Migrando nosso armazém de eventos do Athena para o Snowflake
Na Singular, temos um pipeline que ingere dados sobre visualizações de anúncios, cliques e instalações de apps de milhões de mobile dispositivos em todo o mundo. Essa enorme massa de dados é agregada a cada hora e dia. Enriquecemos com várias métricas de marketing e oferecemos aos clientes para analisar o desempenho das campanhas’ e ver seu ROI.
Em resumo, recebemos dezenas de milhares de eventos por segundo e processamos dezenas de terabytes de dados todos os dias, gerenciando um conjunto de dados de vários petabytes.
Migrar este vasto e complexo data warehouse do Athena para o Snowflake foi um processo complicado. Este post discutirá por que decidimos dar esse passo difícil, como o fizemos e algumas lições que aprendemos ao longo do caminho.
Floco de Neve vs. Atena
Começamos a usar o Athena em 2018 como nosso repositório de eventos em nível de usuário. Parecia uma solução excelente, pois separa o processamento do armazenamento, integra-se facilmente ao S3 e exige pouco esforço. Era quase como mágica.
Transmitimos eventos de usuário via streams Kinesis e enviamos os dados para o S3, particionados por cliente e dia. Os arquivos foram salvos no S3 usando as melhores práticas da Athena tanto quanto possível.
Mas, após um ano de produção, começaram a surgir problemas, o que nos levou a explorar outras soluções.
Falta de recursos computacionais sob demanda
O primeiro problema doloroso foi a necessidade de escala assim como alto poder de computação sob demanda. Athena é um serviço multi‑tenant e você não controla o poder de computação que uma consulta recebe. Como nosso pipeline de produção executa cerca de 4.000 consultas por hora e consultas pesadas uma vez ao dia por cliente, enfrentamos falhas nos horários de pico por falta de recursos computacionais.
Má gestão de recursos
Não é possível dividir e controlar os recursos computacionais de acordo com o uso; por exemplo, quando alguns conjuntos de dados precisam ser consultados mais rapidamente do que outros (consulta horária versus uma grande consulta diária). Queríamos oferecer algumas garantias de desempenho aos nossos clientes, mas não tínhamos controle sobre os recursos computacionais.
Falta de agrupamento pronto para uso
Precisávamos armazenar em buffer os dados de cada cliente por um período (ou por tamanho) antes de enviá-los para o S3. O armazenamento em buffer não é uma boa prática para um pipeline de streaming e apresentou desempenho insatisfatório quando tínhamos alta taxa de transferência de dados. Além disso, o uso de buffer também afetou a frequência de atualização dos nossos relatórios agregados.
Tarefa tediosa de exclusão e atualização de registros específicos
Somos obrigados a dar suporte à exclusão de registros específicos quando os usuários finais o solicitam, para cumprir as leis de privacidade da UE (RGPD). No Athena, excluir registros específicos de arquivos é um processo longo e complexo.
Por que Snowflake?
Nossa decisão de migrar foi baseada no fato de que o Snowflake oferece suporte a esses recursos essenciais por padrão:
- Você pode controlar o poder de computação da consulta planejando o uso do seu armazém’s corretamente. Você pode dividir consultas diferentes em armazéns diferentes com instâncias variadas, concedendo mais recursos onde precisar.
- Você pode agrupar dados nas micro-partições do Snowflake definindo uma chave de cluster e ordenando os dados ao ingestá-los. Também é possível usar auto-clustering para otimizar as micro-partições conforme a chave de cluster. Ao agrupar seus dados de forma inteligente conforme o uso das consultas, você otimiza significativamente suas consultas.
- Deleções são simples no Snowflake, principalmente se forem baseadas na chave de cluster. Atualizar registros específicos ainda é caro, mas muito mais eficiente que no Athena, já que você pode separar o poder de computação e dimensioná-lo conforme necessário.
Etapa de pré-migração: Prova de conceito
Ao planejarmos uma prova de conceito (POC) com o Snowflake, queríamos testar todos os tipos de uso que nosso sistema precisaria. Dividimos a POC em três categorias principais: leituras, gravações e exclusões.
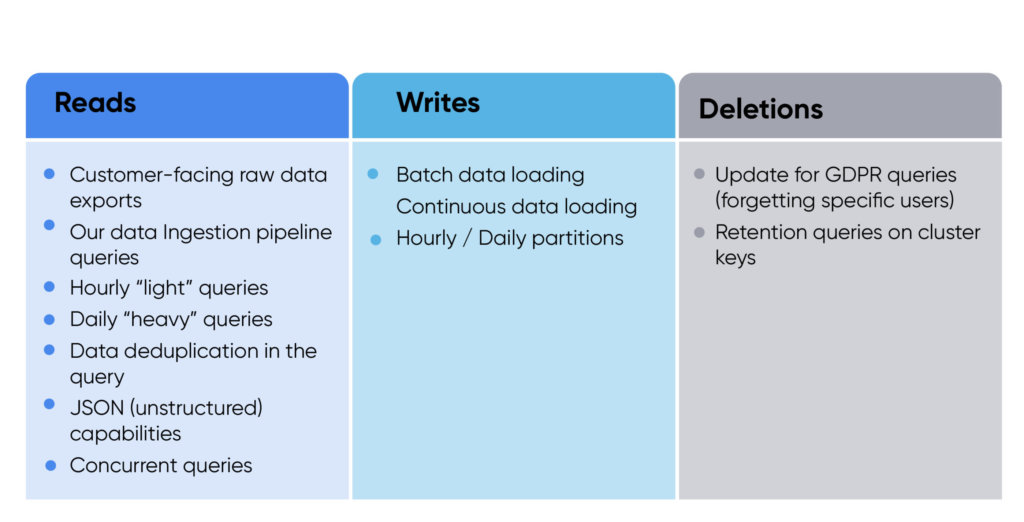
Os requisitos de configuração incluíam um dia de dados de todos os clientes (cerca de 100 TB); tabela multi-inquilino; e indexação (sem chaves de cluster, com uma chave de cluster e com duas chaves de cluster).
Tínhamos quatro critérios de sucesso:
- Carregamento de dados em tempo hábil: Precisávamos que nossa prova de conceito (POC) do pipeline de ingestão de dados comprovasse que seria rápida e barata.
- Suporte para consultas existentes: Precisávamos comprovar que podíamos executar nossas consultas atuais no Snowflake.
- Cumprimento do SLA de consulta: Testamos a duração das consultas e garantimos que a única maneira de melhorá-la seria por meio da migração para o Snowflake.
- Requisitos de custo: Queríamos garantir que executar nossa carga de produção no Snowflake será mais barato que o Athena (isso não é a métrica principal do projeto, mas era importante não aumentar nossos custos).
Nosso teste de conceito (POC) com a Snowflake foi bem-sucedido em todos os aspectos. Além disso, a equipe da Snowflake foi prestativa e atenciosa.
Construindo um Pipeline de Ingestão Robusto
Requisitos
Sabíamos que tínhamos que construir um mecanismo de ingestão do Snowflake que atendesse a todas as seguintes necessidades:
- Robusto e durável. O volume de dados que ingerimos no Snowflake pode aumentar drasticamente em um curto período, portanto, nosso pipeline de ingestão deve ser escalável de acordo. Um aumento drástico no tráfego para um de nossos clientes pode ocorrer repentinamente e pode ser causado por eventos planejados ou não planejados. Uma notícia importante pode causar um aumento repentino na atividade das mídias sociais, por exemplo. Esse tipo de sobrecarga abrupta de tráfego já aconteceu no passado. Portanto, devemos planejar e construir nosso pipeline de ingestão prevendo uma duplicação repentina do nosso volume total de dados. Precisamos ser capazes de escalar facilmente.
- Rápido. O processo de carregamento deve atender a SLAs específicos. Nossos clientes precisam extrair dados de nível de usuário com apenas alguns minutos’ de atraso. Precisamos garantir que o Snowflake não atrase a disponibilidade dos dados além desse limite.
- Alta disponibilidade. Não podemos nos dar ao luxo de ficar fora do ar. Os clientes começam a perceber quando novos dados demoram mais de uma hora para serem disponibilizados.
- Otimizado para o uso mais comum de consultas. Estamos consultando o Snowflake mais de 4.000 vezes por hora para manter nossos relatórios agregados atualizados. Para garantir planos de consulta otimizados, precisamos assegurar que a ordenação e o agrupamento dos dados estejam o mais preparados possível para esse cenário de uso.
- Conforme todos os requisitos de privacidade, como retenção de dados e segregação em repouso. Alguns parceiros exigem regras de retenção diferentes nos dados de nível de usuário. Alguns parceiros precisam segregar totalmente os dados de marketing de nível de usuário em repouso. Tivemos que suportar esses recursos relacionados à privacidade. No Athena, lidamos com isso criando arquivos diferentes no S3 (o que diminuiu o tamanho dos arquivos, impactando negativamente o desempenho do Athena). No Snowflake, poderíamos usar outras tabelas para segregar e definir regras de retenção diferentes para cada parceiro, se necessário.
Decidimos construir nosso pipeline de ingestão do Snowflake da forma mais enxuta e auto-recuperável possível.
Projeto
Aqui está uma análise mais detalhada do nosso projeto:
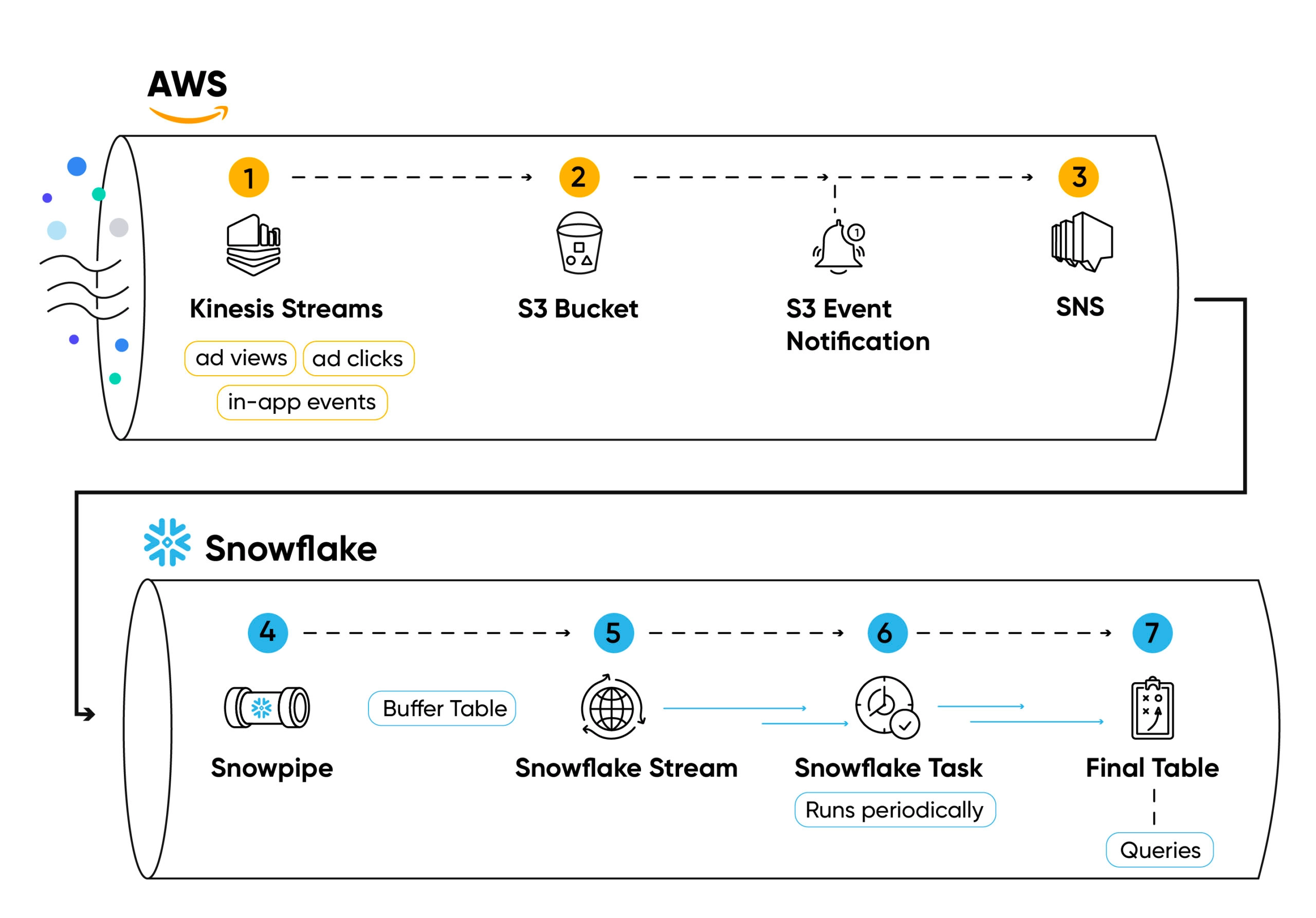
Transmitimos eventos de nível de usuário em fluxos Kinesis da pilha do Singular(1).
Os eventos (como cliques em anúncios, visualizações de anúncios, instalações de aplicativos ou eventos no aplicativo) são lidos do fluxo em lotes, salvos em um arquivo .csv (compactado com zstd) e carregados em arquivos S3 usando workers Python (2) gerenciados pelo Kubernetes.
Cada criação de arquivo cria uma notificação em um tópico SNS (3), assinado pelo Snowpipe (4).
Snowpipe então insere o conteúdo do arquivo’s em uma tabela de buffer (5) a cada arquivo adicionado ao bucket, usando o COPY INTO comando.
Os dados armazenados nas tabelas de buffer não estão agrupados nem ordenados, portanto, utilizá-los para consultas agregadas não será eficiente.
Para garantir que os dados estejam organizados e otimizados para consulta, definimos um fluxo (6) sobre a tabela de buffer.
Em seguida, usamos uma tarefa periódica do Snowflake (7) para consultar o fluxo, classificar os dados e inseri-los em uma tabela final (8).
Serviços Snowflake
Estes são alguns dos principais serviços da Snowflake que utilizamos:
- Snowpipe: Um serviço de fila gerenciado pela Snowflake que copia dados para tabelas Snowflake a partir de fontes externas, como S3. Um tópico SNS pode acionar o Snowpipe, então cada arquivo que você salva em um bucket S3 será copiado para uma tabela no Snowflake. Os custos de computação do Snowpipe’s são fornecidos pela Snowflake e não usam um warehouse definido pelo usuário.
- Fluxos: Um serviço Snowflake que você pode definir em uma tabela no seu banco de dados. Cada vez que você lê o fluxo, it’s lendo os dados da tabela desde a última leitura, para que você possa agir com os dados alterados. It’s um serviço de streaming (como Kafka/Kinesis), mas implementado em uma tabela Snowflake.
- Tarefas: Tarefas periódicas do Snowflake são uma ferramenta excelente para consumir os dados dos streams em outra tabela, se necessário. Estamos usando tarefas do Snowflake como mecanismo de lote para otimizar a profundidade das micro-partições.
Monitoramento, Autocura e Manejo da Retenção
Para garantir que nosso pipeline Snowflake suporte picos repentinos de dados, utilizamos alguns recursos interessantes do Snowflake, além de desenvolver algumas ferramentas internas.
- Armazéns otimizados para ingestão: Dividimos nossas fontes de ingestão “heavy-duty” e “lightweight” em diferentes armazéns, conforme o uso.
- Dimensionamento automático horizontal: Todos os nossos armazéns são multi-cluster e escalam horizontalmente conforme necessário.
- Monitor de falhas de tarefa: Snowflake’s mecanismo de tarefas lida facilmente com falhas esporádicas. Quando as tarefas falham, são simplesmente retiradas do mesmo ponto de verificação onde falharam. Nosso problema era que, a cada execução, a tarefa puxa todos os dados do stream. Se o stream contém muitas linhas, a tarefa pode expirar (ou demorar muito). Atrasos na ingestão por picos de dados seriam caros de gerenciar. Abordamos o problema construindo um monitor interno que lê o Snowflake’s histórico de tarefas e verifica se uma tarefa está demorando demais. Se sim, o monitor a encerra, aumenta o warehouse e a reinicia. Depois, reduz o warehouse ao tamanho original. Este monitor—uma função que não podia ser atendida rapidamente com serviços existentes—foi essencial.
- Retenção de dados: Gerenciamos a retenção de dados de forma eficiente com tarefas periódicas diárias e excluímos dados com mais de x dias (alterações por fonte/cliente de marketing). Snowflake’s DELETE comandos são eficientes e não bloqueantes, especialmente ao executá‑los na chave de cluster (por exemplo, excluindo dias inteiros de dados).
A cada hora, as tarefas do Celery em Python, em nosso pipeline de ingestão, consultam o Snowflake sobre os dados ingeridos.
Balança de manuseio
As diferentes maneiras como usamos o Snowflake no Singular resultam em um padrão de consulta exclusivo:
- Singular’s pipeline de ingestão de dados agregados: Executando consultas de agregação horária nos dados de cada cliente’s.
- Processos ETL voltados ao cliente: Singular’s solução ETL consulta dados brutos a cada hora e os envia para os bancos de dados dos clientes’.
- Exportações manuais voltadas para o cliente: Exportações sob demanda de dados brutos.
- BI interno da Singular.
- Consultas GDPR “esquecer usuários”: Atualizações de linhas específicas, em lotes diários, processam solicitações de esquecimento GDPR.
Executamos milhares de consultas por hora e precisamos que elas sejam concluídas rapidamente em grandes volumes de dados. Além disso, precisamos que o Snowflake atualize linhas específicas com o mínimo impacto possível no agrupamento de dados. Nossos processos de consulta são executados periodicamente de forma distribuída em workers Celery em Python.
Quando começamos a migrar para o Snowflake, presumimos que precisaríamos gerenciar o dimensionamento do warehouse virtual de acordo com o uso e a escala. Com nosso padrão de consulta distribuída, é natural que cada worker consulte o Snowflake diretamente, o que abre uma nova sessão a cada consulta. Isso significa que logo nos deparamos com os limites flexíveis do Snowflake para sessões simultâneas (diferentes das consultas simultâneas, que o Snowflake gerencia praticamente sem limitações).
A boa notícia é que você não precisa se limitar às sessões no Snowflake — você pode executar consultas assíncronas, limitado apenas pelo tamanho da fila do warehouse. Optamos por aproveitar isso e criar um pool de sessões ativas a partir das quais as tarefas podem ser executadas. Planejamos que ele fosse completamente assíncrono e sem estado, de forma que fosse limitado apenas pelo uso do warehouse. Criar um servidor ASGI em Python sem estado para gerenciar nossas conexões foi uma solução bastante simples e elegante para nós.
Implementamos nosso serviço de pool de conexões Python Snowflake usando a integração do SqlAlchemy com o Snowflake, Uvicorn e FastAPI. Planejamos disponibilizá-lo como código aberto e compartilhá-lo com a comunidade em breve, para que outros desenvolvedores de aplicações Snowflake possam economizar tempo e esforço na criação de seus próprios pools de sessões.
Atualmente, utilizando nosso pool de conexões Snowflake, estamos executando mais de 4.000 consultas por hora em diversos warehouses virtuais Snowflake. Os warehouses virtuais escalam horizontalmente de forma automática, se necessário. Nossas atualizações de GDPR estão sendo executadas em um grande warehouse dedicado, o que garante a execução eficiente de consultas UPDATE complexas. O warehouse virtual é suspenso automaticamente quando não há mais solicitações em processamento.
Validação de dados
Os clientes Singular dependem muito dos nossos dados para as suas operações comerciais. Não podíamos tolerar quaisquer discrepâncias de dados durante a migração do Athena para o Snowflake.
Ao executar os dois pipelines de ingestão em paralelo, criamos um monitor contínuo que comparava as consultas no Athena e no Snowflake para cada arquivo carregado no S3. Dessa forma, sabíamos imediatamente se havia problemas na ingestão de dados. Além disso, executamos uma consulta no Snowflake e comparamos os resultados com todas as consultas no Athena que executamos em produção.
A criação desse monitor nos ajudou a validar se a migração de dados estava sendo feita corretamente e sem inconsistências.
Outras lições aprendidas
Após a conclusão da migração, analisamos mais detalhadamente o uso do nosso crédito e a nossa configuração, e encontramos algumas maneiras fáceis de otimizá-los:
- Planeje o uso do warehouse conforme a necessidade. Por exemplo, nossas consultas “pesadas” rodam uma vez ao dia (todas lançadas simultaneamente) em um warehouse de grande escala com auto‑suspensão ativada, enquanto nossas consultas “leves” horárias rodam em um warehouse menor com maior escalonamento horizontal de clusters. Isso garante que o uso diário seja otimizado em custo (consultas pesadas rápidas e suspensas na maior parte do tempo). Nossas consultas horárias têm a elasticidade necessária para sua escala de concorrência.
- Trabalhe com Snowflake para entender os custos dos serviços em nuvem. Descobrimos que nosso padrão de consultas pesadas sobrecarregava o tempo de compilação ao calcular NDV na tabela. Snowflake nos ajudou alterando a configuração de recursos, economizando muito tempo de compilação que nossos tipos de consulta não precisavam para o caso de uso específico (consultando novos clusters apenas em uma tabela altamente atualizada).
- Otimização de consultas: Otimizamos a duração de muitas de nossas consultas usando a ferramenta de perfilamento Snowflake. Isso nos ajudou com consultas complexas, como atualizações do GDPR.
Qual o próximo passo?
- Compartilhamento de dados: Existem oportunidades incríveis de compartilhamento seguro de dados com a Snowflake. Estamos trabalhando com a equipe da Snowflake para aproveitar a ideia de um sala limpa distribuída para compartilhamento seguro de dados.
- Ofuscação de IP: Precisamos implementar retenção de 30 dias nos campos relacionados a IP para manter nosso certificado de selo de segurança. Para isso, criamos um fluxo ágil e eficiente, usando políticas de mascaramento do Snowflake e variáveis de sessão para salvar todos os campos de IP criptografados e descriptografá-los sob demanda. Estamos planejando publicar outro post no blog aprofundando nossa solução.
- Código aberto do pool de conexão: Planejamos abrir o código do nosso pool de conexão Python Snowflake nos próximos meses. Se isso for útil — por exemplo, para executar muitas consultas por hora — entre em contato!
Este blog foi originalmente publicado no blog da Snowflake.

Mantenha-se atualizado sobre os últimos acontecimentos em marketing digital

