Migración de nuestro almacén de eventos de Athena a Snowflake
En Singular, contamos con una canalización que ingiere datos sobre vistas de anuncios, clics en anuncios y descargas de aplicaciones de millones de dispositivos móviles en todo el mundo. Esta enorme masa de datos se agrega de forma horaria y diaria. La enriquecemos con varios métricos de marketing y la ofrecemos a nuestros clientes para que analicen el rendimiento de sus campañas’ y vean su ROI.
El resultado es que recibimos decenas de miles de eventos por segundo y manejamos docenas de terabytes de datos cada día, administrando un conjunto de datos de varios petabytes.
Migrar este vasto y complejo almacén de datos de Athena a Snowflake fue un proceso complejo. En esta publicación, explicaremos por qué decidimos dar este difícil paso, cómo lo logramos y algunas lecciones que aprendimos en el proceso.
Copo de Nieve contra Atenea
Empezamos a usar Athena en 2018 como nuestro almacén de eventos a nivel de usuario. Parecía una solución excelente, ya que separa la computación del almacenamiento, se integra fácilmente con S3 y requiere poco esfuerzo. Fue casi mágico.
Transmitimos eventos de usuarios mediante flujos Kinesis y subimos los datos a S3, particionados por cliente y día. Los archivos se guardaron en S3 usando Athena’s mejores prácticas tanto como fuera posible.
Pero después de un año de producción, comenzaron a surgir problemas, lo que nos llevó a explorar otras soluciones.
Falta de recursos informáticos bajo demanda
El primer problema doloroso fue la necesidad de escalar así como alto poder de cómputo bajo demanda. Athena es un servicio multi‑inquilino, y don’t tienes control sobre la potencia de cómputo que recibe una consulta. Dado que nuestra canalización de producción ejecuta unas 4,000 consultas por hora y consultas pesadas una vez al día por cliente, experimentamos fallos en horas pico por falta de recursos de cómputo.
Mala gestión de recursos
No se pueden dividir ni controlar los recursos informáticos según su uso; por ejemplo, cuando algunos conjuntos de datos deben consultarse más rápido que otros (consulta por hora frente a una consulta diaria extensa). Queríamos ofrecer garantías de rendimiento a nuestros clientes, pero no teníamos control sobre los recursos informáticos.
Falta de agrupamiento listo para usar
Tuvimos que almacenar en búfer los datos a nivel de cliente durante un tiempo (o por tamaño) antes de subirlos a S3. El almacenamiento en búfer no es recomendable para una canalización de streaming y no funcionó bien cuando teníamos un alto rendimiento de datos. El almacenamiento en búfer también afectó la cadencia de actualización de datos en nuestros informes agregados.
Eliminación y actualización tediosa de registros específicos
Estamos obligados a facilitar la eliminación de registros específicos cuando los usuarios finales lo soliciten, para cumplir con la legislación de privacidad de la UE (RGPD). En Athena, eliminar registros específicos de los archivos es un proceso largo y complejo.
¿Por qué Snowflake?
Nuestra decisión de migrar se basó en el hecho de que Snowflake admite estas características críticas por diseño:
- Puedes controlar la potencia de cómputo de la consulta planificando el uso de tu warehouse’s correctamente. Puedes dividir distintas consultas entre diferentes almacenes con distintas instancias, otorgando más recursos donde los necesites.
- Puedes agrupar datos en las micro‑particiones de Snowflake’s definiendo una clave de clúster y ordenando los datos según ella al ingerirlos. También puedes usar auto-clustering para optimizar las micro‑particiones según la clave de clúster. Al agrupar tus datos de forma inteligente según el uso de consultas, puedes optimizar significativamente tus consultas.
- Las eliminaciones son simples en Snowflake, principalmente si están basadas en la clave de clúster. Actualizar registros específicos sigue siendo costoso pero mucho más eficiente que en Athena, ya que puedes separar la potencia de cómputo y escalarla según sea necesario.
Paso previo a la migración: prueba de concepto
Cuando planificamos una prueba de concepto (POC) con Snowflake, queríamos probar todos los tipos de uso que necesitaría nuestro sistema. Dividimos la POC en tres categorías principales: lecturas, escrituras y borrados.
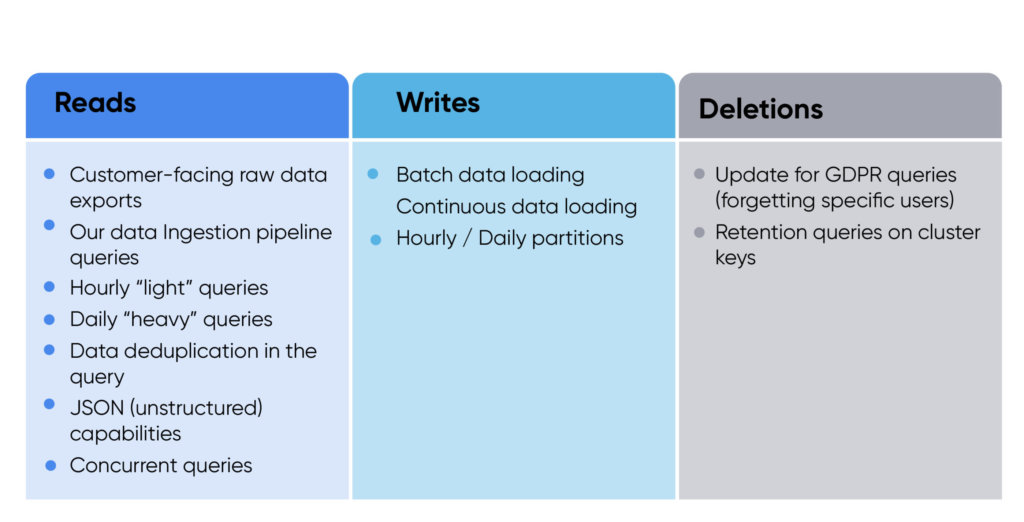
Los requisitos de configuración incluyeron un día de datos de todos los clientes (alrededor de 100 TB); una tabla multiinquilino; e indexación (sin claves de clúster, una clave de clúster y dos claves de clúster).
Teníamos cuatro criterios de éxito:
- Carga de datos a tiempo: Necesitábamos una prueba de concepto de nuestro flujo de ingesta de datos para demostrar que sería rápido y económico.
- Compatibilidad con consultas existentes: Necesitábamos demostrar que podemos ejecutar nuestras consultas actuales en Snowflake.
- Consulta de reunión SLA: Probamos la duración de la consulta y nos aseguramos de que la única forma de mejorarla fuera mediante la migración a Snowflake.
- Requisitos de costo: Queríamos asegurarnos de que ejecutar nuestra carga de producción en Snowflake sea más barato que Athena (esto isn’t la métrica principal del proyecto, pero era importante no aumentar nuestros costos).
Nuestra prueba de concepto de Snowflake fue un éxito total. Además, el equipo de Snowflake fue muy atento y servicial.
Construyendo un pipeline de ingestión robusto
Requisitos
Sabíamos que teníamos que construir un mecanismo de ingestión de Snowflake que cubriera todas las siguientes necesidades:
- Robusto y duradero. El volumen de datos que ingerimos en Snowflake puede aumentar drásticamente en poco tiempo, por lo que nuestro flujo de ingesta debe escalar en consecuencia. Un aumento drástico en el tráfico de uno de nuestros clientes puede ocurrir de forma repentina y puede deberse tanto a eventos planificados como imprevistos. Por ejemplo, una noticia importante puede provocar un aumento repentino de la actividad en redes sociales. Este tipo de sobrecarga repentina de tráfico ya ha ocurrido en el pasado. Por lo tanto, debemos planificar y desarrollar nuestro flujo de ingesta anticipando una duplicación repentina de nuestro volumen total de datos. Necesitamos escalar fácilmente.
- Rápido. El proceso de carga debe cumplir SLAs específicos. Los clientes requieren datos de usuario con apenas unos minutos’ retraso. Garantizamos que Snowflake no retrase la disponibilidad más allá de ese límite.
- Alta disponibilidad. No podemos permitirnos tiempos de inactividad. Los clientes empiezan a notar cuando los nuevos datos se retrasan más de una hora.
- Optimizado para nuestro uso de consultas más frecuente. Consultamos Snowflake más de 4,000 veces por hora para mantener al día nuestros informes agregados. Para garantizar planes de consulta optimizados, debemos asegurarnos de que el orden y la agrupación de datos estén lo mejor preparados posible para ese escenario.
- Cumple con todos los requisitos de privacidad, como la retención de datos y la segregación en reposo. Algunos socios requieren reglas de retención diferentes para sus datos a nivel de usuario. Otros necesitan segregar completamente sus datos de marketing a nivel de usuario en reposo. Tuvimos que soportar estas funciones relacionadas con la privacidad. En Athena, lo gestionamos creando archivos diferentes en S3 (lo que redujo el tamaño de los archivos, afectando negativamente el rendimiento de Athena’s). En Snowflake, podríamos usar otras tablas para segregar y definir reglas de retención distintas para cada socio si fuera necesario.
Decidimos construir nuestro pipeline de ingestión de Snowflake lo más eficiente y autocurativo posible.
Diseño
Aquí vemos nuestro diseño más de cerca:
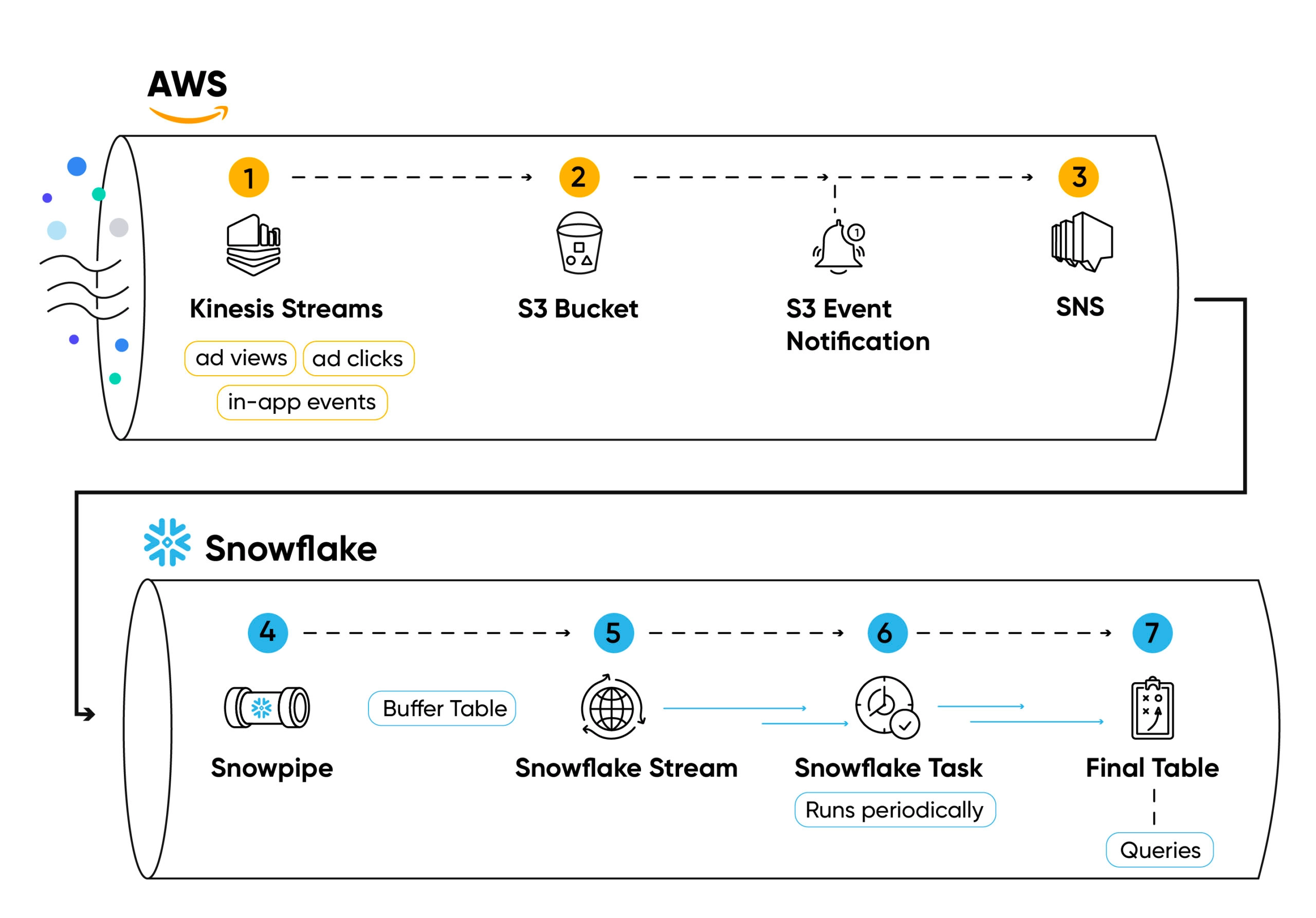
Transmitimos eventos a nivel de usuario en transmisiones de Kinesis desde la pila de Singular(1).
Los eventos (como clics en anuncios, visualizaciones de anuncios, instalaciones de aplicaciones o eventos dentro de la aplicación) se leen desde la transmisión por lotes, se guardan en un archivo .csv (comprimido con zstd) y se cargan en archivos S3 mediante trabajadores de Python (2) administrados por Kubernetes.
Cada creación de archivo crea una notificación en un tema SNS (3), suscrito por Snowpipe (4).
Snowpipe luego inserta el contenido del archivo’s en una tabla de búfer (5) cada vez que se agrega un archivo al bucket, usando el COPY INTO comando.
Los datos guardados en las tablas de búfer no están agrupados ni ordenados, por lo que utilizarlos para consultas agregadas no será eficiente.
Para garantizar que los datos estén organizados y optimizados para la consulta, definimos un flujo (6) sobre la tabla de búfer.
Luego usamos una tarea periódica Snowflake (7) para consultar la secuencia, ordenar los datos e insertarlos en una tabla final (8).
Servicios de copo de nieve
Estos son algunos de los principales servicios de Snowflake que utilizamos:
- Snowpipe: Un servicio de colas gestionado por Snowflake que copia datos a tablas de Snowflake desde fuentes externas, como S3. Un tema SNS puede activar Snowpipe, por lo que cada archivo que guardes en un bucket S3 será copiado a una tabla en Snowflake. Snowpipe’s costos de computación son provistos por Snowflake y no’ usan un almacén definido por el usuario.
- Flujos: Servicio Snowflake que defines en una tabla de tu base de datos. Cada vez que lees del flujo, está leyendo los datos en la tabla desde la última lectura, así puedes actuar con los datos modificados. Es un servicio de streaming (como Kafka/Kinesis) pero implementado en una tabla Snowflake.
- Tareas: Las tareas periódicas de Snowflake son una herramienta excelente para consumir los datos de los streams en otra tabla si es necesario. We’re utilizando tareas de Snowflake como mecanismo de lotes para optimizar la profundidad de micro-partition depth.
Monitoreo, autocuración y manejo de la retención
Para asegurarnos de que nuestro pipeline de Snowflake pueda soportar picos repentinos de datos, utilizamos algunas características interesantes de Snowflake además de desarrollar algunas herramientas internas.
- Almacenes optimizados para ingestión: Dividimos nuestras “heavy-duty” y “lightweight” fuentes de ingestión en diferentes almacenes, según el uso.
- Escalamiento automático horizontal: todos nuestros almacenes son multiclúster y pueden escalar horizontalmente cuando es necesario.
- Monitor de fallas de tareas: El mecanismo de tareas de Snowflake’s gestiona fácilmente fallos esporádicos. Cuando una tarea falla, simplemente se retira del mismo punto de control donde falló. Nuestro problema era que cada vez que se ejecuta una tarea, extrae todos los datos del stream. Si el stream contiene demasiadas filas, la tarea puede agotarse (o simplemente tardar mucho). Los retrasos de ingestión por ráfagas de datos serían muy costosos de gestionar. Lo resolvimos construyendo un monitor interno que lee el historial de Snowflake’s historial de tareas y verifica si una tarea está tardando demasiado. Si es así, el monitor la elimina, escala el almacén y la vuelve a ejecutar. Luego, reduce el almacén a su tamaño original. Este monitor—una función que no pudo ser implementada rápidamente con los servicios existentes—resultó ser un salvavidas.
- Retención de datos: Manejamos la retención de datos de manera eficiente usando tareas periódicas cada día y eliminamos datos más antiguos que x días (cambios por fuente de marketing/cliente). Snowflake’s DELETE los comandos son eficientes y no bloqueantes, especialmente al ejecutarlos en la clave de clúster (por ejemplo, eliminando días completos de datos).
Cada hora, las tareas de Python Celery en nuestra canalización de ingestión consultan a Snowflake sobre los datos ingeridos.
Escala de manejo
Las diferentes formas en que usamos Snowflake en Singular se suman a un patrón de consulta único:
- Singular’s pipeline de ingestión de datos agregados: Ejecutando consultas de agregación horaria en los datos de cada cliente’s.
- Customer-facing ETL processes: Singular’s ETL solution queries raw data every hour and pushes it to customers’ databases.
- Exportaciones manuales orientadas al cliente: exportaciones a pedido de datos sin procesar.
- BI interno de Singular.
- Consultas GDPR “olvidar usuarios”: Actualizaciones de filas específicas, ejecutadas en lotes cada día, manejan Solicitudes de olvido GDPR.
Ejecutamos miles de consultas cada hora y necesitamos que se completen rápidamente en una gran variedad de volúmenes de datos. Además, necesitamos que Snowflake actualice filas específicas con un impacto mínimo en la agrupación de datos. Nuestros procesos de consulta se ejecutan periódicamente de forma distribuida en los trabajadores de Python Celery.
Cuando empezamos a migrar a Snowflake, asumimos que necesitaríamos gestionar el tamaño del almacén virtual según el uso y la escala. Con nuestro patrón de consultas distribuidas, es natural que cada trabajador consulte directamente a Snowflake, lo que abre una nueva sesión con cada consulta. Esto significó que pronto nos topamos con los límites flexibles de Snowflake para las sesiones concurrentes (a diferencia de las consultas concurrentes, que Snowflake gestiona prácticamente sin limitaciones).
La buena noticia es que no necesitas limitarte por sesiones en Snowflake: puedes ejecutar consultas asíncronas, limitadas únicamente por el tamaño de la cola del almacén. Decidimos aprovechar esto y crear un grupo de sesiones en vivo desde el que se pueden ejecutar tareas. Por diseño, lo planeamos para que fuera completamente asíncrono y sin estado, por lo que solo estaría limitado por el uso del almacén. Construir un servidor ASGI de Python sin estado que administre nuestras conexiones fue una solución bastante sencilla y elegante.
Implementamos nuestro servicio de pool de conexiones de Python Snowflake mediante la integración de SqlAlchemy Snowflake, Uvicorn y FastAPI. Planeamos publicarlo en código abierto y compartirlo con la comunidad próximamente, para que quienes creen aplicaciones en Snowflake puedan ahorrar tiempo y esfuerzo al crear sus propios pools de sesiones.
Actualmente, con nuestro pool de conexiones de Snowflake, ejecutamos más de 4000 consultas por hora en varios almacenes virtuales de Snowflake. Los almacenes virtuales se escalan horizontalmente automáticamente si es necesario. Nuestras actualizaciones del RGPD se ejecutan en un gran almacén dedicado, por lo que las consultas de actualización complejas se ejecutan eficientemente. El almacén virtual se suspende automáticamente cuando no se procesan solicitudes.
Validación de datos
Los clientes Singular dependen en gran medida de nuestros datos para sus operaciones comerciales. No podíamos permitirnos ninguna discrepancia de datos al migrar de Athena a Snowflake.
Mientras ejecutábamos ambas canalizaciones de ingesta en paralelo, creamos un monitor de ejecución continua que comparaba las consultas en Athena y Snowflake para cada archivo subido a S3. De esta forma, supimos de inmediato si había problemas de ingesta de datos. Además, lanzamos una consulta en Snowflake y comparamos los resultados de cada consulta de Athena que ejecutamos en producción.
La creación de este monitor nos ayudó a validar que la migración de datos se estaba realizando correctamente y sin inconsistencias.
Otras lecciones aprendidas
Cuando se completó la migración, examinamos más de cerca nuestro uso y configuración de crédito y encontramos algunas formas sencillas de optimizarlo:
- Planifica el uso del almacén según la necesidad. Por ejemplo, nuestras consultas “pesadas” se ejecutan una vez al día (todas simultáneamente) en un almacén de gran escala con auto‑suspensión activada, mientras que nuestras consultas “ligeras” horarias se ejecutan en un almacén más pequeño con mayor escalado horizontal de clúster. Esto garantiza que el uso diario esté optimizado en costos (consultas pesadas rápidas y suspendidas la mayor parte del tiempo). Las consultas horarias tienen la elasticidad necesaria para su escala de concurrencia.
- Trabaja con Snowflake para comprender los costos de los servicios en la nube. Descubrimos que nuestro patrón de consultas pesadas sobrecargaba la compilación al calcular NDV. Snowflake ajustó la configuración y nos ahorró tiempo de compilación innecesario para nuestro caso (consultas a nuevos clústeres en tabla muy actualizada).
- Optimización de consultas: Optimizamos la duración de muchas de nuestras consultas con la herramienta de creación de perfiles Snowflake. Nos ayudó con consultas complejas, como las actualizaciones del RGPD.
¿Que sigue?
- Compartir datos: Hay oportunidades fantásticas para compartir datos de forma segura con Snowflake. We’re trabajando con el equipo de Snowflake para aprovechar la idea de un sala limpia distribuida para compartir datos de forma segura.
- Ofuscación de IP: Implementamos retención de 30 días en campos de IP para mantener nuestro certificado de sello de seguridad. Para ello, creamos un flujo ágil y eficiente, usando políticas de enmascaramiento de Snowflake y variables de sesión para guardar los campos de IP cifrados y descifrarlos bajo demanda. Planeamos publicar otro blog que profundice en nuestra solución.
- Código abierto del pool de conexiones: Planeamos publicar como código abierto nuestro servicio de pool de conexiones Python para Snowflake en los próximos meses. Si crees que te será útil—por ejemplo, si planeas ejecutar gran cantidad de consultas cada hora—contáctanos y avísanos!
Este blog se publicó originalmente en Snowflake’s blog.

Manténgase al día de los últimos acontecimientos en marketing digital

