Migrando nosso armazém de eventos do Athena para o Snowflake
No Singular , temos um pipeline que ingere dados sobre visualizações de anúncios, cliques de anúncios e instalações de aplicativos de milhões de mobile em todo o mundo. Essa enorme massa de dados é agregada a cada hora e diariamente. Enriquecemos com várias métricas de marketing e oferecemos aos nossos clientes analisar o desempenho de suas campanhas e ver seu ROI.
O resultado é que recebemos dezenas de milhares de eventos por segundo e lidamos com dezenas de terabytes de dados todos os dias, gerenciando um conjunto de dados de vários petabytes.
Migrar esse vasto e complexo data warehouse de Athena para Snowflake foi um processo complicado. Este post discutirá por que decidimos dar esse passo difícil, como fizemos isso e algumas lições que aprendemos ao longo do caminho.
Snowflake vs. Athena
Começamos a usar a Athena em 2018 como nosso armazém de eventos no nível do usuário. Parecia uma excelente solução, pois separa a computação do armazenamento, se integra facilmente ao S3 e requer baixo esforço. Parecia um pouco mágico.
Transmitimos eventos de usuário por meio de fluxos de Kinesis e enviamos os dados para S3, particionados pelo cliente e dia. Os arquivos foram salvos no S3 usando as melhores práticas de Athena o máximo possível.
Mas depois de um ano de produção, os problemas começaram a surgir, levando -nos a explorar outras soluções.
Falta de recursos de computação sob demanda
A primeira questão dolorosa foi a necessidade de escala e alta potência de computação sob demanda. Athena é um serviço de vários inquilinos e você não tem controle sobre o poder de computação que uma consulta receberá. Como nosso pipeline de produção executa cerca de 4.000 consultas por hora e consultas pesadas uma vez por dia por cliente, experimentamos falhas no horário de pico devido à falta de recursos de computação.
Má gestão de recursos
Você não pode dividir e controlar os recursos de computação de acordo com o uso; Por exemplo, quando alguns conjuntos de dados precisam ser consultados mais rapidamente do que outros (consulta por hora vs. uma grande consulta diária). Queríamos dar algumas garantias de desempenho aos nossos clientes, mas não tínhamos controle sobre os recursos de computação.
Falta de agrupamento fora da caixa
Tivemos que amortecer os dados no nível do cliente por algum tempo (ou por tamanho) antes de enviá-los para S3. O buffer não é uma boa prática para um pipeline de streaming e não teve um bom desempenho quando tivemos alta taxa de transferência de dados. O buffer também afetou nossa cadência de atualização de dados em nossos relatórios agregados.
Excluindo e atualização tediosa de registros específicos
Somos obrigados a apoiar as deleções de registros específicos quando os usuários finais exigem, para cumprir as leis de privacidade da UE (GDPR). Em Athena, excluir registros específicos de arquivos é um processo longo e complicado.
Por que floco de neve?
Nossa decisão de migrar foi baseada no fato de que o Snowflake suporta esses recursos críticos pelo design:
- Você pode controlar o poder de computação de consulta planejando o uso do seu armazém corretamente. Você pode dividir consultas diferentes em diferentes armazéns com diferentes instâncias, concedendo mais recursos onde você precisa.
- Você pode agrupar dados nas micropartições do Snowflake, definindo uma chave de cluster e classificando os dados de acordo com ele ao ingeri-los. Você também pode usar o cluster automático para otimizar as micropartições de acordo com a chave do cluster. Ao agrupar seus dados com sabedoria de acordo com o uso de consultas, você pode otimizar significativamente suas consultas.
- As exclusões são simples em floco de neve, principalmente se elas são baseadas na chave do cluster. A atualização de registros específicos ainda é caro, mas muito mais eficiente do que em Athena, pois você pode separar o poder de computação e escalá -lo conforme necessário.
Etapa de pré-migração: prova de conceito
Quando planejamos um POC com floco de neve, queríamos testar todos os tipos de uso que nosso sistema precisaria. Dividimos o POC em três categorias principais: leituras, gravações e exclusões.
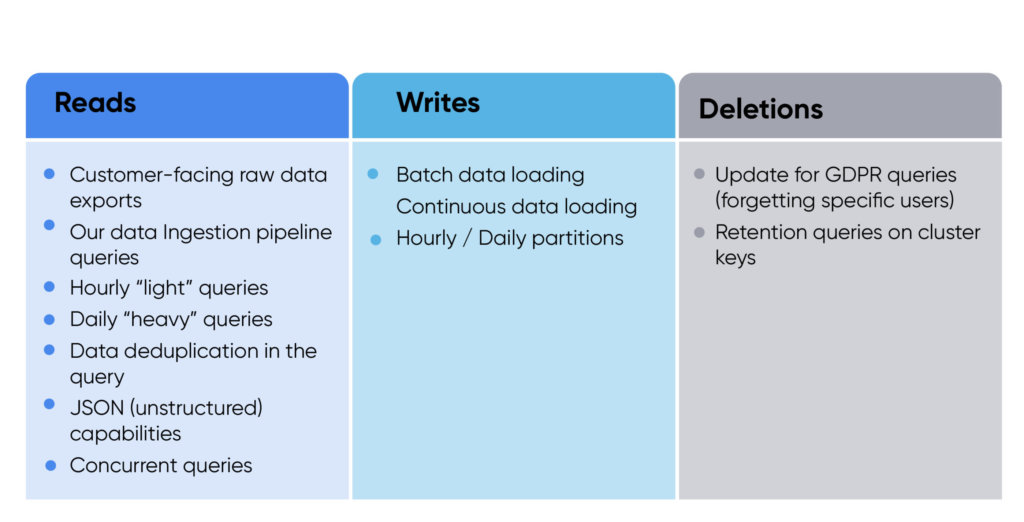
Os requisitos de configuração incluíram um dia de dados de todos os clientes (cerca de 100 TB); tabela multi-inquilino; e indexação (sem chaves de cluster, uma chave de cluster e duas teclas de cluster).
Tivemos quatro critérios de sucesso:
- Carregando os dados no tempo: precisávamos de nosso POC de ingestão de dados para provar que ele será rápido e barato.
- Suporte para consultas existentes: precisávamos provar que podemos executar nossas consultas atuais no Snowflake.
- Conhecendo o SLA: Testamos a duração da consulta, garantindo que a única maneira de melhorar foi através da migração para o Snowflake.
- Requisitos de custo: Queríamos garantir que a execução de nossa carga de produção no Snowflake seja mais barata que a Athena (essa não era a principal métrica do projeto, mas era importante não aumentar nossos custos).
Nosso Snowflake POC foi bem -sucedido em todos os aspectos. Além disso, a equipe do Snowflake foi acolhedora e útil.
Construindo um oleoduto de ingestão robusto
Requisitos
Sabíamos que tínhamos que construir um mecanismo de ingestão de floco de neve que preencheu todas as seguintes necessidades:
- Robusto e durável. O volume de dados que ingerimos no floco de neve pode aumentar drasticamente em um curto período, portanto, nosso pipeline de ingestão deve escalar de acordo. Um aumento drástico no tráfego para um de nossos clientes pode acontecer de repente e pode ocorrer a partir de eventos planejados e não planejados. Uma notícia significativa pode causar um aumento na atividade de mídia social, por exemplo. Esse tipo de sobrecarga abrupta de tráfego aconteceu no passado. Portanto, devemos planejar e construir nosso pipeline de ingestão em antecipação a uma duplicação repentina do nosso volume geral de dados. Precisamos ser capazes de escalar facilmente.
- Rápido. O processo de carga deve atender a SLAs específicos. Nossos clientes precisam extrair dados no nível do usuário com apenas alguns minutos de atraso. Temos que garantir que o Snowflake não atrase a disponibilidade de dados além desse limite.
- Altamente disponível. Não podemos pagar o tempo de inatividade. Os clientes começam a observar quando novos dados são adiados por mais de uma hora.
- Otimizado para o nosso uso de consulta mais comum. Estamos consultando floco de neve mais de 4.000 vezes por hora para manter nossos relatórios agregados atualizados. Para garantir que tenhamos otimizado de planos de consulta, precisamos garantir que nossos dados e cluster de dados estejam o mais preparados possível para esse cenário de uso.
- Compatível com todos os requisitos de privacidade, como retenção de dados e segregação de dados em repouso. Alguns parceiros exigem regras de retenção diferentes em seus dados no nível do usuário. Alguns parceiros precisam segregar completamente seus dados no nível do usuário de marketing. Tivemos que apoiar esses recursos relacionados à privacidade. Em Athena, lidamos com isso criando diferentes arquivos no S3 (que diminuíram os tamanhos dos arquivos, impactando negativamente o desempenho de Athena). No Snowflake, poderíamos usar outras tabelas para segregar e definir diferentes regras de retenção para cada parceiro, se necessário.
Decidimos construir nosso pipeline de ingestão de floco de neve o mais enxuto e auto-recuperação possível.
Projeto
Aqui está uma olhada mais de perto em nosso design:
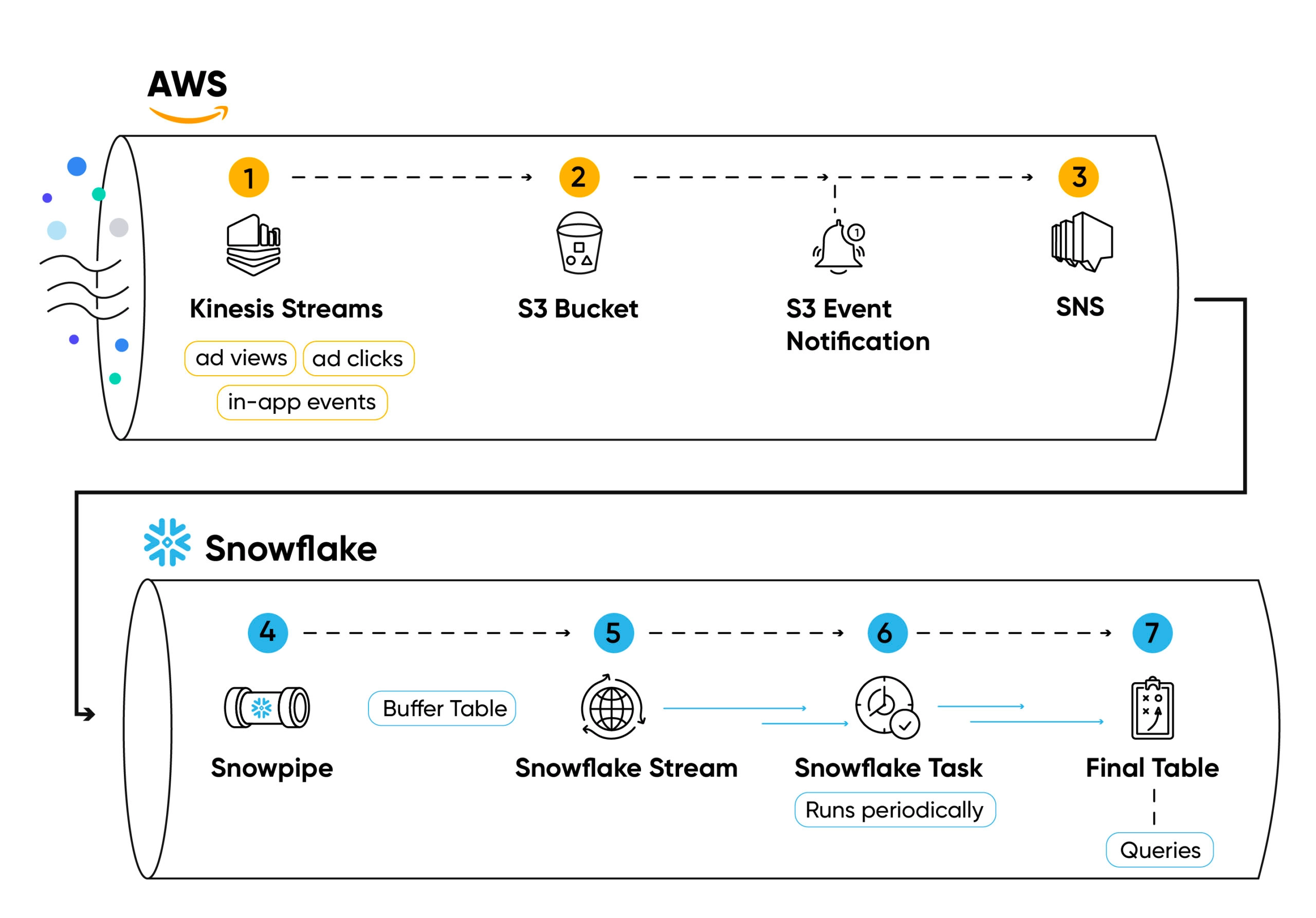
Nós transmitimos eventos no nível do usuário nos fluxos de Kinesis da pilha do Singular(1).
Os eventos (como cliques de anúncios, visualizações de anúncios, instalações de aplicativos ou eventos no aplicativo) são lidos do fluxo de maneira semelhante ao lote, salvos em um arquivo .csv (compactado com ZSTD) e enviados para arquivos S3 usando trabalhadores de Python (2) gerenciados pela Kubernetes.
Cada criação de arquivos cria uma notificação em um tópico SNS (3), subscrito por Snowpipe (4).
O Snowpipe insere o conteúdo do arquivo em uma tabela de buffer (5) em cada arquivo adicionado ao balde, usando a cópia no comando.
Os dados salvos nas tabelas de buffer não são agrupados ou ordenados; portanto, utilizá -los para consultas agregadas não será eficiente.
Para garantir que os dados sejam organizados e otimizados para consulta, definimos um fluxo (6) sobre a tabela de buffer.
Em seguida, usamos uma tarefa periódica de floco de neve (7) para consultar o fluxo, classificar os dados e inseri -los em uma tabela final (8).
Serviços de floco de neve
Estes são alguns dos principais serviços de floco de neve que usamos:
- Snowpipe : Um serviço de filas gerenciado por floco de neve que copia dados em tabelas de floco de neve de fontes externas, como o S3. Um tópico do SNS pode desencadear o Snowpipe, para que todos os arquivos que você salvam em um balde S3 serão copiados em uma mesa em Snowflake. Os custos de computação do Snowpipe são fornecidos pelo Snowflake e não usam um armazém definido pelo usuário.
- Fluxos : um serviço de floco de neve que você pode definir em uma mesa no seu banco de dados. Toda vez que você lê do fluxo, ele está lendo os dados na tabela desde a última leitura, para que você possa agir usando os dados alterados. É um serviço de streaming (como Kafka/Kinesis), mas implementado em uma mesa de floco de neve.
- Tarefas : as tarefas periódicas de floco de neve são uma excelente ferramenta para consumir os dados dos fluxos em outra tabela, se necessário. Estamos utilizando tarefas de floco de neve como um mecanismo de lote para otimizar a profundidade da micropartição.
Monitoramento, auto -cura e manuseio de retenção
Para garantir que nosso pipeline de floco de neve possa suportar rajadas repentinas de dados, usamos alguns recursos legais de floco de neve, além de criar algumas ferramentas internas.
- Armazéns otimizados para ingestão: dividimos nossas fontes de ingestão de “serviço pesado” e “leve” para diferentes armazéns, de acordo com o uso.
- Scalação automática horizontal: Todos os nossos armazéns são multi-cluster e aumentam horizontalmente quando necessário.
- Monitor de falha da tarefa: o mecanismo de tarefas do Snowflake lida com falhas esporádicas facilmente. Quando as tarefas falham, elas são aposentadas do mesmo ponto de verificação em que falharam. O problema para nós era que toda vez que uma tarefa é executada, ele puxa todos os dados do fluxo. Se o fluxo contiver muitas linhas de dados, a tarefa poderá se desligar (ou apenas levar muito tempo). A ingestão de defasagens devido a rajadas de dados seria muito caro gerenciar. Abordamos o problema construindo um monitor interno o histórico de tarefas do Snowflake e verifica se uma tarefa está demorando muito. Se for, o monitor o mata, dimensiona o armazém e o executa novamente. Mais tarde, ele escala o armazém de volta ao seu tamanho original. Esse monitor - uma função que não poderia ser cumprida rapidamente usando os serviços existentes - foi um salva -vidas.
- Retenção de dados: Lidamos com a retenção de dados com eficiência usando tarefas periódicas todos os dias e excluímos dados mais antigos que X dias (alterações pela fonte/cliente de marketing). de exclusão do Snowflake são eficientes e não bloqueando, especialmente ao executá-los na chave do cluster (por exemplo, excluir dias inteiros de dados).
A cada hora, as tarefas do aipo do Python em nossa consulta de pipeline de ingestão de floco de neve sobre os dados ingeridos.
Escala de manuseio
As diferentes maneiras pelas quais usamos floco de neve no Singular somam um padrão de consulta exclusivo:
- Pipeline de ingestão de dados agregados do Singular executando consultas de agregação por hora nos dados de cada cliente.
- Processos ETL voltados para o cliente: a solução ETL do Singular
- Exportações manuais voltadas para o cliente: exportações sob demanda de dados brutos.
- BI interno do Singular.
- GDPR “Esqueça os usuários” consultas: atualizações específicas da linha, executando em lotes todos os dias, lide com solicitações de esquecimento do GDPR .
Executamos milhares de consultas a cada hora e precisamos que elas sejam concluídas rapidamente sobre uma grande variedade de volumes de dados. Além disso, precisamos de floco de neve para atualizar linhas específicas com efeito mínimo no cluster de dados. Nossos processos de consulta são executados periodicamente de maneira distribuída nos trabalhadores do aipo de Python.
Quando começamos a migrar para o Snowflake, assumimos que precisaríamos gerenciar o dimensionamento virtual do armazém de acordo com o uso e a escala. Com nosso padrão de consulta distribuído, é natural que cada trabalhador consulte diretamente o floco de neve, o que abre uma nova sessão a cada consulta. Isso significa que em breve encontramos os limites suaves do Snowflake em sessões simultâneas (diferentes das consultas simultâneas, que o floco de neve lida praticamente sem limitações).
A boa notícia é que você não precisa ser limitado por sessões em floco de neve - você pode executar consultas assíncronas, ligadas apenas pelo tamanho da fila do armazém. Optamos por tirar proveito disso e criar um pool de sessões ao vivo da qual as tarefas possam ser executadas. Por design, planejamos ser completamente assíncrono e sem estado, por isso seria limitado apenas pelo uso do armazém. Construir um servidor Python ASGI apátrido que gerencia nossas conexões foi uma solução bastante simples e elegante para nós.
Implementamos nosso serviço Python Snowflake Connection Pool, usando a integração do Sqlalchemy Snowflake , Uvicorn e FASTAPI . E planejamos que a fonte aberta e compartilhamos com a comunidade em breve, para que outras pessoas que construam aplicativos no Snowflake possam economizar tempo e esforço ao criar seus próprios pools de sessão.
Atualmente, usando nosso pool de conexões de neve, estamos executando mais de 4.000 consultas por hora em vários armazéns virtuais de floco de neve. Os armazéns virtuais aumentam automaticamente horizontalmente, se necessário. Nossas atualizações do GDPR estão em execução em um grande armazém dedicado, portanto, as consultas de atualização complexas estão sendo executadas com eficiência. O armazém virtual é suspenso automaticamente quando nenhuma solicitação é processada.
Validação de dados
Os clientes Singular dependem muito de nossos dados para suas operações comerciais. Não podíamos pagar discrepâncias de dados ao migrar de Athena para Snowflake.
Ao executar os dois pipelines de ingestão em paralelo, construímos um monitor em execução continuamente que comparou a consulta em Athena e Snowflake para cada arquivo enviado para S3. Dessa forma, soubemos imediatamente se havia problemas de ingestão de dados. Além disso, lançamos uma consulta de floco de neve e comparamos os resultados para todas as perguntas de Athena que executamos em produção.
A construção desse monitor nos ajudou a validar que a migração de dados estava sendo feita corretamente e sem inconsistências.
Outras lições aprendidas
Quando a migração foi concluída, examinamos nosso uso de crédito e configuramos mais de perto e encontramos algumas maneiras fáceis de otimizar:
- Planeje o uso do armazém de acordo com o uso. Por exemplo, nossas consultas "pesadas" são executadas uma vez por dia (todas lançadas simultaneamente) em um armazém em larga escala com suspensão automática, enquanto nossas consultas horárias "leves" são executadas em um armazém menor com escala de cluster horizontal mais alta. Isso garante que nosso uso diário seja otimizado para o custo (executando consultas pesadas rapidamente e suspensa na maioria das vezes). Nossas perguntas por hora têm a elasticidade necessária para sua escala de simultaneidade.
- Trabalhe com o Snowflake para entender os custos dos serviços em nuvem. Descobrimos que nosso padrão de consulta pesado criou uma carga pesada no tempo de compilação da consulta ao calcular o NDV na mesa. O Snowflake nos ajudou a alterar a configuração do recurso. Ele nos salvou muito tempo de compilação de consulta que nossos tipos de consulta não precisavam de nosso caso de uso específico (consultando novos clusters apenas em uma tabela fortemente atualizada).
- Otimização de consultas: otimizamos a duração de muitas de nossas consultas usando a ferramenta de perfil de floco de neve . Isso nos ajudou com consultas complexas, como atualizações do GDPR.
O que vem a seguir?
- Compartilhamento de dados: existem oportunidades fantásticas em relação ao compartilhamento de dados seguro com o Snowflake. Estamos trabalhando com a equipe de floco de neve para alavancar a idéia de uma sala limpa distribuída para compartilhamento de dados seguro.
- OBFUSCAÇÃO IP: Tivemos que implementar a retenção de 30 dias em campos relacionados à IP para manter nosso certificado de selo de segurança. Para fazer isso, implementamos um fluxo legal e eficiente, utilizando políticas de mascaramento de flocos de neve e variáveis de sessão para salvar todos os nossos campos relacionados a IP criptografados e descriptografá-los apenas sob demanda. Estamos planejando publicar outra postagem no blog Deeping em nossa solução.
- Open-sDooming the Connection Pool: Planejamos de código aberto nosso serviço Python Snowflake Connection Pool Service nos próximos meses. Se você acha que isso pode ser útil para você - por exemplo, se você planeja executar um grande número de consultas a cada hora - renda e nos informe!
Este blog foi publicado originalmente no blog de Snowflake .

Mantenha-se atualizado sobre os últimos acontecimentos em marketing digital

