Singular CEO Gadi Eliashiv와 함께 하는 SKAN 4 심층 분석 (질문 답변 포함!)
SKAN 4가 출시되었습니다. 이제 이에 대해 어떻게 하실 건가요?
저는 마케팅 커뮤니티에서 SKAN 4에 대한 다양한 의견을 보았습니다. 대부분은 더 많은 측정값이 있어서 기뻐합니다. 대부분은 더 자세한 정보를 제공해서 기뻐합니다. 대부분은 더 명확해진 점이 있어서 기뻐합니다. 하지만 대부분은 여전히 모든 것을 파악하려고 노력하고 있습니다. 많은 사람이 문서의 작은 세부 사항을 샅샅이 뒤져서 명확하지 않은 질문에 대한 답을 찾고 있습니다. 그리고 일부는 복잡함에 당황하고 있습니다.
그래서 Singular CEO Gadi Eliashiv와 나는 LinkedIn에서 1시간 라이브 지난 주에 SKAN 4를 자세히 살펴보고 마케터들의 질문을 받았습니다:
- 새로운 소식
- 좋은 점은
- 혼란스러운 점은
- 불행한 점은
- 그리고 네, 안 좋은 점은
위의 동영상을 시청하여 모든 내용을 확인하거나(또는 Growth Masterminds 팟캐스트를 구독 하여 오디오 형식으로 확인하세요.)
몇 가지 주요 내용은 다음과 같습니다
먼저, SKAN 4의 긍정적인 측면
새로운 것에 대해 좋아할 점이 많습니다 SKAdNetwork version 4, 첫 번째 포스트에서 자세히 다루었고, 또한 우리의 Singular 제품 업데이트 게시물:
- 더 많은 포스트백 (!!!)
- 첫 번째 포스트백에 더 많은 데이터 (잠재적으로)
- 적어도 일부 데이터 는 캠페인당 숫자가 매우 낮더라도 얻을 수 있습니다
- 훨씬 강력한 새로운 소스 식별자
- 웹에서 앱으로 기능 (하지만 Safari에서만 가능)
- 더 명확해진 익명 사용자 그룹
- 전환 값 잠금을 통한 조기 포스트백
SKAN 4에는 고려해야 할 사항이 많습니다. 전체 내용을 한눈에 볼 수 있도록 도와주는 차트입니다:
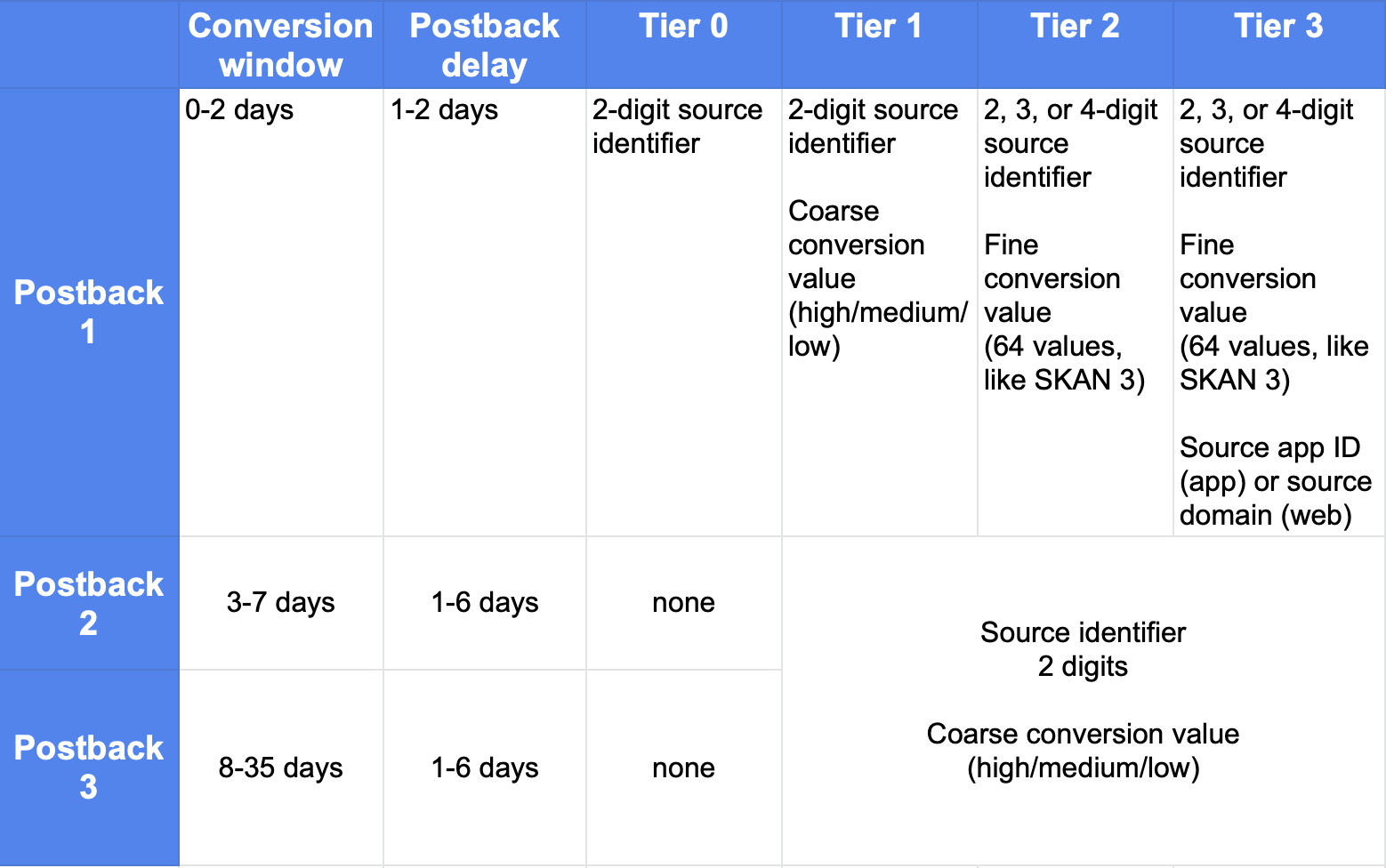
SKAN 4의 흥미로운 과제는 SKAN 3과 동일합니다. 세분성과 실험의 균형을 맞추는 것입니다.
변환 및 설치당 얻는 데이터의 양, 즉 세분성을 극대화하려면 집중이 필요합니다. 제한된 수의 파트너 및 캠페인에 리소스를 집중하여 SKAdNetwork에서 Tier 2 또는 Tier 3 수준의 데이터 반환을 달성하도록 해야 합니다. 그러나 최적의 소스, 타겟팅, 파트너 및 크리에이티브를 찾으려면 이 세 가지 중요한 요소에 대한 실험이 필요합니다.
두 가지 요구 사항 사이의 적절한 균형을 찾는 것이 중요합니다.
여전히 해결해야 할 문제도 있습니다
모바일 마케팅 커뮤니티에서는 여전히 SKAN 4 문서의 특정 문장이나 단락이 실제 조건에서 무엇을 의미하는지에 대해 논의하고 있습니다. 또한 앱 퍼블리셔가 대규모 광고를 게재할 때까지 계층을 정의하는 볼륨 유형을 명확하게 이해하지 못할 것입니다.
SKAN 4의 주요 과제는 다음과 같습니다:
- 시간: 생태계가 이를 지원하기까지는 수개월이 걸릴 것입니다
- 작업: 모바일 광고 기술 가치 사슬의 모든 파트너가 해야 할 일이 있으며, 특히 이제 새로운 현실에 맞춰 캠페인을 최적화해야 하는 광고 네트워크가 있습니다 … 몇 달 만에 몇몇 명이 SKAN 3에서 대충 파악했습니다
- 혼란: 많은 사람들이 여러 버전의 SKAN을 사용하게 되어 SKAN 3 및 SKAN 4에 대한 지원이 필요합니다
- 기타 미스터리: 일부 사항은 오랫동안 알 수 없습니다. 한 가지 예: 정확히 어떻게 crowd anonymity tier가 작동하며, 마케터는 최대 데이터를 얻기 위해 얼마나 많은 볼륨을 유도해야 합니까?

SKAN 4 환경에서 SKAN 3 버전으로 살아간다는 건?
생각보다 흥미로운 얘기죠. 만약 SKAN 4가 제공하는 더 풍부한 데이터에 관심이 없다면, SKAN 4 내에서 SKAN 3 버전을 사용하는 것과 다를 바 없으니까요
다시 말해, 소스 ID의 집계 볼륨에 전혀 관심이 없다면, 기본적으로 SKAN 3에서 제공하던 정보를 얻게 될 거예요
- 1개의 포스트백
- 2자리 소스 식별자
- Tier 0의 크라우드 익명성
문제는 이것이 기존 SKAN 3보다 낮은 데이터 볼륨에서 더 많은 데이터를 제공할 것인가입니다. 애플이 말한 내용을 일부 외삽한 것에 기반하여 모바일 마케팅 커뮤니티에서 애플이 낮은 볼륨에서 더 많은 데이터를 제공하고 소비자 개인 정보 보호를 정당화하는 더 높은 볼륨에서 훨씬 더 많은 데이터를 제공하려고 했다는 가정이 있었습니다.
따라서 — 제가 강조하지만 — SKAN 4에서 SKAN 3에서와 다른 것을 시도하지 않고도 더 많은 데이터를 얻을 수 있는 경우가 있을 수 있습니다.
많은 광고주가 이와 같은 전략을 채택할 가능성이 낮고, 애플의 새로운 기여 분석 프레임워크가 실제 환경에서 성장함에 따라 데이터에 필요한 볼륨에 대해 더 많이 알게 될 것입니다. 일반적으로 더 많은 데이터가 더 좋습니다.
하지만 일부는 유혹을 받을 수도 있습니다.…
한 가지는 확실합니다. 지금은 더 복잡해졌습니다
Singular 의 목표는 모든 복잡성을 추상화하여 마케터들이 자신의 일을 할 수 있도록 하는 것입니다. 하지만 더 단순해지더라도 이는 말 그대로 불가능한 작업입니다.
더 많은 포스트백을 갖는다는 것은 이제 보고할 앱의 추가 이벤트에 대해 생각해야 함을 의미합니다. 그리고 포스트백 1에 대해 미세하고 거친 값을 모두 얻을 가능성이 있다는 것은 미세하고 거친 값을 하나의 이해 가능하고 실행 가능한 KPI 및 가치 프레임워크로 동기화하기 위한 변환 스키마가 필요함을 의미합니다.
예를 들어 다음과 같습니다:
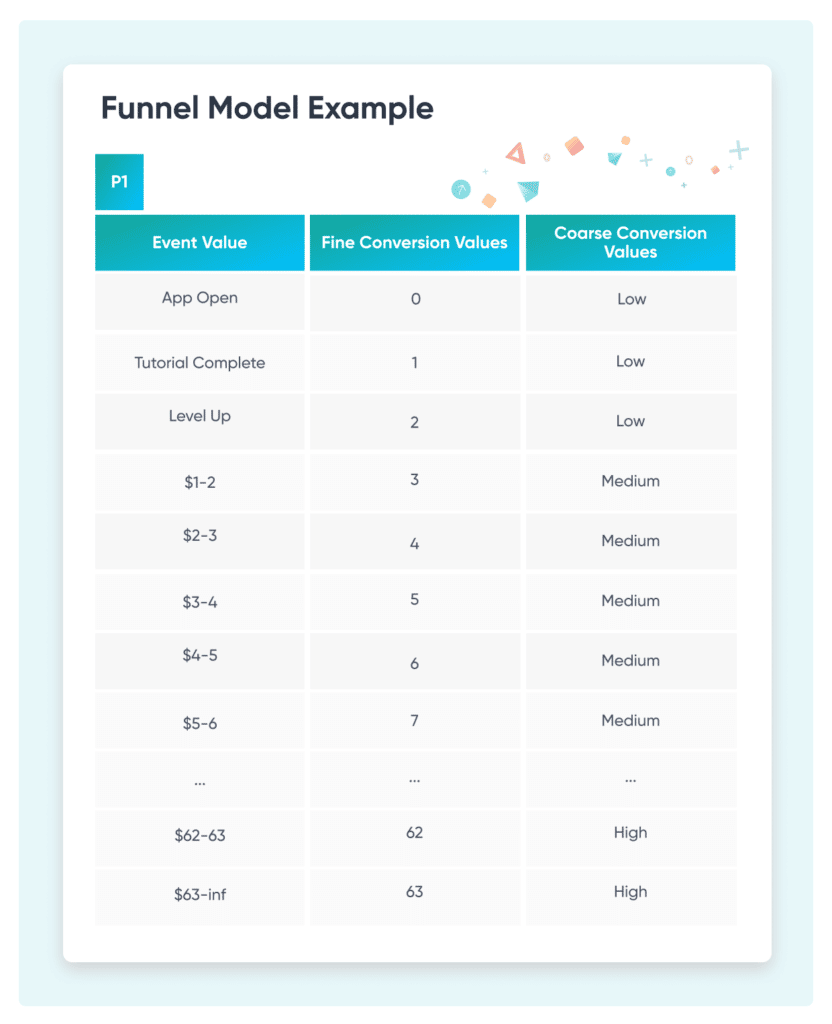
이제 변환 값을 고정할 수 있습니다. 이는 긍정적인 점이며 데이터를 더 빨리 얻을 수 있지만 코호트 기간을 더 길게 만듭니다. 물론, 이는 이미 훨씬 더 긴 무작위 타이머에 의해 연장되고 있으며, 전환 기간 이후에 포스트백을 받는데 최대 6일이 소요될 수 있습니다.
저희에게 이야기해 주세요
애플이 지난 주 SKAdNetwork 4를 발표한 이후 모바일 마케팅, 광고, 측정 및 기여에 대해 어떻게 느끼고 계신가요? 통찰력, 지침 또는 조언이 필요하면 기꺼이 도와드리겠습니다.
시간을 예약하세요, 그리고 전문가와 연결됩니다.

디지털 마케팅 최신 소식을 받아보세요

