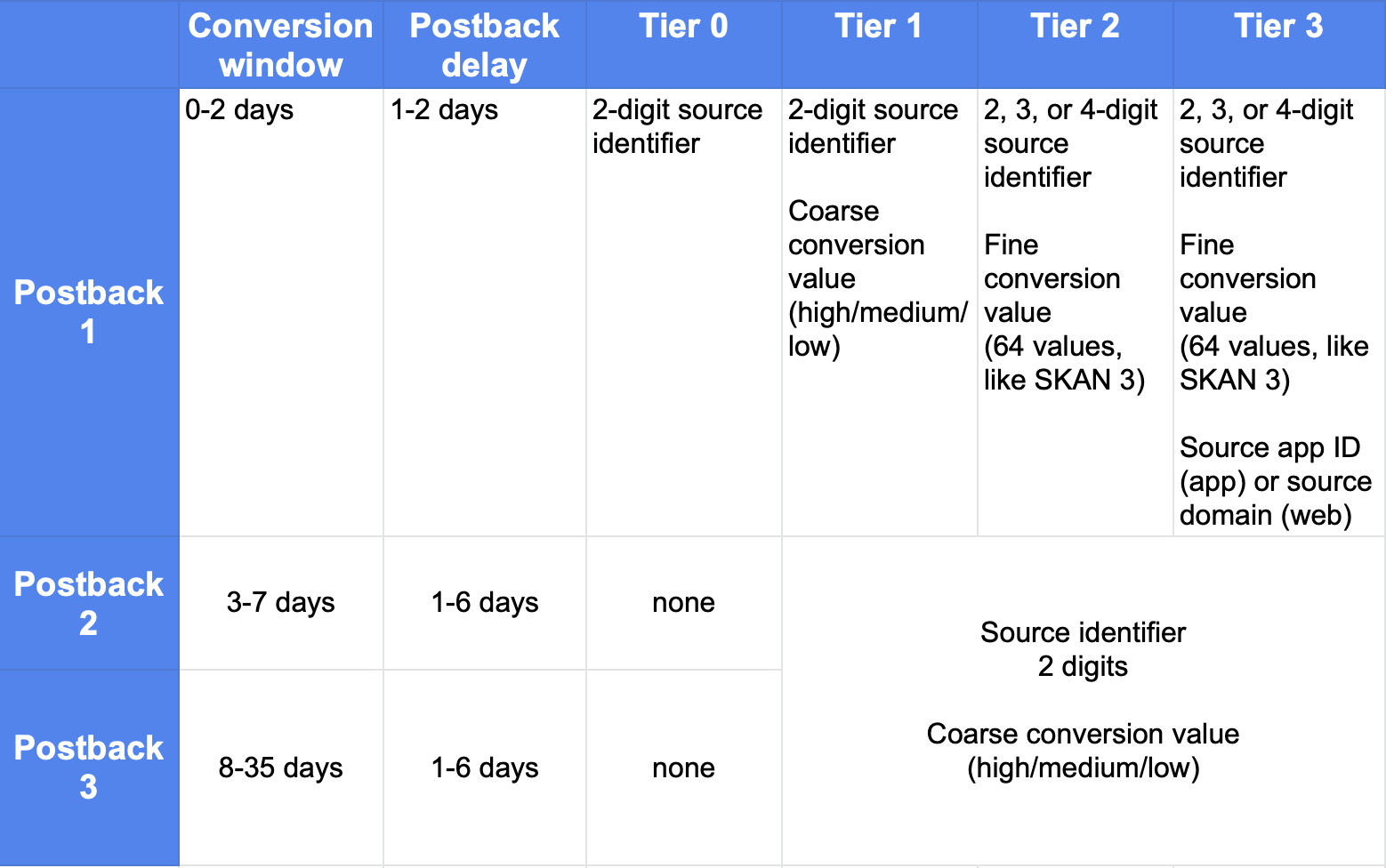
The interesting challenge of SKAN 4 is an amplification of the same one in SKAN 3: balancing granularity with experimentation.
Maximizing granularity, or the amount of data you get from each conversion and install, requires concentration: focusing resources on a limited number of partners and campaigns to ensure you achieve Tier 2 or Tier 3 amounts of data return from SKAdNetwork. But finding the best sources, targeting, partners, and creative requires experimentation around all of 3 of those important factors.
Finding the right balance between the two needs will be critical.
But there’s still some ugly, too
There’s still debate in the mobile marketing community over exactly what certain sentences or paragraphs in the SKAN 4 documentation mean under real-world conditions, and we won’t really have a sense for what kinds of volume define the tiers until app publishers are running ads at scale.
Here are some of the key challenges in SKAN 4:
- Time: it’s going to take months for the ecosystem to support
- Work: all the partners in the mobile adtech value chain have some work to do, especially ad networks who now have to figure out how to optimize campaigns based on this new reality … just months after some of them kinda figured it out on SKAN 3
- Confusion: many will be dealing with multiple versions of SKAN in the wild, requiring support for SKAN 3 and SKAN 4
- Other mysteries: some things we won’t know for a long time. One example: exactly how do the crowd anonymity tiers work, and what volume will marketers need to drive to get maximum data?

Living in a SKAN 3 version of a SKAN 4 world?
It’s actually interesting when you think about it: if you don’t care about the richer data that SKAN 4 has to offer, could you essentially live in a SKAN 3 version of SKAN 4?
In other words, if you totally didn’t care about aggregating volume in source IDs, you’d basically get what SKAN 3 was giving you:
- 1 postback
- A 2 digit source identifier
- At Tier 0 of crowd anonymity
The question is: would this offer more data at lower data volumes than the existing SKAN 3? One of the presumptions in the mobile marketing community, based on some extrapolation of what Apple has said, has been that Apple wanted to provide more data at low volumes, as well as significantly more when higher volumes protecting consumer privacy justified it.
So it could — I emphasize could — be the case that you’d get more data in SKAN 4 without really trying anything different than you did in SKAN 3.
It’s unlikely that many advertisers will adopt a strategy like this, and we’ll know more about required volumes for data as Apple’s new attribution framework grows in the wild. More data is better, generally.
But some might be tempted …
One thing is guaranteed: it’s now more complicated
The goal at Singular is to abstract all of the complexity and just let marketers do their jobs. But while it will get simpler, that’s is literally an impossible task.
Just having more postbacks means you’ll now need to think of additional events in your app to report on. And having the possibility of getting both fine and coarse values for postback 1 means you’ll need a conversion schema to sync up fine and coarse values into a single understandable and actionable framework of KPIs and value.
Something like this, for example:
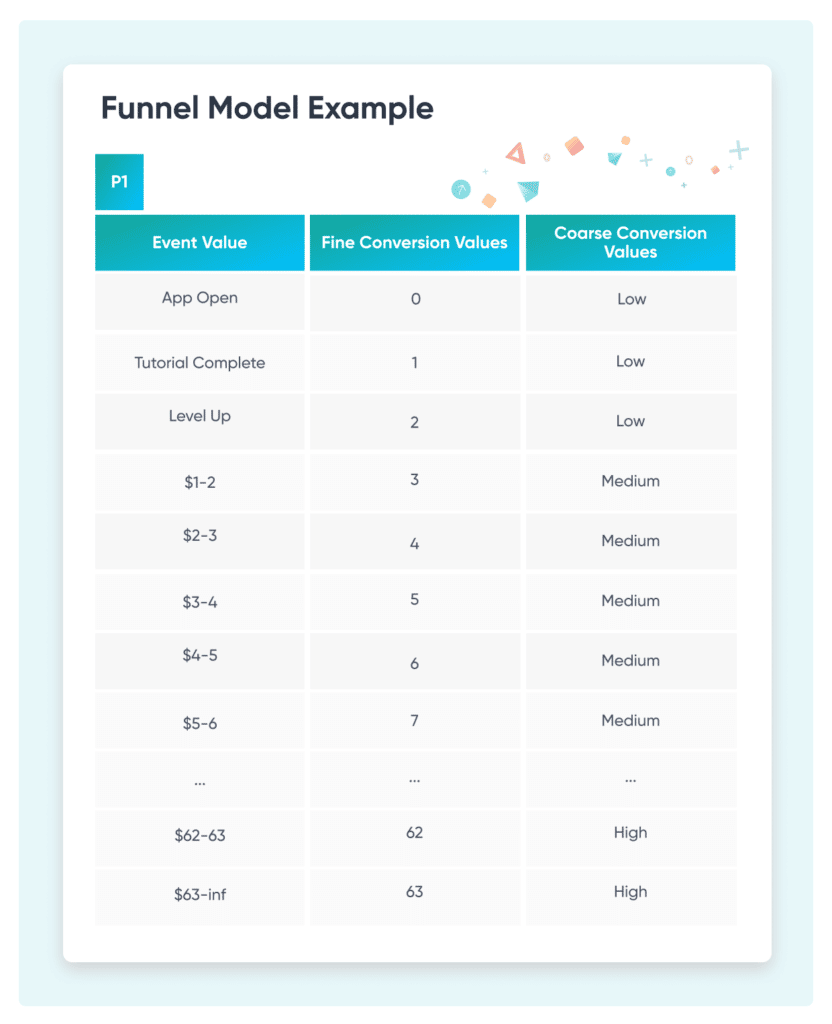
Plus, you’re now able to lock conversion values. That’s a positive, and gets you data earlier, but it also spreads cohorts over more time. Which, of course, are already being elongated by the now-much-longer random timers for getting your postbacks after their conversion windows: up to 6 days.
Talk to us
So: how are you feeling about mobile marketing, advertising, measurement, and attribution since Apple announced SKAdNetwork 4 last week? If you’re looking for some insight, guidance, or advice, we’re happy to help.
Book some time, and you’ll have an expert on call.

Stay up to date on the latest happenings in digital marketing

